 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled and Conditional Text to Image Generation with Diffusion Prior
Feb 23, 2023Denoising Diffusion models have shown remarkable performance in generating diverse, high quality images from text. Numerous techniques have been proposed on top of or in alignment with models like Stable Diffusion and Imagen that generate images directly from text. A lesser explored approach is DALLE-2's two step process comprising a Diffusion Prior that generates a CLIP image embedding from text and a Diffusion Decoder that generates an image from a CLIP image embedding. We explore the capabilities of the Diffusion Prior and the advantages of an intermediate CLIP representation. We observe that Diffusion Prior can be used in a memory and compute efficient way to constrain the generation to a specific domain without altering the larger Diffusion Decoder. Moreover, we show that the Diffusion Prior can be trained with additional conditional information such as color histogram to further control the generation. We show quantitatively and qualitatively that the proposed approaches perform better than prompt engineering for domain specific generation and existing baselines for color conditioned generation. We believe that our observations and results will instigate further research into the diffusion prior and uncover more of its capabilities.
StyleBabel: Artistic Style Tagging and Captioning
Mar 11, 2022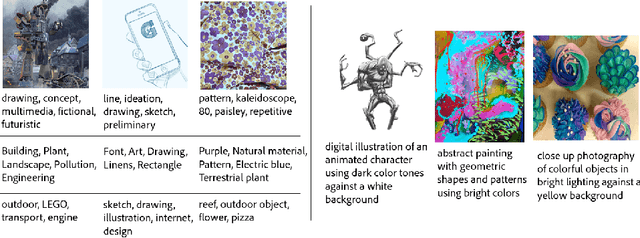
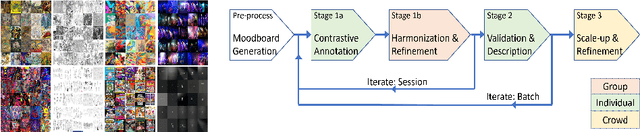

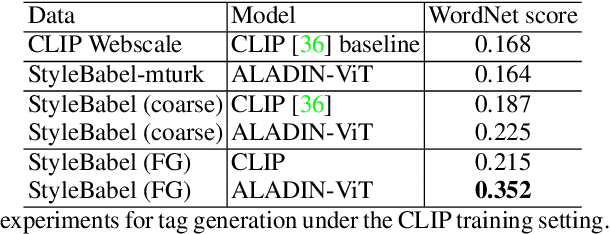
We present StyleBabel, a unique open access dataset of natural language captions and free-form tags describing the artistic style of over 135K digital artworks, collected via a novel participatory method from experts studying at specialist art and design schools. StyleBabel was collected via an iterative method, inspired by `Grounded Theory': a qualitative approach that enables annotation while co-evolving a shared language for fine-grained artistic style attribute description. We demonstrate several downstream tasks for StyleBabel, adapting the recent ALADIN architecture for fine-grained style similarity, to train cross-modal embeddings for: 1) free-form tag generation; 2) natural language description of artistic style; 3) fine-grained text search of style. To do so, we extend ALADIN with recent advances in Visual Transformer (ViT) and cross-modal representation learning, achieving a state of the art accuracy in fine-grained style retrieval.
Towards Zero-shot Cross-lingual Image Retrieval and Tagging
Sep 15, 2021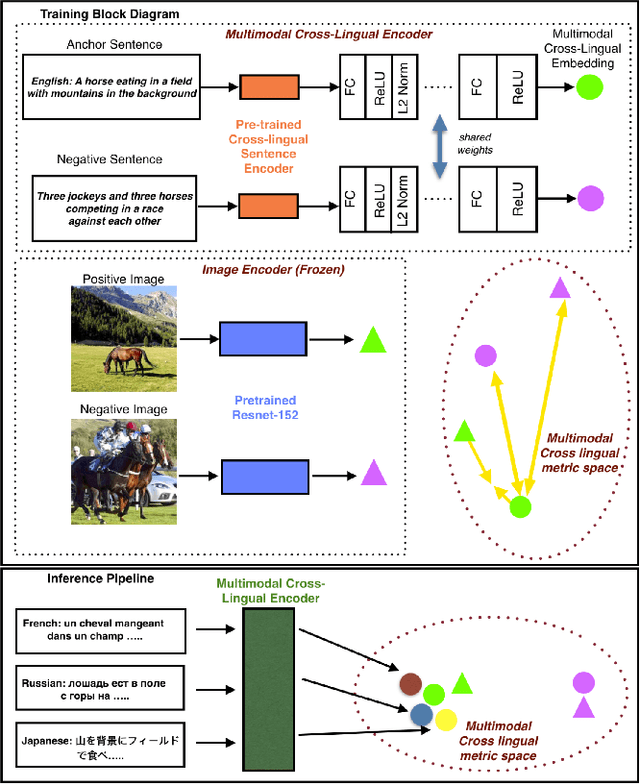
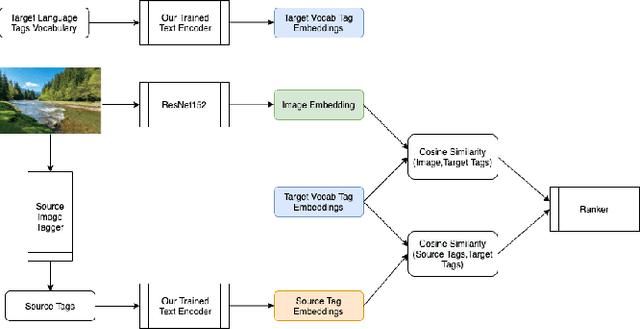
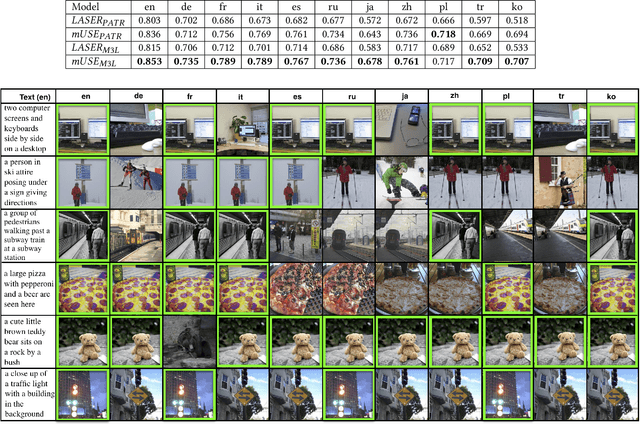
There has been a recent spike in interest in multi-modal Language and Vision problems. On the language side, most of these models primarily focus on English since most multi-modal datasets are monolingual. We try to bridge this gap with a zero-shot approach for learning multi-modal representations using cross-lingual pre-training on the text side. We present a simple yet practical approach for building a cross-lingual image retrieval model which trains on a monolingual training dataset but can be used in a zero-shot cross-lingual fashion during inference. We also introduce a new objective function which tightens the text embedding clusters by pushing dissimilar texts away from each other. For evaluation, we introduce a new 1K multi-lingual MSCOCO2014 caption test dataset (XTD10) in 7 languages that we collected using a crowdsourcing platform. We use this as the test set for zero-shot model performance across languages. We also demonstrate how a cross-lingual model can be used for downstream tasks like multi-lingual image tagging in a zero shot manner. XTD10 dataset is made publicly available here: https://github.com/adobe-research/Cross-lingual-Test-Dataset-XTD10.
Towards Zero-shot Cross-lingual Image Retrieval
Nov 24, 2020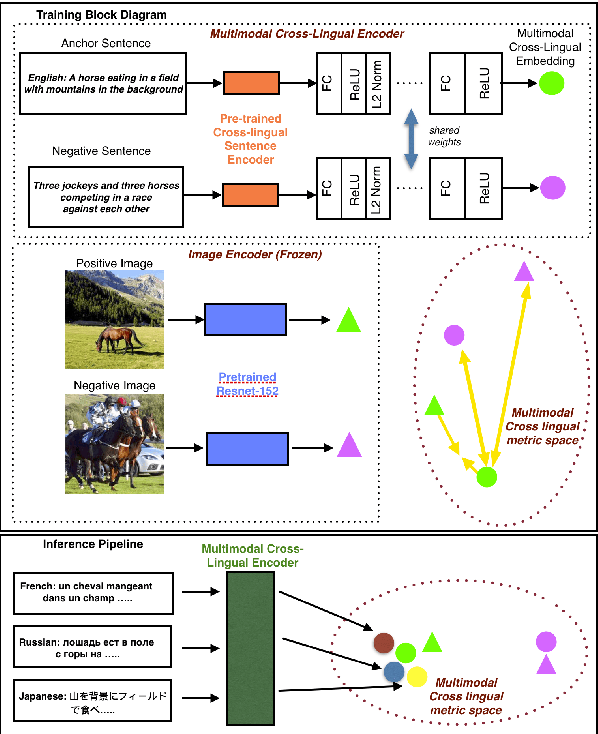

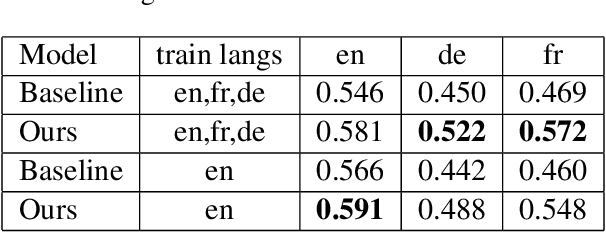
There has been a recent spike in interest in multi-modal Language and Vision problems. On the language side, most of these models primarily focus on English since most multi-modal datasets are monolingual. We try to bridge this gap with a zero-shot approach for learning multi-modal representations using cross-lingual pre-training on the text side. We present a simple yet practical approach for building a cross-lingual image retrieval model which trains on a monolingual training dataset but can be used in a zero-shot cross-lingual fashion during inference. We also introduce a new objective function which tightens the text embedding clusters by pushing dissimilar texts from each other. Finally, we introduce a new 1K multi-lingual MSCOCO2014 caption test dataset (XTD10) in 7 languages that we collected using a crowdsourcing platform. We use this as the test set for evaluating zero-shot model performance across languages. XTD10 dataset is made publicly available here: https://github.com/adobe-research/Cross-lingual-Test-Dataset-XTD10
Multi-Modal Retrieval using Graph Neural Networks
Oct 04, 2020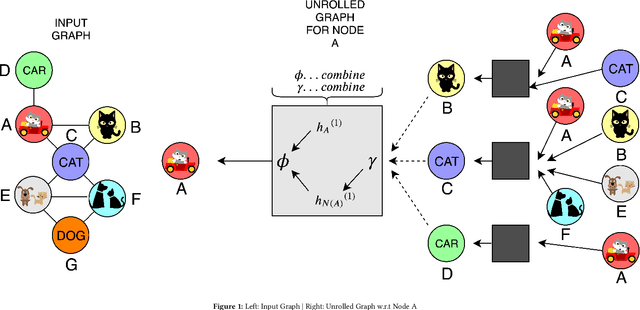

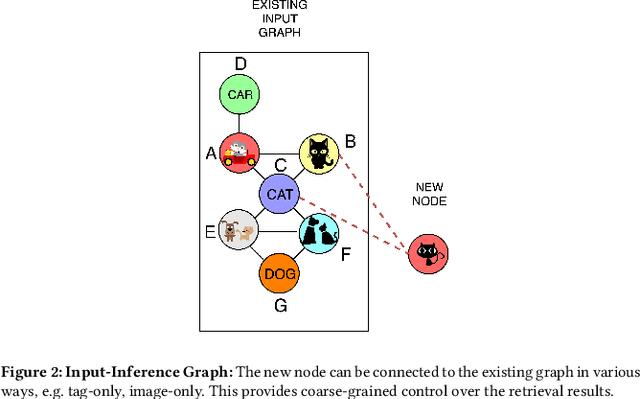

Most real world applications of image retrieval such as Adobe Stock, which is a marketplace for stock photography and illustrations, need a way for users to find images which are both visually (i.e. aesthetically) and conceptually (i.e. containing the same salient objects) as a query image. Learning visual-semantic representations from images is a well studied problem for image retrieval. Filtering based on image concepts or attributes is traditionally achieved with index-based filtering (e.g. on textual tags) or by re-ranking after an initial visual embedding based retrieval. In this paper, we learn a joint vision and concept embedding in the same high-dimensional space. This joint model gives the user fine-grained control over the semantics of the result set, allowing them to explore the catalog of images more rapidly. We model the visual and concept relationships as a graph structure, which captures the rich information through node neighborhood. This graph structure helps us learn multi-modal node embeddings using Graph Neural Networks. We also introduce a novel inference time control, based on selective neighborhood connectivity allowing the user control over the retrieval algorithm. We evaluate these multi-modal embeddings quantitatively on the downstream relevance task of image retrieval on MS-COCO dataset and qualitatively on MS-COCO and an Adobe Stock dataset.
Multitask Text-to-Visual Embedding with Titles and Clickthrough Data
May 30, 2019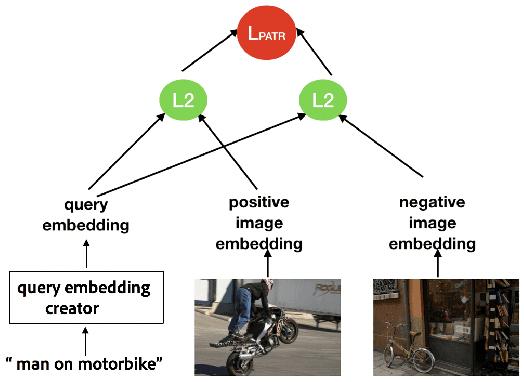
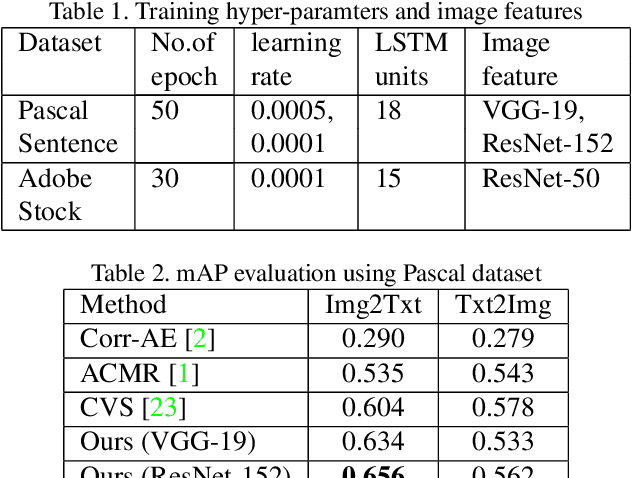

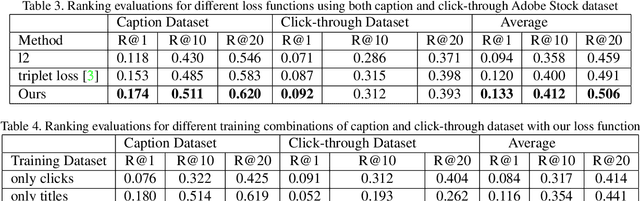
Text-visual (or called semantic-visual) embedding is a central problem in vision-language research. It typically involves mapping of an image and a text description to a common feature space through a CNN image encoder and a RNN language encoder. In this paper, we propose a new method for learning text-visual embedding using both image titles and click-through data from an image search engine. We also propose a new triplet loss function by modeling positive awareness of the embedding, and introduce a novel mini-batch-based hard negative sampling approach for better data efficiency in the learning process. Experimental results show that our proposed method outperforms existing methods, and is also effective for real-world text-to-visual retrieval.
A Deep Learning Approach to Drone Monitoring
Dec 04, 2017



A drone monitoring system that integrates deep-learning-based detection and tracking modules is proposed in this work. The biggest challenge in adopting deep learning methods for drone detection is the limited amount of training drone images. To address this issue, we develop a model-based drone augmentation technique that automatically generates drone images with a bounding box label on drone's location. To track a small flying drone, we utilize the residual information between consecutive image frames. Finally, we present an integrated detection and tracking system that outperforms the performance of each individual module containing detection or tracking only. The experiments show that, even being trained on synthetic data, the proposed system performs well on real world drone images with complex background. The USC drone detection and tracking dataset with user labeled bounding boxes is available to the public.