 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEXIS: LatEnt ProXimal Interaction Signatures for 3D HOI from an Image
Apr 22, 2026Reconstructing 3D Human-Object Interaction from an RGB image is essential for perceptive systems. Yet, this remains challenging as it requires capturing the subtle physical coupling between the body and objects. While current methods rely on sparse, binary contact cues, these fail to model the continuous proximity and dense spatial relationships that characterize natural interactions. We address this limitation via InterFields, a representation that encodes dense, continuous proximity across the entire body and object surfaces. However, inferring these fields from single images is inherently ill-posed. To tackle this, our intuition is that interaction patterns are characteristically structured by the action and object geometry. We capture this structure in LEXIS, a novel discrete manifold of interaction signatures learned via a VQ-VAE. We then develop LEXIS-Flow, a diffusion framework that leverages LEXIS signatures to estimate human and object meshes alongside their InterFields. Notably, these InterFields help in a guided refinement that ensures physically-plausible, proximity-aware reconstructions without requiring post-hoc optimization. Evaluation on Open3DHOI and BEHAVE shows that LEXIS-Flow significantly outperforms existing SotA baselines in reconstruction, contact, and proximity quality. Our approach not only improves generalization but also yields reconstructions perceived as more realistic, moving us closer to holistic 3D scene understanding. Code & models will be public at https://anticdimi.github.io/lexis.
PICO: Reconstructing 3D People In Contact with Objects
Apr 24, 2025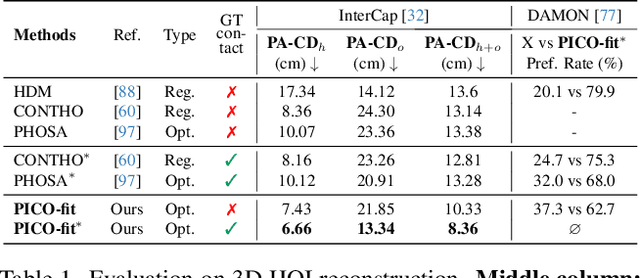


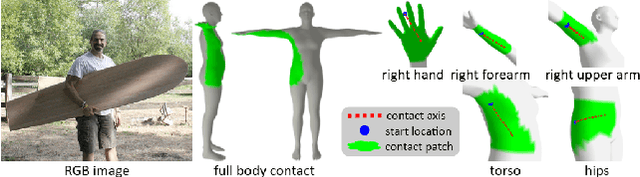
Recovering 3D Human-Object Interaction (HOI) from single color images is challenging due to depth ambiguities, occlusions, and the huge variation in object shape and appearance. Thus, past work requires controlled settings such as known object shapes and contacts, and tackles only limited object classes. Instead, we need methods that generalize to natural images and novel object classes. We tackle this in two main ways: (1) We collect PICO-db, a new dataset of natural images uniquely paired with dense 3D contact on both body and object meshes. To this end, we use images from the recent DAMON dataset that are paired with contacts, but these contacts are only annotated on a canonical 3D body. In contrast, we seek contact labels on both the body and the object. To infer these given an image, we retrieve an appropriate 3D object mesh from a database by leveraging vision foundation models. Then, we project DAMON's body contact patches onto the object via a novel method needing only 2 clicks per patch. This minimal human input establishes rich contact correspondences between bodies and objects. (2) We exploit our new dataset of contact correspondences in a novel render-and-compare fitting method, called PICO-fit, to recover 3D body and object meshes in interaction. PICO-fit infers contact for the SMPL-X body, retrieves a likely 3D object mesh and contact from PICO-db for that object, and uses the contact to iteratively fit the 3D body and object meshes to image evidence via optimization. Uniquely, PICO-fit works well for many object categories that no existing method can tackle. This is crucial to enable HOI understanding to scale in the wild. Our data and code are available at https://pico.is.tue.mpg.de.
InteractVLM: 3D Interaction Reasoning from 2D Foundational Models
Apr 07, 2025We introduce InteractVLM, a novel method to estimate 3D contact points on human bodies and objects from single in-the-wild images, enabling accurate human-object joint reconstruction in 3D. This is challenging due to occlusions, depth ambiguities, and widely varying object shapes. Existing methods rely on 3D contact annotations collected via expensive motion-capture systems or tedious manual labeling, limiting scalability and generalization. To overcome this, InteractVLM harnesses the broad visual knowledge of large Vision-Language Models (VLMs), fine-tuned with limited 3D contact data. However, directly applying these models is non-trivial, as they reason only in 2D, while human-object contact is inherently 3D. Thus we introduce a novel Render-Localize-Lift module that: (1) embeds 3D body and object surfaces in 2D space via multi-view rendering, (2) trains a novel multi-view localization model (MV-Loc) to infer contacts in 2D, and (3) lifts these to 3D. Additionally, we propose a new task called Semantic Human Contact estimation, where human contact predictions are conditioned explicitly on object semantics, enabling richer interaction modeling. InteractVLM outperforms existing work on contact estimation and also facilitates 3D reconstruction from an in-the wild image. Code and models are available at https://interactvlm.is.tue.mpg.de.
InterDyn: Controllable Interactive Dynamics with Video Diffusion Models
Dec 16, 2024



Predicting the dynamics of interacting objects is essential for both humans and intelligent systems. However, existing approaches are limited to simplified, toy settings and lack generalizability to complex, real-world environments. Recent advances in generative models have enabled the prediction of state transitions based on interventions, but focus on generating a single future state which neglects the continuous motion and subsequent dynamics resulting from the interaction. To address this gap, we propose InterDyn, a novel framework that generates videos of interactive dynamics given an initial frame and a control signal encoding the motion of a driving object or actor. Our key insight is that large video foundation models can act as both neural renderers and implicit physics simulators by learning interactive dynamics from large-scale video data. To effectively harness this capability, we introduce an interactive control mechanism that conditions the video generation process on the motion of the driving entity. Qualitative results demonstrate that InterDyn generates plausible, temporally consistent videos of complex object interactions while generalizing to unseen objects. Quantitative evaluations show that InterDyn outperforms baselines that focus on static state transitions. This work highlights the potential of leveraging video generative models as implicit physics engines.
SDFit: 3D Object Pose and Shape by Fitting a Morphable SDF to a Single Image
Sep 24, 2024
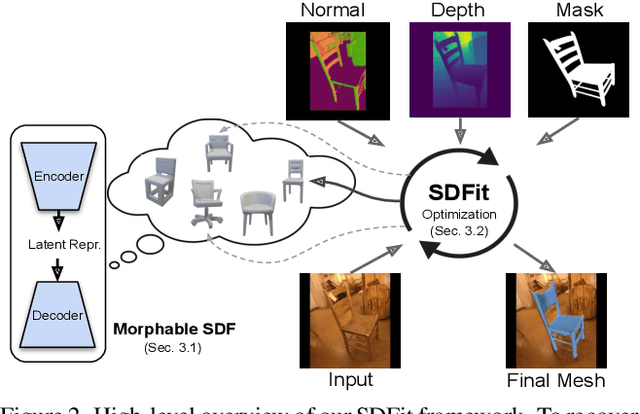


We focus on recovering 3D object pose and shape from single images. This is highly challenging due to strong (self-)occlusions, depth ambiguities, the enormous shape variance, and lack of 3D ground truth for natural images. Recent work relies mostly on learning from finite datasets, so it struggles generalizing, while it focuses mostly on the shape itself, largely ignoring the alignment with pixels. Moreover, it performs feed-forward inference, so it cannot refine estimates. We tackle these limitations with a novel framework, called SDFit. To this end, we make three key observations: (1) Learned signed-distance-function (SDF) models act as a strong morphable shape prior. (2) Foundational models embed 2D images and 3D shapes in a joint space, and (3) also infer rich features from images. SDFit exploits these as follows. First, it uses a category-level morphable SDF (mSDF) model, called DIT, to generate 3D shape hypotheses. This mSDF is initialized by querying OpenShape's latent space conditioned on the input image. Then, it computes 2D-to-3D correspondences, by extracting and matching features from the image and mSDF. Last, it fits the mSDF to the image in an render-and-compare fashion, to iteratively refine estimates. We evaluate SDFit on the Pix3D and Pascal3D+ datasets of real-world images. SDFit performs roughly on par with state-of-the-art learned methods, but, uniquely, requires no re-training. Thus, SDFit is promising for generalizing in the wild, paving the way for future research. Code will be released
3D Whole-body Grasp Synthesis with Directional Controllability
Aug 29, 2024Synthesizing 3D whole-bodies that realistically grasp objects is useful for animation, mixed reality, and robotics. This is challenging, because the hands and body need to look natural w.r.t. each other, the grasped object, as well as the local scene (i.e., a receptacle supporting the object). Only recent work tackles this, with a divide-and-conquer approach; it first generates a "guiding" right-hand grasp, and then searches for bodies that match this. However, the guiding-hand synthesis lacks controllability and receptacle awareness, so it likely has an implausible direction (i.e., a body can't match this without penetrating the receptacle) and needs corrections through major post-processing. Moreover, the body search needs exhaustive sampling and is expensive. These are strong limitations. We tackle these with a novel method called CWGrasp. Our key idea is that performing geometry-based reasoning "early on," instead of "too late," provides rich "control" signals for inference. To this end, CWGrasp first samples a plausible reaching-direction vector (used later for both the arm and hand) from a probabilistic model built via raycasting from the object and collision checking. Then, it generates a reaching body with a desired arm direction, as well as a "guiding" grasping hand with a desired palm direction that complies with the arm's one. Eventually, CWGrasp refines the body to match the "guiding" hand, while plausibly contacting the scene. Notably, generating already-compatible "parts" greatly simplifies the "whole." Moreover, CWGrasp uniquely tackles both right- and left-hand grasps. We evaluate on the GRAB and ReplicaGrasp datasets. CWGrasp outperforms baselines, at lower runtime and budget, while all components help performance. Code and models will be released.
PuzzleAvatar: Assembling 3D Avatars from Personal Albums
May 23, 2024



Generating personalized 3D avatars is crucial for AR/VR. However, recent text-to-3D methods that generate avatars for celebrities or fictional characters, struggle with everyday people. Methods for faithful reconstruction typically require full-body images in controlled settings. What if a user could just upload their personal "OOTD" (Outfit Of The Day) photo collection and get a faithful avatar in return? The challenge is that such casual photo collections contain diverse poses, challenging viewpoints, cropped views, and occlusion (albeit with a consistent outfit, accessories and hairstyle). We address this novel "Album2Human" task by developing PuzzleAvatar, a novel model that generates a faithful 3D avatar (in a canonical pose) from a personal OOTD album, while bypassing the challenging estimation of body and camera pose. To this end, we fine-tune a foundational vision-language model (VLM) on such photos, encoding the appearance, identity, garments, hairstyles, and accessories of a person into (separate) learned tokens and instilling these cues into the VLM. In effect, we exploit the learned tokens as "puzzle pieces" from which we assemble a faithful, personalized 3D avatar. Importantly, we can customize avatars by simply inter-changing tokens. As a benchmark for this new task, we collect a new dataset, called PuzzleIOI, with 41 subjects in a total of nearly 1K OOTD configurations, in challenging partial photos with paired ground-truth 3D bodies. Evaluation shows that PuzzleAvatar not only has high reconstruction accuracy, outperforming TeCH and MVDreamBooth, but also a unique scalability to album photos, and strong robustness. Our model and data will be public.
DECO: Dense Estimation of 3D Human-Scene Contact In The Wild
Sep 26, 2023
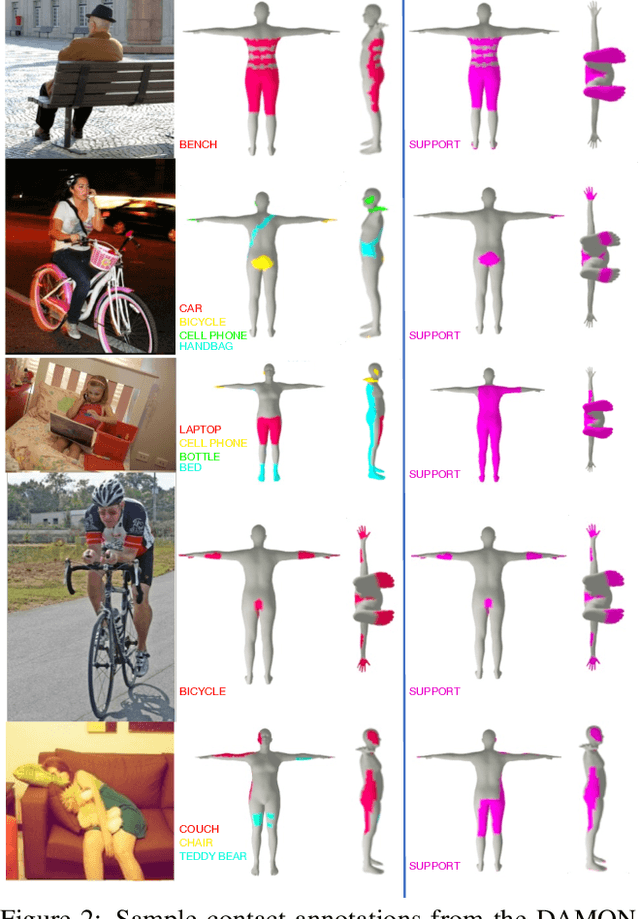
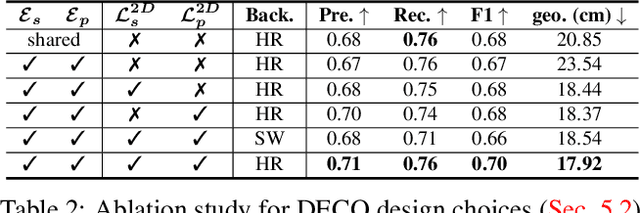
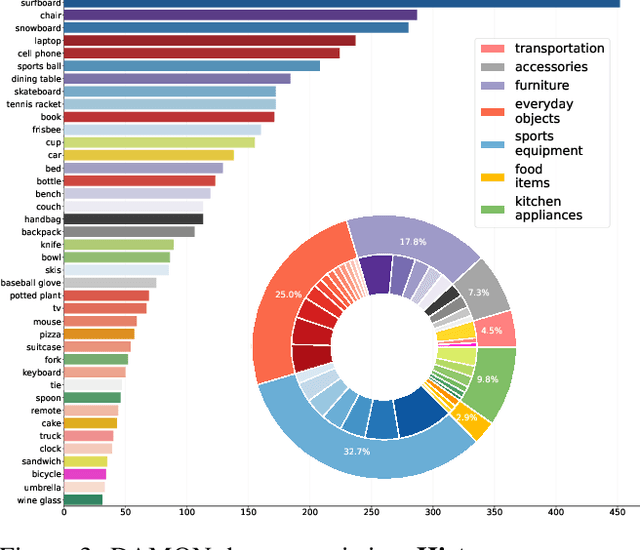
Understanding how humans use physical contact to interact with the world is key to enabling human-centric artificial intelligence. While inferring 3D contact is crucial for modeling realistic and physically-plausible human-object interactions, existing methods either focus on 2D, consider body joints rather than the surface, use coarse 3D body regions, or do not generalize to in-the-wild images. In contrast, we focus on inferring dense, 3D contact between the full body surface and objects in arbitrary images. To achieve this, we first collect DAMON, a new dataset containing dense vertex-level contact annotations paired with RGB images containing complex human-object and human-scene contact. Second, we train DECO, a novel 3D contact detector that uses both body-part-driven and scene-context-driven attention to estimate vertex-level contact on the SMPL body. DECO builds on the insight that human observers recognize contact by reasoning about the contacting body parts, their proximity to scene objects, and the surrounding scene context. We perform extensive evaluations of our detector on DAMON as well as on the RICH and BEHAVE datasets. We significantly outperform existing SOTA methods across all benchmarks. We also show qualitatively that DECO generalizes well to diverse and challenging real-world human interactions in natural images. The code, data, and models are available at https://deco.is.tue.mpg.de.
POCO: 3D Pose and Shape Estimation with Confidence
Aug 24, 2023The regression of 3D Human Pose and Shape (HPS) from an image is becoming increasingly accurate. This makes the results useful for downstream tasks like human action recognition or 3D graphics. Yet, no regressor is perfect, and accuracy can be affected by ambiguous image evidence or by poses and appearance that are unseen during training. Most current HPS regressors, however, do not report the confidence of their outputs, meaning that downstream tasks cannot differentiate accurate estimates from inaccurate ones. To address this, we develop POCO, a novel framework for training HPS regressors to estimate not only a 3D human body, but also their confidence, in a single feed-forward pass. Specifically, POCO estimates both the 3D body pose and a per-sample variance. The key idea is to introduce a Dual Conditioning Strategy (DCS) for regressing uncertainty that is highly correlated to pose reconstruction quality. The POCO framework can be applied to any HPS regressor and here we evaluate it by modifying HMR, PARE, and CLIFF. In all cases, training the network to reason about uncertainty helps it learn to more accurately estimate 3D pose. While this was not our goal, the improvement is modest but consistent. Our main motivation is to provide uncertainty estimates for downstream tasks; we demonstrate this in two ways: (1) We use the confidence estimates to bootstrap HPS training. Given unlabelled image data, we take the confident estimates of a POCO-trained regressor as pseudo ground truth. Retraining with this automatically-curated data improves accuracy. (2) We exploit uncertainty in video pose estimation by automatically identifying uncertain frames (e.g. due to occlusion) and inpainting these from confident frames. Code and models will be available for research at https://poco.is.tue.mpg.de.
GRIP: Generating Interaction Poses Using Latent Consistency and Spatial Cues
Aug 22, 2023Hands are dexterous and highly versatile manipulators that are central to how humans interact with objects and their environment. Consequently, modeling realistic hand-object interactions, including the subtle motion of individual fingers, is critical for applications in computer graphics, computer vision, and mixed reality. Prior work on capturing and modeling humans interacting with objects in 3D focuses on the body and object motion, often ignoring hand pose. In contrast, we introduce GRIP, a learning-based method that takes, as input, the 3D motion of the body and the object, and synthesizes realistic motion for both hands before, during, and after object interaction. As a preliminary step before synthesizing the hand motion, we first use a network, ANet, to denoise the arm motion. Then, we leverage the spatio-temporal relationship between the body and the object to extract two types of novel temporal interaction cues, and use them in a two-stage inference pipeline to generate the hand motion. In the first stage, we introduce a new approach to enforce motion temporal consistency in the latent space (LTC), and generate consistent interaction motions. In the second stage, GRIP generates refined hand poses to avoid hand-object penetrations. Given sequences of noisy body and object motion, GRIP upgrades them to include hand-object interaction. Quantitative experiments and perceptual studies demonstrate that GRIP outperforms baseline methods and generalizes to unseen objects and motions from different motion-capture datasets.