 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Through Clutter: Structured 3D Scene Reconstruction via Iterative Object Removal
Feb 03, 2026We present SeeingThroughClutter, a method for reconstructing structured 3D representations from single images by segmenting and modeling objects individually. Prior approaches rely on intermediate tasks such as semantic segmentation and depth estimation, which often underperform in complex scenes, particularly in the presence of occlusion and clutter. We address this by introducing an iterative object removal and reconstruction pipeline that decomposes complex scenes into a sequence of simpler subtasks. Using VLMs as orchestrators, foreground objects are removed one at a time via detection, segmentation, object removal, and 3D fitting. We show that removing objects allows for cleaner segmentations of subsequent objects, even in highly occluded scenes. Our method requires no task-specific training and benefits directly from ongoing advances in foundation models. We demonstrate stateof-the-art robustness on 3D-Front and ADE20K datasets. Project Page: https://rioak.github.io/seeingthroughclutter/
Residual Primitive Fitting of 3D Shapes with SuperFrusta
Dec 09, 2025We introduce a framework for converting 3D shapes into compact and editable assemblies of analytic primitives, directly addressing the persistent trade-off between reconstruction fidelity and parsimony. Our approach combines two key contributions: a novel primitive, termed SuperFrustum, and an iterative fiting algorithm, Residual Primitive Fitting (ResFit). SuperFrustum is an analytical primitive that is simultaneously (1) expressive, being able to model various common solids such as cylinders, spheres, cones & their tapered and bent forms, (2) editable, being compactly parameterized with 8 parameters, and (3) optimizable, with a sign distance field differentiable w.r.t. its parameters almost everywhere. ResFit is an unsupervised procedure that interleaves global shape analysis with local optimization, iteratively fitting primitives to the unexplained residual of a shape to discover a parsimonious yet accurate decompositions for each input shape. On diverse 3D benchmarks, our method achieves state-of-the-art results, improving IoU by over 9 points while using nearly half as many primitives as prior work. The resulting assemblies bridge the gap between dense 3D data and human-controllable design, producing high-fidelity and editable shape programs.
Reusing Computation in Text-to-Image Diffusion for Efficient Generation of Image Sets
Aug 28, 2025Text-to-image diffusion models enable high-quality image generation but are computationally expensive. While prior work optimizes per-inference efficiency, we explore an orthogonal approach: reducing redundancy across correlated prompts. Our method leverages the coarse-to-fine nature of diffusion models, where early denoising steps capture shared structures among similar prompts. We propose a training-free approach that clusters prompts based on semantic similarity and shares computation in early diffusion steps. Experiments show that for models trained conditioned on image embeddings, our approach significantly reduces compute cost while improving image quality. By leveraging UnClip's text-to-image prior, we enhance diffusion step allocation for greater efficiency. Our method seamlessly integrates with existing pipelines, scales with prompt sets, and reduces the environmental and financial burden of large-scale text-to-image generation. Project page: https://ddecatur.github.io/hierarchical-diffusion/
Temporal Residual Jacobians For Rig-free Motion Transfer
Jul 20, 2024We introduce Temporal Residual Jacobians as a novel representation to enable data-driven motion transfer. Our approach does not assume access to any rigging or intermediate shape keyframes, produces geometrically and temporally consistent motions, and can be used to transfer long motion sequences. Central to our approach are two coupled neural networks that individually predict local geometric and temporal changes that are subsequently integrated, spatially and temporally, to produce the final animated meshes. The two networks are jointly trained, complement each other in producing spatial and temporal signals, and are supervised directly with 3D positional information. During inference, in the absence of keyframes, our method essentially solves a motion extrapolation problem. We test our setup on diverse meshes (synthetic and scanned shapes) to demonstrate its superiority in generating realistic and natural-looking animations on unseen body shapes against SoTA alternatives. Supplemental video and code are available at https://temporaljacobians.github.io/ .
MatAtlas: Text-driven Consistent Geometry Texturing and Material Assignment
Apr 03, 2024



We present MatAtlas, a method for consistent text-guided 3D model texturing. Following recent progress we leverage a large scale text-to-image generation model (e.g., Stable Diffusion) as a prior to texture a 3D model. We carefully design an RGB texturing pipeline that leverages a grid pattern diffusion, driven by depth and edges. By proposing a multi-step texture refinement process, we significantly improve the quality and 3D consistency of the texturing output. To further address the problem of baked-in lighting, we move beyond RGB colors and pursue assigning parametric materials to the assets. Given the high-quality initial RGB texture, we propose a novel material retrieval method capitalized on Large Language Models (LLM), enabling editabiliy and relightability. We evaluate our method on a wide variety of geometries and show that our method significantly outperform prior arts. We also analyze the role of each component through a detailed ablation study.
The Shape Part Slot Machine: Contact-based Reasoning for Generating 3D Shapes from Parts
Dec 01, 2021

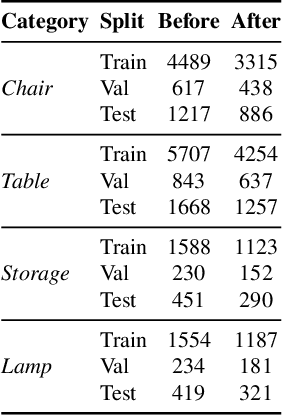

We present the Shape Part Slot Machine, a new method for assembling novel 3D shapes from existing parts by performing contact-based reasoning. Our method represents each shape as a graph of "slots," where each slot is a region of contact between two shape parts. Based on this representation, we design a graph-neural-network-based model for generating new slot graphs and retrieving compatible parts, as well as a gradient-descent-based optimization scheme for assembling the retrieved parts into a complete shape that respects the generated slot graph. This approach does not require any semantic part labels; interestingly, it also does not require complete part geometries -- reasoning about the regions where parts connect proves sufficient to generate novel, high-quality 3D shapes. We demonstrate that our method generates shapes that outperform existing modeling-by-assembly approaches in terms of quality, diversity, and structural complexity.
GLASS: Geometric Latent Augmentation for Shape Spaces
Aug 09, 2021

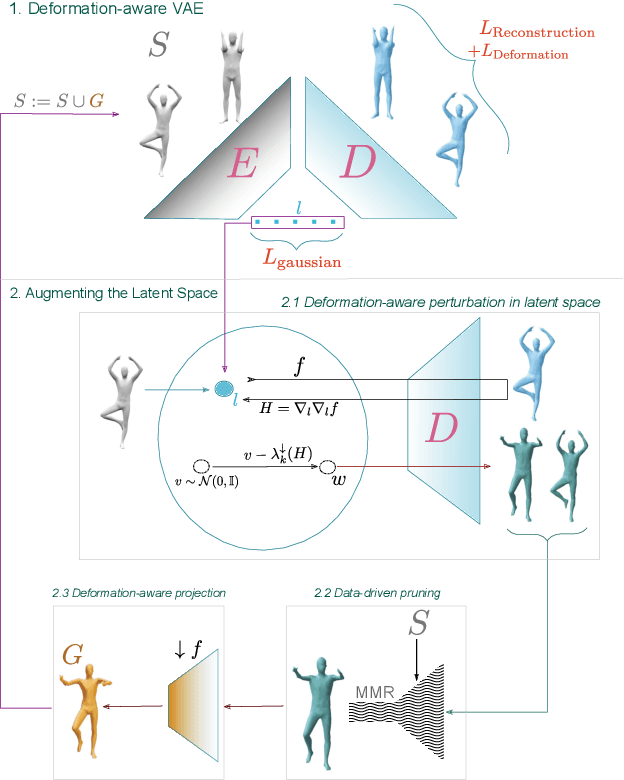

We investigate the problem of training generative models on a very sparse collection of 3D models. We use geometrically motivated energies to augment and thus boost a sparse collection of example (training) models. We analyze the Hessian of the as-rigid-as-possible (ARAP) energy to sample from and project to the underlying (local) shape space, and use the augmented dataset to train a variational autoencoder (VAE). We iterate the process of building latent spaces of VAE and augmenting the associated dataset, to progressively reveal a richer and more expressive generative space for creating geometrically and semantically valid samples. Our framework allows us to train generative 3D models even with a small set of good quality 3D models, which are typically hard to curate. We extensively evaluate our method against a set of strong baselines, provide ablation studies and demonstrate application towards establishing shape correspondences. We present multiple examples of interesting and meaningful shape variations even when starting from as few as 3-10 training shapes.
Neural Surface Maps
Mar 31, 2021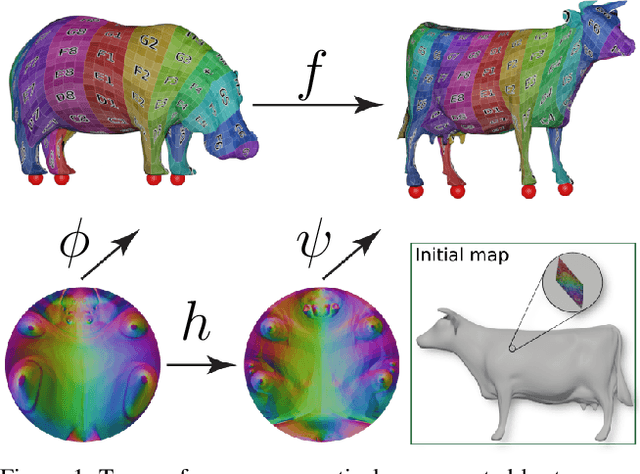

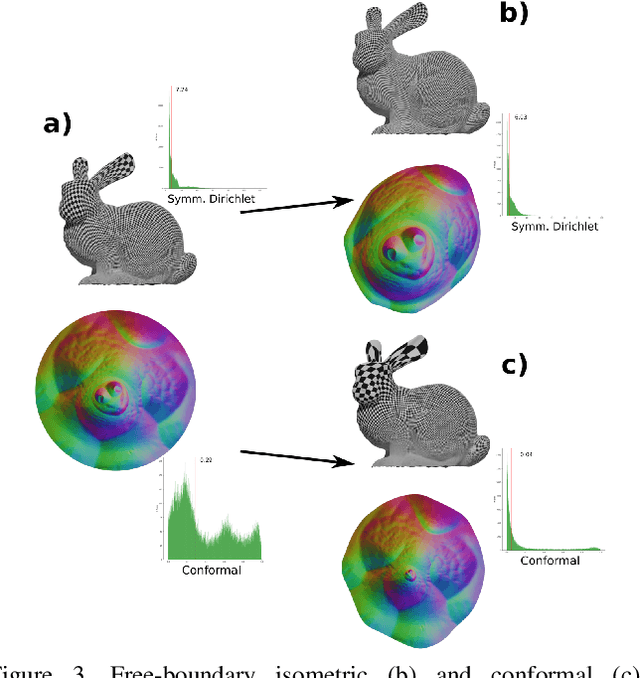

Maps are arguably one of the most fundamental concepts used to define and operate on manifold surfaces in differentiable geometry. Accordingly, in geometry processing, maps are ubiquitous and are used in many core applications, such as paramterization, shape analysis, remeshing, and deformation. Unfortunately, most computational representations of surface maps do not lend themselves to manipulation and optimization, usually entailing hard, discrete problems. While algorithms exist to solve these problems, they are problem-specific, and a general framework for surface maps is still in need. In this paper, we advocate considering neural networks as encoding surface maps. Since neural networks can be composed on one another and are differentiable, we show it is easy to use them to define surfaces via atlases, compose them for surface-to-surface mappings, and optimize differentiable objectives relating to them, such as any notion of distortion, in a trivial manner. In our experiments, we represent surfaces by generating a neural map that approximates a UV parameterization of a 3D model. Then, we compose this map with other neural maps which we optimize with respect to distortion measures. We show that our formulation enables trivial optimization of rather elusive mapping tasks, such as maps between a collection of surfaces.
DECOR-GAN: 3D Shape Detailization by Conditional Refinement
Dec 16, 2020

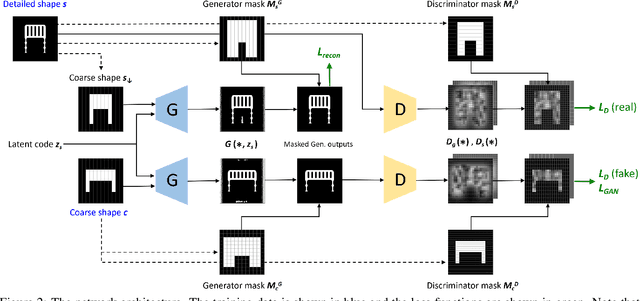

We introduce a deep generative network for 3D shape detailization, akin to stylization with the style being geometric details. We address the challenge of creating large varieties of high-resolution and detailed 3D geometry from a small set of exemplars by treating the problem as that of geometric detail transfer. Given a low-resolution coarse voxel shape, our network refines it, via voxel upsampling, into a higher-resolution shape enriched with geometric details. The output shape preserves the overall structure (or content) of the input, while its detail generation is conditioned on an input "style code" corresponding to a detailed exemplar. Our 3D detailization via conditional refinement is realized by a generative adversarial network, coined DECOR-GAN. The network utilizes a 3D CNN generator for upsampling coarse voxels and a 3D PatchGAN discriminator to enforce local patches of the generated model to be similar to those in the training detailed shapes. During testing, a style code is fed into the generator to condition the refinement. We demonstrate that our method can refine a coarse shape into a variety of detailed shapes with different styles. The generated results are evaluated in terms of content preservation, plausibility, and diversity. Comprehensive ablation studies are conducted to validate our network designs.
COALESCE: Component Assembly by Learning to Synthesize Connections
Aug 05, 2020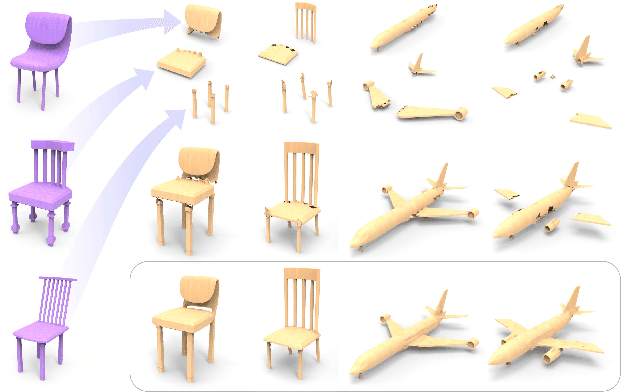
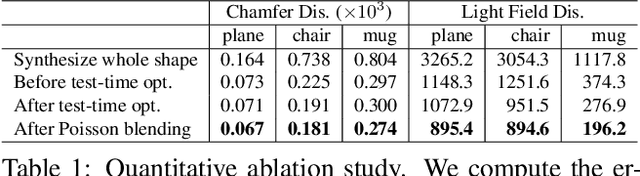
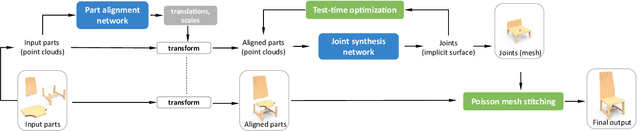
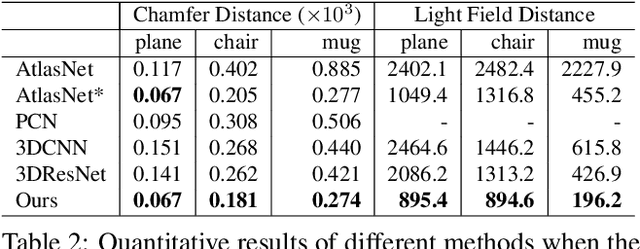
We introduce COALESCE, the first data-driven framework for component-based shape assembly which employs deep learning to synthesize part connections. To handle geometric and topological mismatches between parts, we remove the mismatched portions via erosion, and rely on a joint synthesis step, which is learned from data, to fill the gap and arrive at a natural and plausible part joint. Given a set of input parts extracted from different objects, COALESCE automatically aligns them and synthesizes plausible joints to connect the parts into a coherent 3D object represented by a mesh. The joint synthesis network, designed to focus on joint regions, reconstructs the surface between the parts by predicting an implicit shape representation that agrees with existing parts, while generating a smooth and topologically meaningful connection. We employ test-time optimization to further ensure that the synthesized joint region closely aligns with the input parts to create realistic component assemblies from diverse input parts. We demonstrate that our method significantly outperforms prior approaches including baseline deep models for 3D shape synthesis, as well as state-of-the-art methods for shape completion.