 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOCO: Benchmarking Semantic Object Correspondence in Vision Foundation Models
Jun 01, 2026Measuring structured object understanding in vision foundation models remains challenging due to inconsistent evaluation protocols and limited part-level supervision. Semantic correspondence (SC) evaluates this capability by testing whether object parts can be matched across instances and categories under large variations in appearance, viewpoint, and geometry. To enable a systematic SC evaluation, we introduce SOCO, a new benchmark for Semantic Object Correspondence that introduces a taxonomy of correspondence types and provides consistent, functionally meaningful keypoint annotations across 100 categories and over 1M correspondence pairs. In addition, SOCO includes keypoint language descriptions, enabling the evaluation of large vision-language models (LVLMs) and their fine-grained part-level understanding. Comprehensive experiments reveal that (i) vision foundation backbones encode strong semantic structure but transfer correspondences poorly across related categories and only partially capture object-part position, (ii) LVLMs are stronger at text-prompted part localization than at visual-reference cross-image matching, exposing a gap between language-grounded localization and fine-grained visual correspondence, and (iii) correspondence performance predicts performance on dense downstream tasks, including segmentation, tracking, 3D pose estimation, and 3D detection, more strongly than ImageNet classification. Together, these findings position SOCO as a benchmark for structured, part-level representation quality in vision and multimodal foundation models.
No Hard Negatives Required: Concept Centric Learning Leads to Compositionality without Degrading Zero-shot Capabilities of Contrastive Models
Mar 26, 2026Contrastive vision-language (V&L) models remain a popular choice for various applications. However, several limitations have emerged, most notably the limited ability of V&L models to learn compositional representations. Prior methods often addressed this limitation by generating custom training data to obtain hard negative samples. Hard negatives have been shown to improve performance on compositionality tasks, but are often specific to a single benchmark, do not generalize, and can cause substantial degradation of basic V&L capabilities such as zero-shot or retrieval performance, rendering them impractical. In this work we follow a different approach. We identify two root causes that limit compositionality performance of V&Ls: 1) Long training captions do not require a compositional representation; and 2) The final global pooling in the text and image encoders lead to a complete loss of the necessary information to learn binding in the first place. As a remedy, we propose two simple solutions: 1) We obtain short concept centric caption parts using standard NLP software and align those with the image; and 2) We introduce a parameter-free cross-modal attention-pooling to obtain concept centric visual embeddings from the image encoder. With these two changes and simple auxiliary contrastive losses, we obtain SOTA performance on standard compositionality benchmarks, while maintaining or improving strong zero-shot and retrieval capabilities. This is achieved without increasing inference cost. We release the code for this work at https://github.com/SamsungLabs/concept_centric_clip.
CLIP Won't Learn Object-Attribute Binding from Natural Data and Here is Why
Jul 10, 2025Contrastive vision-language models like CLIP are used for a large variety of applications, such as zero-shot classification or as vision encoder for multi-modal models. Despite their popularity, their representations show major limitations. For instance, CLIP models learn bag-of-words representations and, as a consequence, fail to distinguish whether an image is of "a yellow submarine and a blue bus" or "a blue submarine and a yellow bus". Previous attempts to fix this issue added hard negatives during training or modified the architecture, but failed to resolve the problem in its entirety. We suspect that the missing insights to solve the binding problem for CLIP are hidden in the arguably most important part of learning algorithms: the data. In this work, we fill this gap by rigorously identifying the influence of data properties on CLIP's ability to learn binding using a synthetic dataset. We find that common properties of natural data such as low attribute density, incomplete captions, and the saliency bias, a tendency of human captioners to describe the object that is "most salient" to them have a detrimental effect on binding performance. In contrast to common belief, we find that neither scaling the batch size, i.e., implicitly adding more hard negatives, nor explicitly creating hard negatives enables CLIP to learn reliable binding. Only when the data expresses our identified data properties CLIP learns almost perfect binding.
Floxels: Fast Unsupervised Voxel Based Scene Flow Estimation
Mar 06, 2025Scene flow estimation is a foundational task for many robotic applications, including robust dynamic object detection, automatic labeling, and sensor synchronization. Two types of approaches to the problem have evolved: 1) Supervised and 2) optimization-based methods. Supervised methods are fast during inference and achieve high-quality results, however, they are limited by the need for large amounts of labeled training data and are susceptible to domain gaps. In contrast, unsupervised test-time optimization methods do not face the problem of domain gaps but usually suffer from substantial runtime, exhibit artifacts, or fail to converge to the right solution. In this work, we mitigate several limitations of existing optimization-based methods. To this end, we 1) introduce a simple voxel grid-based model that improves over the standard MLP-based formulation in multiple dimensions and 2) introduce a new multiframe loss formulation. 3) We combine both contributions in our new method, termed Floxels. On the Argoverse 2 benchmark, Floxels is surpassed only by EulerFlow among unsupervised methods while achieving comparable performance at a fraction of the computational cost. Floxels achieves a massive speedup of more than ~60 - 140x over EulerFlow, reducing the runtime from a day to 10 minutes per sequence. Over the faster but low-quality baseline, NSFP, Floxels achieves a speedup of ~14x.
Two Effects, One Trigger: On the Modality Gap, Object Bias, and Information Imbalance in Contrastive Vision-Language Representation Learning
Apr 11, 2024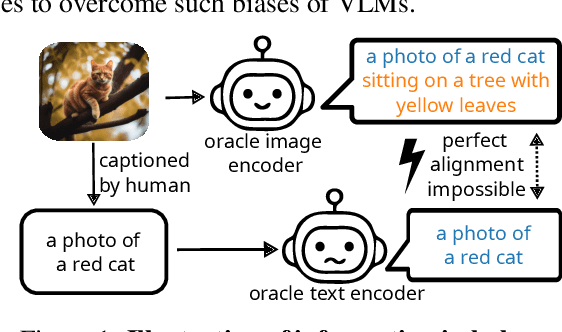



Contrastive vision-language models like CLIP have gained popularity for their versatile applicable learned representations in various downstream tasks. Despite their successes in some tasks, like zero-shot image recognition, they also perform surprisingly poor on other tasks, like attribute detection. Previous work has attributed these challenges to the modality gap, a separation of image and text in the shared representation space, and a bias towards objects over other factors, such as attributes. In this work we investigate both phenomena. We find that only a few embedding dimensions drive the modality gap. Further, we propose a measure for object bias and find that object bias does not lead to worse performance on other concepts, such as attributes. But what leads to the emergence of the modality gap and object bias? To answer this question we carefully designed an experimental setting which allows us to control the amount of shared information between the modalities. This revealed that the driving factor behind both, the modality gap and the object bias, is the information imbalance between images and captions.
Eureka-Moments in Transformers: Multi-Step Tasks Reveal Softmax Induced Optimization Problems
Oct 19, 2023



In this work, we study rapid, step-wise improvements of the loss in transformers when being confronted with multi-step decision tasks. We found that transformers struggle to learn the intermediate tasks, whereas CNNs have no such issue on the tasks we studied. When transformers learn the intermediate task, they do this rapidly and unexpectedly after both training and validation loss saturated for hundreds of epochs. We call these rapid improvements Eureka-moments, since the transformer appears to suddenly learn a previously incomprehensible task. Similar leaps in performance have become known as Grokking. In contrast to Grokking, for Eureka-moments, both the validation and the training loss saturate before rapidly improving. We trace the problem back to the Softmax function in the self-attention block of transformers and show ways to alleviate the problem. These fixes improve training speed. The improved models reach 95% of the baseline model in just 20% of training steps while having a much higher likelihood to learn the intermediate task, lead to higher final accuracy and are more robust to hyper-parameters.
Ranking Info Noise Contrastive Estimation: Boosting Contrastive Learning via Ranked Positives
Jan 27, 2022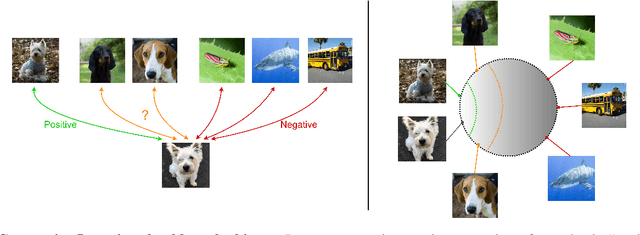

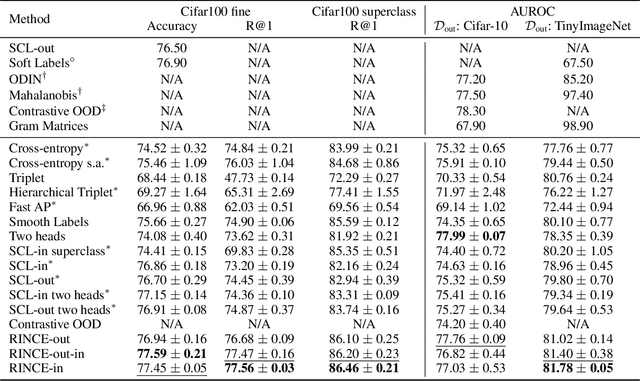
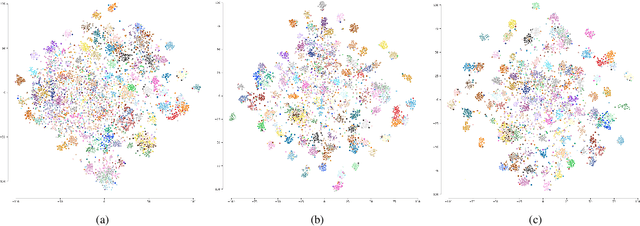
This paper introduces Ranking Info Noise Contrastive Estimation (RINCE), a new member in the family of InfoNCE losses that preserves a ranked ordering of positive samples. In contrast to the standard InfoNCE loss, which requires a strict binary separation of the training pairs into similar and dissimilar samples, RINCE can exploit information about a similarity ranking for learning a corresponding embedding space. We show that the proposed loss function learns favorable embeddings compared to the standard InfoNCE whenever at least noisy ranking information can be obtained or when the definition of positives and negatives is blurry. We demonstrate this for a supervised classification task with additional superclass labels and noisy similarity scores. Furthermore, we show that RINCE can also be applied to unsupervised training with experiments on unsupervised representation learning from videos. In particular, the embedding yields higher classification accuracy, retrieval rates and performs better in out-of-distribution detection than the standard InfoNCE loss.
AGORA: Avatars in Geography Optimized for Regression Analysis
Apr 29, 2021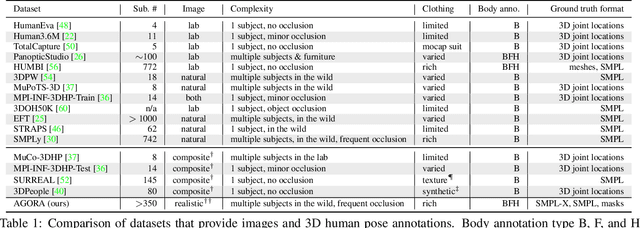
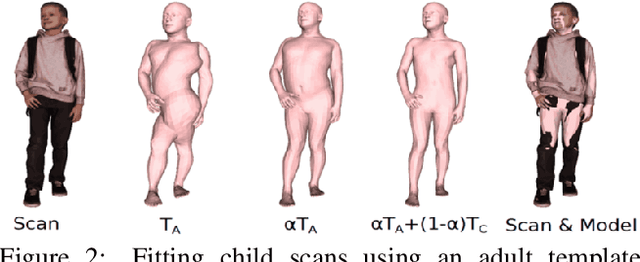
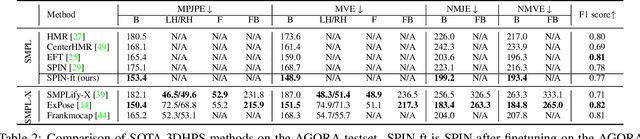
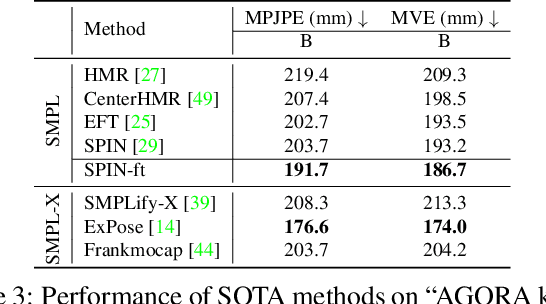
While the accuracy of 3D human pose estimation from images has steadily improved on benchmark datasets, the best methods still fail in many real-world scenarios. This suggests that there is a domain gap between current datasets and common scenes containing people. To obtain ground-truth 3D pose, current datasets limit the complexity of clothing, environmental conditions, number of subjects, and occlusion. Moreover, current datasets evaluate sparse 3D joint locations corresponding to the major joints of the body, ignoring the hand pose and the face shape. To evaluate the current state-of-the-art methods on more challenging images, and to drive the field to address new problems, we introduce AGORA, a synthetic dataset with high realism and highly accurate ground truth. Here we use 4240 commercially-available, high-quality, textured human scans in diverse poses and natural clothing; this includes 257 scans of children. We create reference 3D poses and body shapes by fitting the SMPL-X body model (with face and hands) to the 3D scans, taking into account clothing. We create around 14K training and 3K test images by rendering between 5 and 15 people per image using either image-based lighting or rendered 3D environments, taking care to make the images physically plausible and photoreal. In total, AGORA consists of 173K individual person crops. We evaluate existing state-of-the-art methods for 3D human pose estimation on this dataset and find that most methods perform poorly on images of children. Hence, we extend the SMPL-X model to better capture the shape of children. Additionally, we fine-tune methods on AGORA and show improved performance on both AGORA and 3DPW, confirming the realism of the dataset. We provide all the registered 3D reference training data, rendered images, and a web-based evaluation site at https://agora.is.tue.mpg.de/.
Learning Multi-Human Optical Flow
Oct 24, 2019
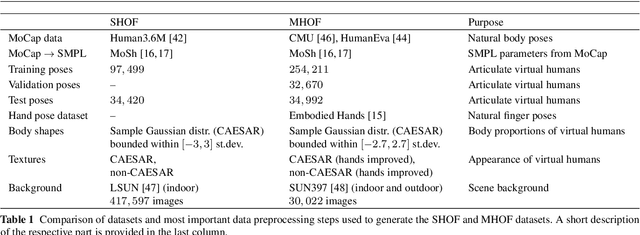
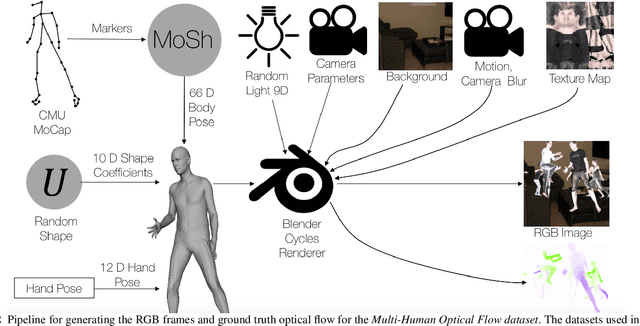
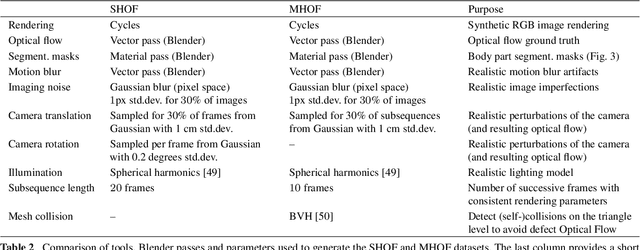
The optical flow of humans is well known to be useful for the analysis of human action. Recent optical flow methods focus on training deep networks to approach the problem. However, the training data used by them does not cover the domain of human motion. Therefore, we develop a dataset of multi-human optical flow and train optical flow networks on this dataset. We use a 3D model of the human body and motion capture data to synthesize realistic flow fields in both single- and multi-person images. We then train optical flow networks to estimate human flow fields from pairs of images. We demonstrate that our trained networks are more accurate than a wide range of top methods on held-out test data and that they can generalize well to real image sequences. The code, trained models and the dataset are available for research.
Learning to Train with Synthetic Humans
Aug 02, 2019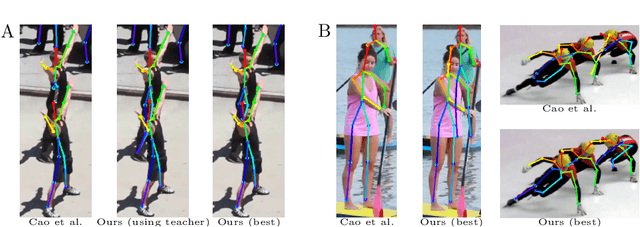


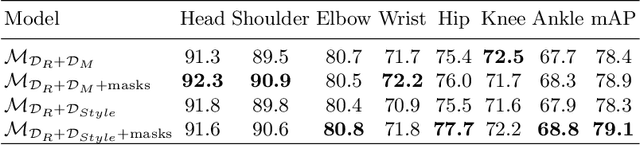
Neural networks need big annotated datasets for training. However, manual annotation can be too expensive or even unfeasible for certain tasks, like multi-person 2D pose estimation with severe occlusions. A remedy for this is synthetic data with perfect ground truth. Here we explore two variations of synthetic data for this challenging problem; a dataset with purely synthetic humans and a real dataset augmented with synthetic humans. We then study which approach better generalizes to real data, as well as the influence of virtual humans in the training loss. Using the augmented dataset, without considering synthetic humans in the loss, leads to the best results. We observe that not all synthetic samples are equally informative for training, while the informative samples are different for each training stage. To exploit this observation, we employ an adversarial student-teacher framework; the teacher improves the student by providing the hardest samples for its current state as a challenge. Experiments show that the student-teacher framework outperforms normal training on the purely synthetic dataset.