 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceTimePilot: Generative Rendering of Dynamic Scenes Across Space and Time
Dec 31, 2025We present SpaceTimePilot, a video diffusion model that disentangles space and time for controllable generative rendering. Given a monocular video, SpaceTimePilot can independently alter the camera viewpoint and the motion sequence within the generative process, re-rendering the scene for continuous and arbitrary exploration across space and time. To achieve this, we introduce an effective animation time-embedding mechanism in the diffusion process, allowing explicit control of the output video's motion sequence with respect to that of the source video. As no datasets provide paired videos of the same dynamic scene with continuous temporal variations, we propose a simple yet effective temporal-warping training scheme that repurposes existing multi-view datasets to mimic temporal differences. This strategy effectively supervises the model to learn temporal control and achieve robust space-time disentanglement. To further enhance the precision of dual control, we introduce two additional components: an improved camera-conditioning mechanism that allows altering the camera from the first frame, and CamxTime, the first synthetic space-and-time full-coverage rendering dataset that provides fully free space-time video trajectories within a scene. Joint training on the temporal-warping scheme and the CamxTime dataset yields more precise temporal control. We evaluate SpaceTimePilot on both real-world and synthetic data, demonstrating clear space-time disentanglement and strong results compared to prior work. Project page: https://zheninghuang.github.io/Space-Time-Pilot/ Code: https://github.com/ZheningHuang/spacetimepilot
MatAtlas: Text-driven Consistent Geometry Texturing and Material Assignment
Apr 03, 2024



We present MatAtlas, a method for consistent text-guided 3D model texturing. Following recent progress we leverage a large scale text-to-image generation model (e.g., Stable Diffusion) as a prior to texture a 3D model. We carefully design an RGB texturing pipeline that leverages a grid pattern diffusion, driven by depth and edges. By proposing a multi-step texture refinement process, we significantly improve the quality and 3D consistency of the texturing output. To further address the problem of baked-in lighting, we move beyond RGB colors and pursue assigning parametric materials to the assets. Given the high-quality initial RGB texture, we propose a novel material retrieval method capitalized on Large Language Models (LLM), enabling editabiliy and relightability. We evaluate our method on a wide variety of geometries and show that our method significantly outperform prior arts. We also analyze the role of each component through a detailed ablation study.
Reconstructing Signing Avatars From Video Using Linguistic Priors
Apr 20, 2023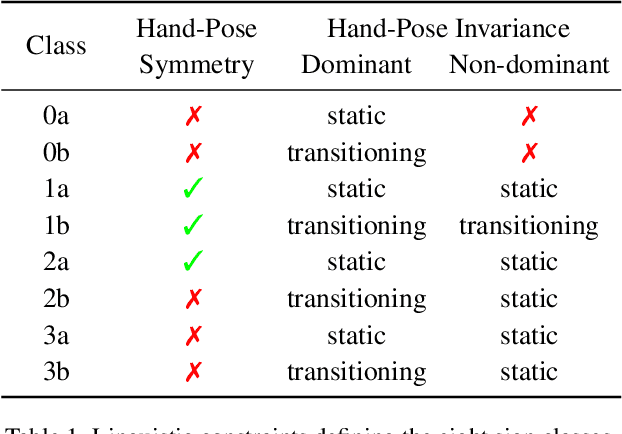
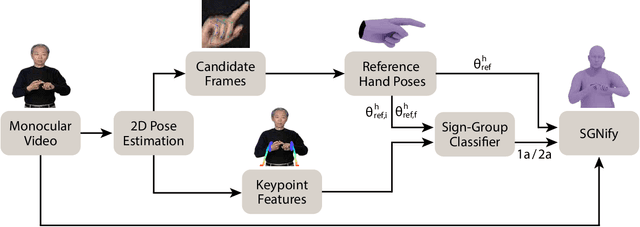
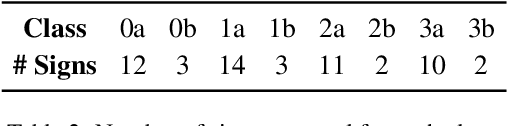

Sign language (SL) is the primary method of communication for the 70 million Deaf people around the world. Video dictionaries of isolated signs are a core SL learning tool. Replacing these with 3D avatars can aid learning and enable AR/VR applications, improving access to technology and online media. However, little work has attempted to estimate expressive 3D avatars from SL video; occlusion, noise, and motion blur make this task difficult. We address this by introducing novel linguistic priors that are universally applicable to SL and provide constraints on 3D hand pose that help resolve ambiguities within isolated signs. Our method, SGNify, captures fine-grained hand pose, facial expression, and body movement fully automatically from in-the-wild monocular SL videos. We evaluate SGNify quantitatively by using a commercial motion-capture system to compute 3D avatars synchronized with monocular video. SGNify outperforms state-of-the-art 3D body-pose- and shape-estimation methods on SL videos. A perceptual study shows that SGNify's 3D reconstructions are significantly more comprehensible and natural than those of previous methods and are on par with the source videos. Code and data are available at $\href{http://sgnify.is.tue.mpg.de}{\text{sgnify.is.tue.mpg.de}}$.