 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexSliders: Diffusion-Based Texture Editing in CLIP Space
May 01, 2024
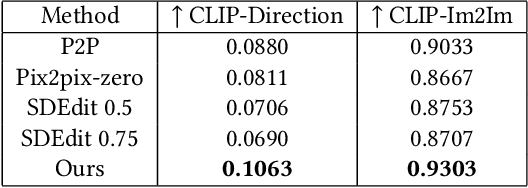


Generative models have enabled intuitive image creation and manipulation using natural language. In particular, diffusion models have recently shown remarkable results for natural image editing. In this work, we propose to apply diffusion techniques to edit textures, a specific class of images that are an essential part of 3D content creation pipelines. We analyze existing editing methods and show that they are not directly applicable to textures, since their common underlying approach, manipulating attention maps, is unsuitable for the texture domain. To address this, we propose a novel approach that instead manipulates CLIP image embeddings to condition the diffusion generation. We define editing directions using simple text prompts (e.g., "aged wood" to "new wood") and map these to CLIP image embedding space using a texture prior, with a sampling-based approach that gives us identity-preserving directions in CLIP space. To further improve identity preservation, we project these directions to a CLIP subspace that minimizes identity variations resulting from entangled texture attributes. Our editing pipeline facilitates the creation of arbitrary sliders using natural language prompts only, with no ground-truth annotated data necessary.
Towards Enhanced Controllability of Diffusion Models
Mar 15, 2023Denoising Diffusion models have shown remarkable capabilities in generating realistic, high-quality and diverse images. However, the extent of controllability during generation is underexplored. Inspired by techniques based on GAN latent space for image manipulation, we train a diffusion model conditioned on two latent codes, a spatial content mask and a flattened style embedding. We rely on the inductive bias of the progressive denoising process of diffusion models to encode pose/layout information in the spatial structure mask and semantic/style information in the style code. We propose two generic sampling techniques for improving controllability. We extend composable diffusion models to allow for some dependence between conditional inputs, to improve the quality of generations while also providing control over the amount of guidance from each latent code and their joint distribution. We also propose timestep dependent weight scheduling for content and style latents to further improve the translations. We observe better controllability compared to existing methods and show that without explicit training objectives, diffusion models can be used for effective image manipulation and image translation.
Controlled and Conditional Text to Image Generation with Diffusion Prior
Feb 23, 2023Denoising Diffusion models have shown remarkable performance in generating diverse, high quality images from text. Numerous techniques have been proposed on top of or in alignment with models like Stable Diffusion and Imagen that generate images directly from text. A lesser explored approach is DALLE-2's two step process comprising a Diffusion Prior that generates a CLIP image embedding from text and a Diffusion Decoder that generates an image from a CLIP image embedding. We explore the capabilities of the Diffusion Prior and the advantages of an intermediate CLIP representation. We observe that Diffusion Prior can be used in a memory and compute efficient way to constrain the generation to a specific domain without altering the larger Diffusion Decoder. Moreover, we show that the Diffusion Prior can be trained with additional conditional information such as color histogram to further control the generation. We show quantitatively and qualitatively that the proposed approaches perform better than prompt engineering for domain specific generation and existing baselines for color conditioned generation. We believe that our observations and results will instigate further research into the diffusion prior and uncover more of its capabilities.
PRedItOR: Text Guided Image Editing with Diffusion Prior
Feb 15, 2023



Diffusion models have shown remarkable capabilities in generating high quality and creative images conditioned on text. An interesting application of such models is structure preserving text guided image editing. Existing approaches rely on text conditioned diffusion models such as Stable Diffusion or Imagen and require compute intensive optimization of text embeddings or fine-tuning the model weights for text guided image editing. We explore text guided image editing with a Hybrid Diffusion Model (HDM) architecture similar to DALLE-2. Our architecture consists of a diffusion prior model that generates CLIP image embedding conditioned on a text prompt and a custom Latent Diffusion Model trained to generate images conditioned on CLIP image embedding. We discover that the diffusion prior model can be used to perform text guided conceptual edits on the CLIP image embedding space without any finetuning or optimization. We combine this with structure preserving edits on the image decoder using existing approaches such as reverse DDIM to perform text guided image editing. Our approach, PRedItOR does not require additional inputs, fine-tuning, optimization or objectives and shows on par or better results than baselines qualitatively and quantitatively. We provide further analysis and understanding of the diffusion prior model and believe this opens up new possibilities in diffusion models research.