 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Train with Synthetic Humans
Paper and Code
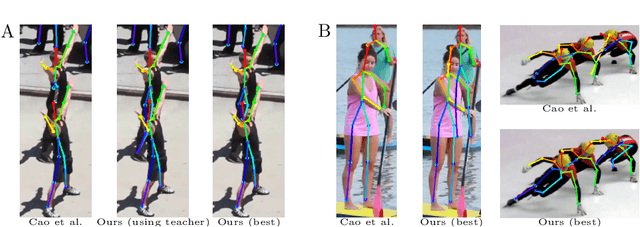


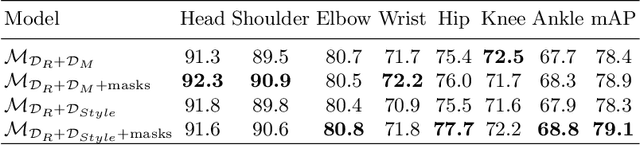
Neural networks need big annotated datasets for training. However, manual annotation can be too expensive or even unfeasible for certain tasks, like multi-person 2D pose estimation with severe occlusions. A remedy for this is synthetic data with perfect ground truth. Here we explore two variations of synthetic data for this challenging problem; a dataset with purely synthetic humans and a real dataset augmented with synthetic humans. We then study which approach better generalizes to real data, as well as the influence of virtual humans in the training loss. Using the augmented dataset, without considering synthetic humans in the loss, leads to the best results. We observe that not all synthetic samples are equally informative for training, while the informative samples are different for each training stage. To exploit this observation, we employ an adversarial student-teacher framework; the teacher improves the student by providing the hardest samples for its current state as a challenge. Experiments show that the student-teacher framework outperforms normal training on the purely synthetic dataset.