 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEDLAM2.0: Synthetic Humans and Cameras in Motion
Nov 18, 2025Inferring 3D human motion from video remains a challenging problem with many applications. While traditional methods estimate the human in image coordinates, many applications require human motion to be estimated in world coordinates. This is particularly challenging when there is both human and camera motion. Progress on this topic has been limited by the lack of rich video data with ground truth human and camera movement. We address this with BEDLAM2.0, a new dataset that goes beyond the popular BEDLAM dataset in important ways. In addition to introducing more diverse and realistic cameras and camera motions, BEDLAM2.0 increases diversity and realism of body shape, motions, clothing, hair, and 3D environments. Additionally, it adds shoes, which were missing in BEDLAM. BEDLAM has become a key resource for training 3D human pose and motion regressors today and we show that BEDLAM2.0 is significantly better, particularly for training methods that estimate humans in world coordinates. We compare state-of-the art methods trained on BEDLAM and BEDLAM2.0, and find that BEDLAM2.0 significantly improves accuracy over BEDLAM. For research purposes, we provide the rendered videos, ground truth body parameters, and camera motions. We also provide the 3D assets to which we have rights and links to those from third parties.
MAMMA: Markerless & Automatic Multi-Person Motion Action Capture
Jun 16, 2025We present MAMMA, a markerless motion-capture pipeline that accurately recovers SMPL-X parameters from multi-view video of two-person interaction sequences. Traditional motion-capture systems rely on physical markers. Although they offer high accuracy, their requirements of specialized hardware, manual marker placement, and extensive post-processing make them costly and time-consuming. Recent learning-based methods attempt to overcome these limitations, but most are designed for single-person capture, rely on sparse keypoints, or struggle with occlusions and physical interactions. In this work, we introduce a method that predicts dense 2D surface landmarks conditioned on segmentation masks, enabling person-specific correspondence estimation even under heavy occlusion. We employ a novel architecture that exploits learnable queries for each landmark. We demonstrate that our approach can handle complex person--person interaction and offers greater accuracy than existing methods. To train our network, we construct a large, synthetic multi-view dataset combining human motions from diverse sources, including extreme poses, hand motions, and close interactions. Our dataset yields high-variability synthetic sequences with rich body contact and occlusion, and includes SMPL-X ground-truth annotations with dense 2D landmarks. The result is a system capable of capturing human motion without the need for markers. Our approach offers competitive reconstruction quality compared to commercial marker-based motion-capture solutions, without the extensive manual cleanup. Finally, we address the absence of common benchmarks for dense-landmark prediction and markerless motion capture by introducing two evaluation settings built from real multi-view sequences. We will release our dataset, benchmark, method, training code, and pre-trained model weights for research purposes.
BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion
Jun 29, 2023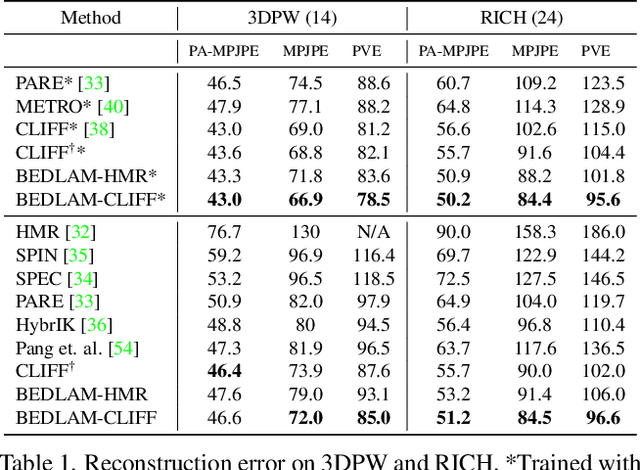

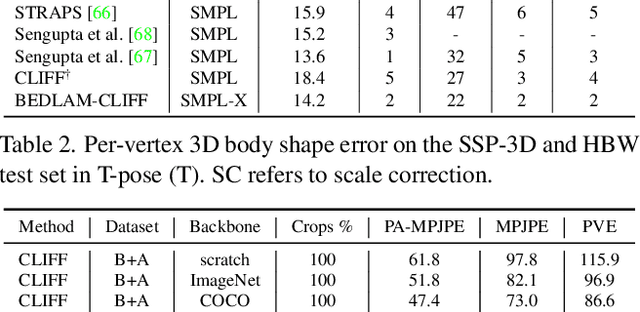

We show, for the first time, that neural networks trained only on synthetic data achieve state-of-the-art accuracy on the problem of 3D human pose and shape (HPS) estimation from real images. Previous synthetic datasets have been small, unrealistic, or lacked realistic clothing. Achieving sufficient realism is non-trivial and we show how to do this for full bodies in motion. Specifically, our BEDLAM dataset contains monocular RGB videos with ground-truth 3D bodies in SMPL-X format. It includes a diversity of body shapes, motions, skin tones, hair, and clothing. The clothing is realistically simulated on the moving bodies using commercial clothing physics simulation. We render varying numbers of people in realistic scenes with varied lighting and camera motions. We then train various HPS regressors using BEDLAM and achieve state-of-the-art accuracy on real-image benchmarks despite training with synthetic data. We use BEDLAM to gain insights into what model design choices are important for accuracy. With good synthetic training data, we find that a basic method like HMR approaches the accuracy of the current SOTA method (CLIFF). BEDLAM is useful for a variety of tasks and all images, ground truth bodies, 3D clothing, support code, and more are available for research purposes. Additionally, we provide detailed information about our synthetic data generation pipeline, enabling others to generate their own datasets. See the project page: https://bedlam.is.tue.mpg.de/.
Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation
May 08, 2022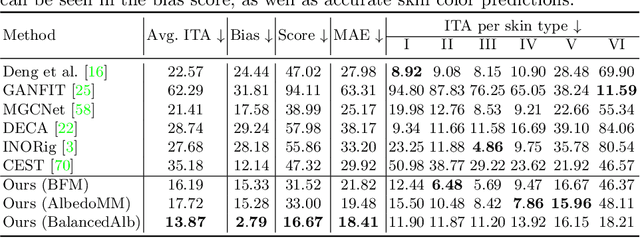
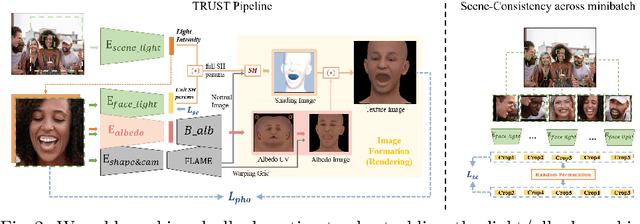
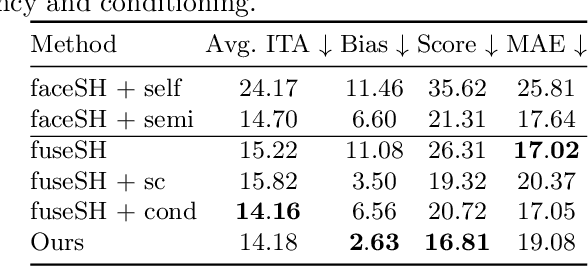

Virtual facial avatars will play an increasingly important role in immersive communication, games and the metaverse, and it is therefore critical that they be inclusive. This requires accurate recovery of the appearance, represented by albedo, regardless of age, sex, or ethnicity. While significant progress has been made on estimating 3D facial geometry, albedo estimation has received less attention. The task is fundamentally ambiguous because the observed color is a function of albedo and lighting, both of which are unknown. We find that current methods are biased towards light skin tones due to (1) strongly biased priors that prefer lighter pigmentation and (2) algorithmic solutions that disregard the light/albedo ambiguity. To address this, we propose a new evaluation dataset (FAIR) and an algorithm (TRUST) to improve albedo estimation and, hence, fairness. Specifically, we create the first facial albedo evaluation benchmark where subjects are balanced in terms of skin color, and measure accuracy using the Individual Typology Angle (ITA) metric. We then address the light/albedo ambiguity by building on a key observation: the image of the full scene -- as opposed to a cropped image of the face -- contains important information about lighting that can be used for disambiguation. TRUST regresses facial albedo by conditioning both on the face region and a global illumination signal obtained from the scene image. Our experimental results show significant improvement compared to state-of-the-art methods on albedo estimation, both in terms of accuracy and fairness. The evaluation benchmark and code will be made available for research purposes at https://trust.is.tue.mpg.de.
SPEC: Seeing People in the Wild with an Estimated Camera
Oct 01, 2021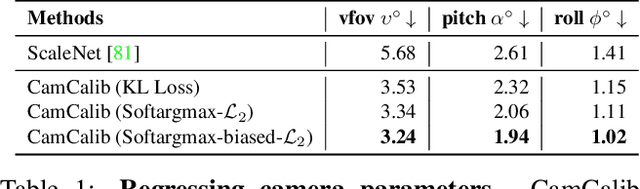
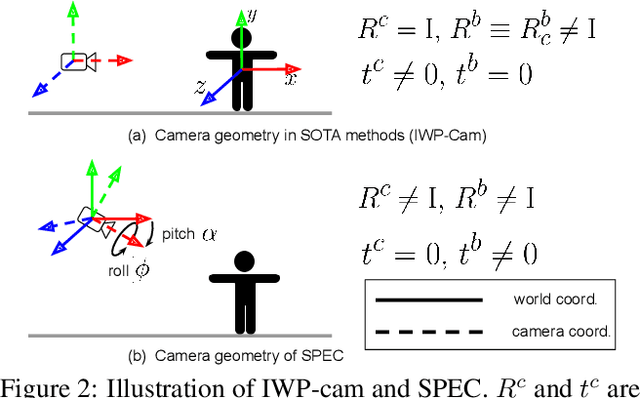
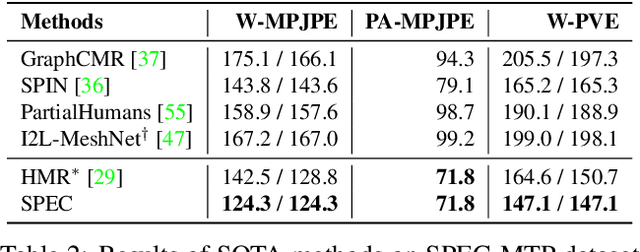
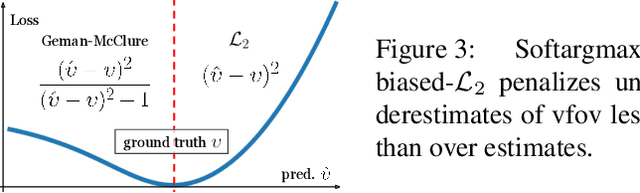
Due to the lack of camera parameter information for in-the-wild images, existing 3D human pose and shape (HPS) estimation methods make several simplifying assumptions: weak-perspective projection, large constant focal length, and zero camera rotation. These assumptions often do not hold and we show, quantitatively and qualitatively, that they cause errors in the reconstructed 3D shape and pose. To address this, we introduce SPEC, the first in-the-wild 3D HPS method that estimates the perspective camera from a single image and employs this to reconstruct 3D human bodies more accurately. %regress 3D human bodies. First, we train a neural network to estimate the field of view, camera pitch, and roll given an input image. We employ novel losses that improve the calibration accuracy over previous work. We then train a novel network that concatenates the camera calibration to the image features and uses these together to regress 3D body shape and pose. SPEC is more accurate than the prior art on the standard benchmark (3DPW) as well as two new datasets with more challenging camera views and varying focal lengths. Specifically, we create a new photorealistic synthetic dataset (SPEC-SYN) with ground truth 3D bodies and a novel in-the-wild dataset (SPEC-MTP) with calibration and high-quality reference bodies. Both qualitative and quantitative analysis confirm that knowing camera parameters during inference regresses better human bodies. Code and datasets are available for research purposes at https://spec.is.tue.mpg.de.
AGORA: Avatars in Geography Optimized for Regression Analysis
Apr 29, 2021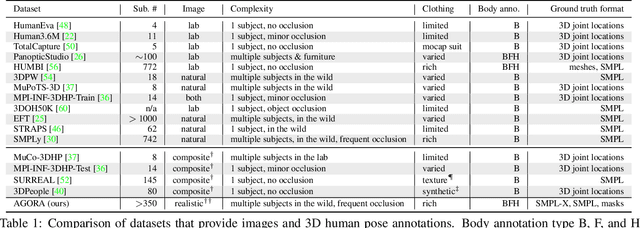
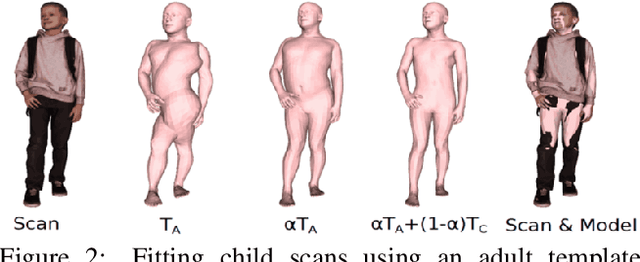
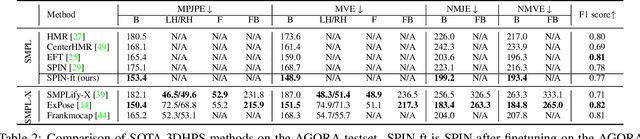
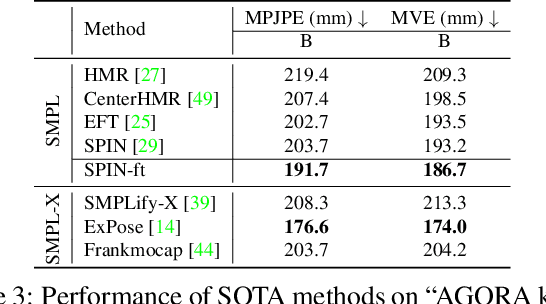
While the accuracy of 3D human pose estimation from images has steadily improved on benchmark datasets, the best methods still fail in many real-world scenarios. This suggests that there is a domain gap between current datasets and common scenes containing people. To obtain ground-truth 3D pose, current datasets limit the complexity of clothing, environmental conditions, number of subjects, and occlusion. Moreover, current datasets evaluate sparse 3D joint locations corresponding to the major joints of the body, ignoring the hand pose and the face shape. To evaluate the current state-of-the-art methods on more challenging images, and to drive the field to address new problems, we introduce AGORA, a synthetic dataset with high realism and highly accurate ground truth. Here we use 4240 commercially-available, high-quality, textured human scans in diverse poses and natural clothing; this includes 257 scans of children. We create reference 3D poses and body shapes by fitting the SMPL-X body model (with face and hands) to the 3D scans, taking into account clothing. We create around 14K training and 3K test images by rendering between 5 and 15 people per image using either image-based lighting or rendered 3D environments, taking care to make the images physically plausible and photoreal. In total, AGORA consists of 173K individual person crops. We evaluate existing state-of-the-art methods for 3D human pose estimation on this dataset and find that most methods perform poorly on images of children. Hence, we extend the SMPL-X model to better capture the shape of children. Additionally, we fine-tune methods on AGORA and show improved performance on both AGORA and 3DPW, confirming the realism of the dataset. We provide all the registered 3D reference training data, rendered images, and a web-based evaluation site at https://agora.is.tue.mpg.de/.
Populating 3D Scenes by Learning Human-Scene Interaction
Dec 21, 2020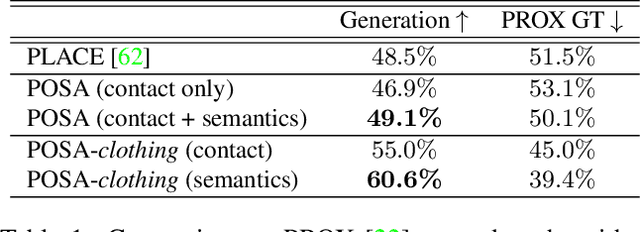
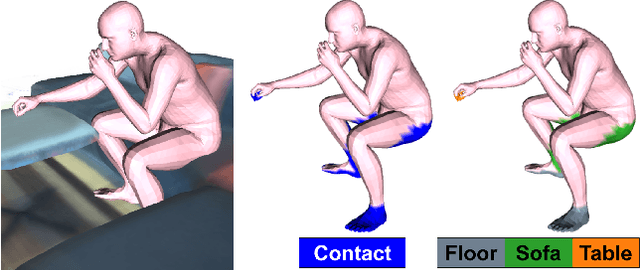


Humans live within a 3D space and constantly interact with it to perform tasks. Such interactions involve physical contact between surfaces that is semantically meaningful. Our goal is to learn how humans interact with scenes and leverage this to enable virtual characters to do the same. To that end, we introduce a novel Human-Scene Interaction (HSI) model that encodes proximal relationships, called POSA for "Pose with prOximitieS and contActs". The representation of interaction is body-centric, which enables it to generalize to new scenes. Specifically, POSA augments the SMPL-X parametric human body model such that, for every mesh vertex, it encodes (a) the contact probability with the scene surface and (b) the corresponding semantic scene label. We learn POSA with a VAE conditioned on the SMPL-X vertices, and train on the PROX dataset, which contains SMPL-X meshes of people interacting with 3D scenes, and the corresponding scene semantics from the PROX-E dataset. We demonstrate the value of POSA with two applications. First, we automatically place 3D scans of people in scenes. We use a SMPL-X model fit to the scan as a proxy and then find its most likely placement in 3D. POSA provides an effective representation to search for "affordances" in the scene that match the likely contact relationships for that pose. We perform a perceptual study that shows significant improvement over the state of the art on this task. Second, we show that POSA's learned representation of body-scene interaction supports monocular human pose estimation that is consistent with a 3D scene, improving on the state of the art. Our model and code will be available for research purposes at https://posa.is.tue.mpg.de.