 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViPS: Video-informed Pose Spaces for Auto-Rigged Meshes
Apr 19, 2026Kinematic rigs provide a structured interface for articulating 3D meshes, but they lack an inherent representation of the plausible manifold of joint configurations for a given asset. Without such a pose space, stochastic sampling or manual manipulation of raw rig parameters often leads to semantic or geometric violations, such as anatomical hyperextension and non-physical self-intersections. We propose Video-informed Pose Spaces (ViPS), a feed-forward framework that discovers the latent distribution of valid articulations for auto-rigged meshes by distilling motion priors from a pretrained video diffusion model. Unlike existing methods that rely on scarce artist-authored 4D datasets, ViPS transfers generative video priors into a universal distribution over a given rig parameterization. Differentiable geometric validators applied to the skinned mesh enforce asset-specific validity without requiring manual regularizers. Our model learns a smooth, compact, and controllable pose space that supports diverse sampling, manifold projection for inverse kinematics, and temporally coherent trajectories for keyframing. Furthermore, the distilled 3D pose samples serve as precise semantic proxies for guiding video diffusion, effectively closing the loop between generative 2D priors and structured 3D kinematic control. Our evaluations show that ViPS, trained solely on video priors, matches the performance of state-of-the-art methods trained on synthetic artist-created 4D data in both plausibility and diversity. Most importantly, as a universal model, ViPS demonstrates robust zero-shot generalization to out-of-distribution species and unseen skeletal topologies.
TrajectoryMover: Generative Movement of Object Trajectories in Videos
Mar 31, 2026Generative video editing has enabled several intuitive editing operations for short video clips that would previously have been difficult to achieve, especially for non-expert editors. Existing methods focus on prescribing an object's 3D or 2D motion trajectory in a video, or on altering the appearance of an object or a scene, while preserving both the video's plausibility and identity. Yet a method to move an object's 3D motion trajectory in a video, i.e., moving an object while preserving its relative 3D motion, is currently still missing. The main challenge lies in obtaining paired video data for this scenario. Previous methods typically rely on clever data generation approaches to construct plausible paired data from unpaired videos, but this approach fails if one of the videos in a pair can not easily be constructed from the other. Instead, we introduce TrajectoryAtlas, a new data generation pipeline for large-scale synthetic paired video data and a video generator TrajectoryMover fine-tuned with this data. We show that this successfully enables generative movement of object trajectories. Project page: https://chhatrekiran.github.io/trajectorymover
LoST: Level of Semantics Tokenization for 3D Shapes
Mar 18, 2026Tokenization is a fundamental technique in the generative modeling of various modalities. In particular, it plays a critical role in autoregressive (AR) models, which have recently emerged as a compelling option for 3D generation. However, optimal tokenization of 3D shapes remains an open question. State-of-the-art (SOTA) methods primarily rely on geometric level-of-detail (LoD) hierarchies, originally designed for rendering and compression. These spatial hierarchies are often token-inefficient and lack semantic coherence for AR modeling. We propose Level-of-Semantics Tokenization (LoST), which orders tokens by semantic salience, such that early prefixes decode into complete, plausible shapes that possess principal semantics, while subsequent tokens refine instance-specific geometric and semantic details. To train LoST, we introduce Relational Inter-Distance Alignment (RIDA), a novel 3D semantic alignment loss that aligns the relational structure of the 3D shape latent space with that of the semantic DINO feature space. Experiments show that LoST achieves SOTA reconstruction, surpassing previous LoD-based 3D shape tokenizers by large margins on both geometric and semantic reconstruction metrics. Moreover, LoST achieves efficient, high-quality AR 3D generation and enables downstream tasks like semantic retrieval, while using only 0.1%-10% of the tokens needed by prior AR models.
3D-Fixup: Advancing Photo Editing with 3D Priors
May 15, 2025



Despite significant advances in modeling image priors via diffusion models, 3D-aware image editing remains challenging, in part because the object is only specified via a single image. To tackle this challenge, we propose 3D-Fixup, a new framework for editing 2D images guided by learned 3D priors. The framework supports difficult editing situations such as object translation and 3D rotation. To achieve this, we leverage a training-based approach that harnesses the generative power of diffusion models. As video data naturally encodes real-world physical dynamics, we turn to video data for generating training data pairs, i.e., a source and a target frame. Rather than relying solely on a single trained model to infer transformations between source and target frames, we incorporate 3D guidance from an Image-to-3D model, which bridges this challenging task by explicitly projecting 2D information into 3D space. We design a data generation pipeline to ensure high-quality 3D guidance throughout training. Results show that by integrating these 3D priors, 3D-Fixup effectively supports complex, identity coherent 3D-aware edits, achieving high-quality results and advancing the application of diffusion models in realistic image manipulation. The code is provided at https://3dfixup.github.io/
ObjectMover: Generative Object Movement with Video Prior
Mar 11, 2025Simple as it seems, moving an object to another location within an image is, in fact, a challenging image-editing task that requires re-harmonizing the lighting, adjusting the pose based on perspective, accurately filling occluded regions, and ensuring coherent synchronization of shadows and reflections while maintaining the object identity. In this paper, we present ObjectMover, a generative model that can perform object movement in highly challenging scenes. Our key insight is that we model this task as a sequence-to-sequence problem and fine-tune a video generation model to leverage its knowledge of consistent object generation across video frames. We show that with this approach, our model is able to adjust to complex real-world scenarios, handling extreme lighting harmonization and object effect movement. As large-scale data for object movement are unavailable, we construct a data generation pipeline using a modern game engine to synthesize high-quality data pairs. We further propose a multi-task learning strategy that enables training on real-world video data to improve the model generalization. Through extensive experiments, we demonstrate that ObjectMover achieves outstanding results and adapts well to real-world scenarios.
VideoHandles: Editing 3D Object Compositions in Videos Using Video Generative Priors
Mar 03, 2025Generative methods for image and video editing use generative models as priors to perform edits despite incomplete information, such as changing the composition of 3D objects shown in a single image. Recent methods have shown promising composition editing results in the image setting, but in the video setting, editing methods have focused on editing object's appearance and motion, or camera motion, and as a result, methods to edit object composition in videos are still missing. We propose \name as a method for editing 3D object compositions in videos of static scenes with camera motion. Our approach allows editing the 3D position of a 3D object across all frames of a video in a temporally consistent manner. This is achieved by lifting intermediate features of a generative model to a 3D reconstruction that is shared between all frames, editing the reconstruction, and projecting the features on the edited reconstruction back to each frame. To the best of our knowledge, this is the first generative approach to edit object compositions in videos. Our approach is simple and training-free, while outperforming state-of-the-art image editing baselines.
ShapeLib: designing a library of procedural 3D shape abstractions with Large Language Models
Feb 13, 2025

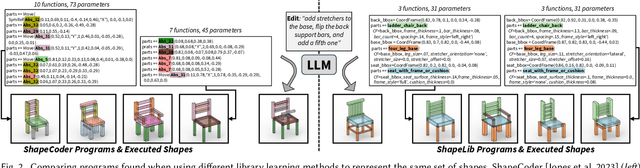

Procedural representations are desirable, versatile, and popular shape encodings. Authoring them, either manually or using data-driven procedures, remains challenging, as a well-designed procedural representation should be compact, intuitive, and easy to manipulate. A long-standing problem in shape analysis studies how to discover a reusable library of procedural functions, with semantically aligned exposed parameters, that can explain an entire shape family. We present ShapeLib as the first method that leverages the priors of frontier LLMs to design a library of 3D shape abstraction functions. Our system accepts two forms of design intent: text descriptions of functions to include in the library and a seed set of exemplar shapes. We discover procedural abstractions that match this design intent by proposing, and then validating, function applications and implementations. The discovered shape functions in the library are not only expressive but also generalize beyond the seed set to a full family of shapes. We train a recognition network that learns to infer shape programs based on our library from different visual modalities (primitives, voxels, point clouds). Our shape functions have parameters that are semantically interpretable and can be modified to produce plausible shape variations. We show that this allows inferred programs to be successfully manipulated by an LLM given a text prompt. We evaluate ShapeLib on different datasets and show clear advantages over existing methods and alternative formulations.
GANFusion: Feed-Forward Text-to-3D with Diffusion in GAN Space
Dec 21, 2024We train a feed-forward text-to-3D diffusion generator for human characters using only single-view 2D data for supervision. Existing 3D generative models cannot yet match the fidelity of image or video generative models. State-of-the-art 3D generators are either trained with explicit 3D supervision and are thus limited by the volume and diversity of existing 3D data. Meanwhile, generators that can be trained with only 2D data as supervision typically produce coarser results, cannot be text-conditioned, or must revert to test-time optimization. We observe that GAN- and diffusion-based generators have complementary qualities: GANs can be trained efficiently with 2D supervision to produce high-quality 3D objects but are hard to condition on text. In contrast, denoising diffusion models can be conditioned efficiently but tend to be hard to train with only 2D supervision. We introduce GANFusion, which starts by generating unconditional triplane features for 3D data using a GAN architecture trained with only single-view 2D data. We then generate random samples from the GAN, caption them, and train a text-conditioned diffusion model that directly learns to sample from the space of good triplane features that can be decoded into 3D objects.
* https://ganfusion.github.io/
Pattern Analogies: Learning to Perform Programmatic Image Edits by Analogy
Dec 17, 2024Pattern images are everywhere in the digital and physical worlds, and tools to edit them are valuable. But editing pattern images is tricky: desired edits are often programmatic: structure-aware edits that alter the underlying program which generates the pattern. One could attempt to infer this underlying program, but current methods for doing so struggle with complex images and produce unorganized programs that make editing tedious. In this work, we introduce a novel approach to perform programmatic edits on pattern images. By using a pattern analogy -- a pair of simple patterns to demonstrate the intended edit -- and a learning-based generative model to execute these edits, our method allows users to intuitively edit patterns. To enable this paradigm, we introduce SplitWeave, a domain-specific language that, combined with a framework for sampling synthetic pattern analogies, enables the creation of a large, high-quality synthetic training dataset. We also present TriFuser, a Latent Diffusion Model (LDM) designed to overcome critical issues that arise when naively deploying LDMs to this task. Extensive experiments on real-world, artist-sourced patterns reveals that our method faithfully performs the demonstrated edit while also generalizing to related pattern styles beyond its training distribution.
Motion Modes: What Could Happen Next?
Nov 29, 2024



Predicting diverse object motions from a single static image remains challenging, as current video generation models often entangle object movement with camera motion and other scene changes. While recent methods can predict specific motions from motion arrow input, they rely on synthetic data and predefined motions, limiting their application to complex scenes. We introduce Motion Modes, a training-free approach that explores a pre-trained image-to-video generator's latent distribution to discover various distinct and plausible motions focused on selected objects in static images. We achieve this by employing a flow generator guided by energy functions designed to disentangle object and camera motion. Additionally, we use an energy inspired by particle guidance to diversify the generated motions, without requiring explicit training data. Experimental results demonstrate that Motion Modes generates realistic and varied object animations, surpassing previous methods and even human predictions regarding plausibility and diversity. Project Webpage: https://motionmodes.github.io/