 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
HyperNST: Hyper-Networks for Neural Style Transfer
Aug 09, 2022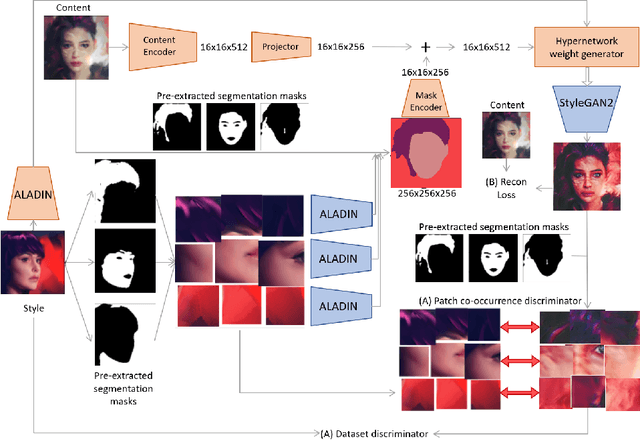
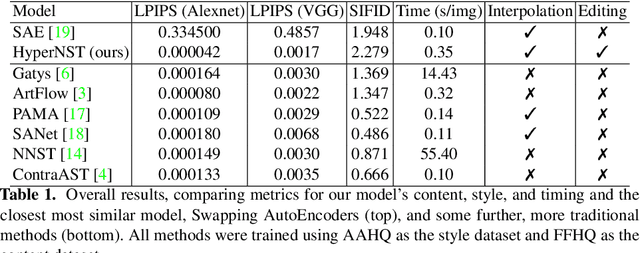
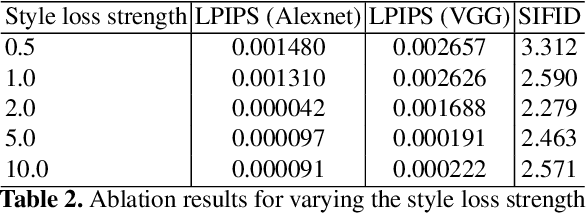

We present HyperNST; a neural style transfer (NST) technique for the artistic stylization of images, based on Hyper-networks and the StyleGAN2 architecture. Our contribution is a novel method for inducing style transfer parameterized by a metric space, pre-trained for style-based visual search (SBVS). We show for the first time that such space may be used to drive NST, enabling the application and interpolation of styles from an SBVS system. The technical contribution is a hyper-network that predicts weight updates to a StyleGAN2 pre-trained over a diverse gamut of artistic content (portraits), tailoring the style parameterization on a per-region basis using a semantic map of the facial regions. We show HyperNST to exceed state of the art in content preservation for our stylized content while retaining good style transfer performance.
The Contextual Appointment Scheduling Problem
Aug 12, 2021
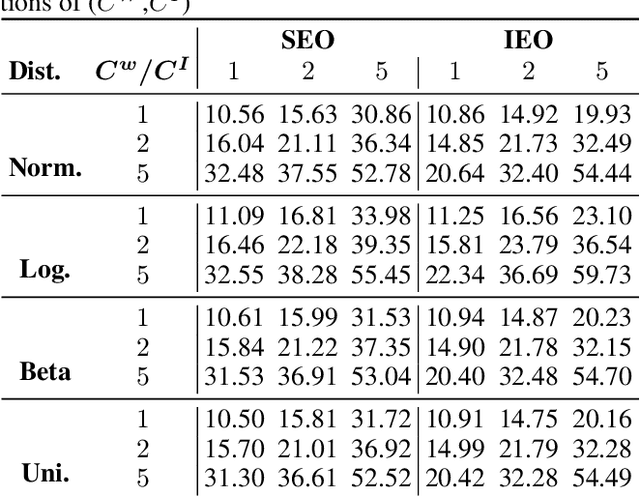
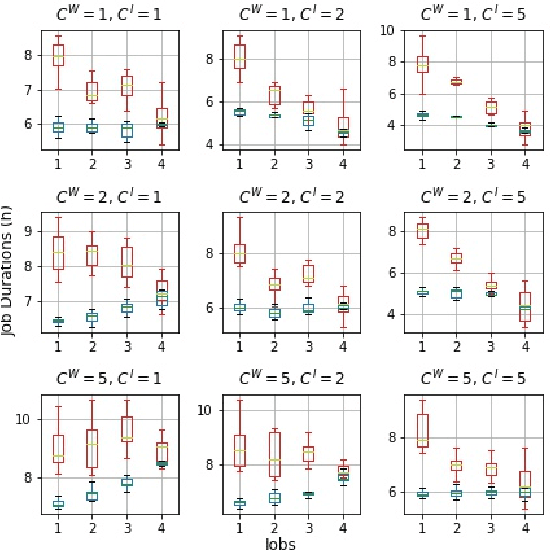
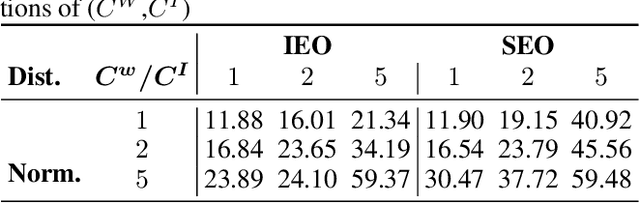
This study is concerned with the determination of optimal appointment times for a sequence of jobs with uncertain duration. We investigate the data-driven Appointment Scheduling Problem (ASP) when one has $n$ observations of $p$ features (covariates) related to the jobs as well as historical data. We formulate ASP as an Integrated Estimation and Optimization problem using a task-based loss function. We justify the use of contexts by showing that not including the them yields to inconsistent decisions, which translates to sub-optimal appointments. We validate our approach through two numerical experiments.
ALADIN: All Layer Adaptive Instance Normalization for Fine-grained Style Similarity
Mar 17, 2021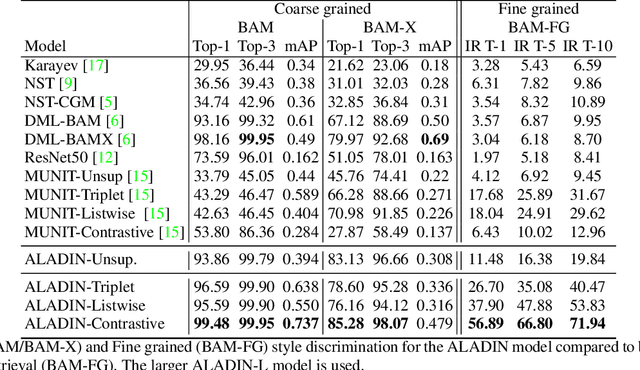
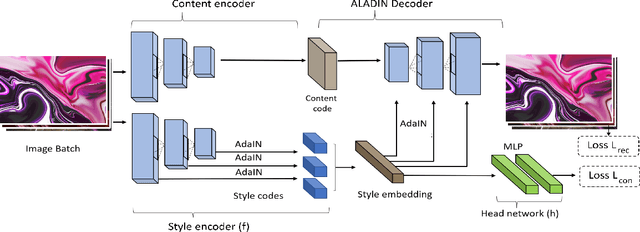
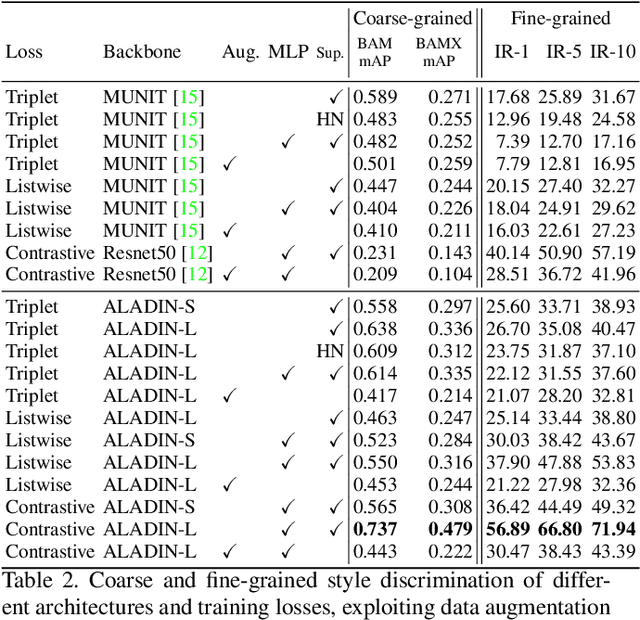

We present ALADIN (All Layer AdaIN); a novel architecture for searching images based on the similarity of their artistic style. Representation learning is critical to visual search, where distance in the learned search embedding reflects image similarity. Learning an embedding that discriminates fine-grained variations in style is hard, due to the difficulty of defining and labelling style. ALADIN takes a weakly supervised approach to learning a representation for fine-grained style similarity of digital artworks, leveraging BAM-FG, a novel large-scale dataset of user generated content groupings gathered from the web. ALADIN sets a new state of the art accuracy for style-based visual search over both coarse labelled style data (BAM) and BAM-FG; a new 2.62 million image dataset of 310,000 fine-grained style groupings also contributed by this work.
Multitask Text-to-Visual Embedding with Titles and Clickthrough Data
May 30, 2019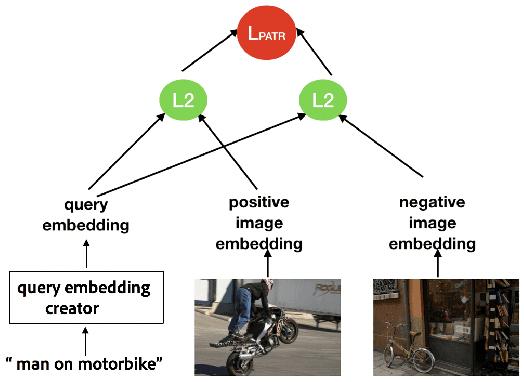
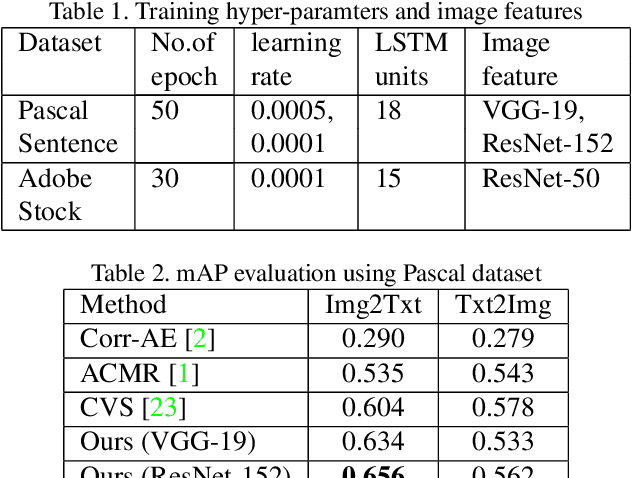

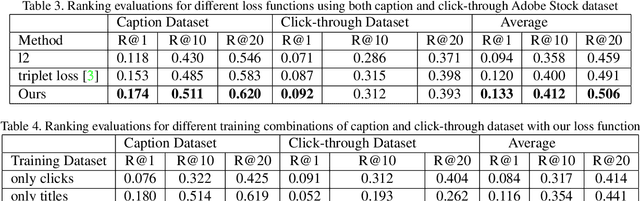
Text-visual (or called semantic-visual) embedding is a central problem in vision-language research. It typically involves mapping of an image and a text description to a common feature space through a CNN image encoder and a RNN language encoder. In this paper, we propose a new method for learning text-visual embedding using both image titles and click-through data from an image search engine. We also propose a new triplet loss function by modeling positive awareness of the embedding, and introduce a novel mini-batch-based hard negative sampling approach for better data efficiency in the learning process. Experimental results show that our proposed method outperforms existing methods, and is also effective for real-world text-to-visual retrieval.
Few-Shot Adversarial Domain Adaptation
Nov 05, 2017
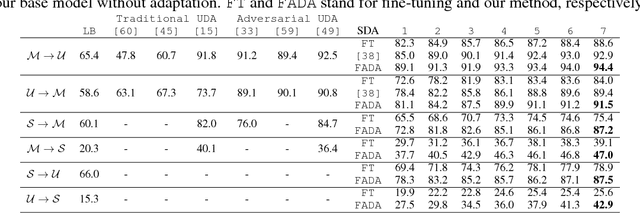
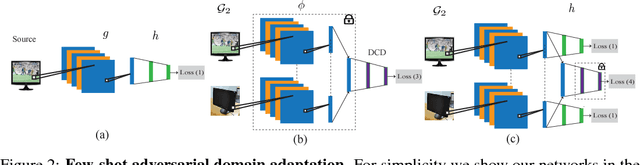
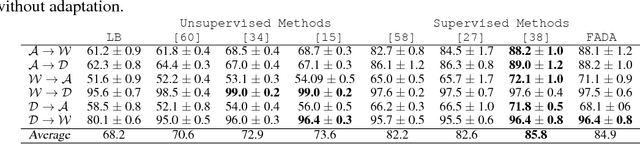
This work provides a framework for addressing the problem of supervised domain adaptation with deep models. The main idea is to exploit adversarial learning to learn an embedded subspace that simultaneously maximizes the confusion between two domains while semantically aligning their embedding. The supervised setting becomes attractive especially when there are only a few target data samples that need to be labeled. In this few-shot learning scenario, alignment and separation of semantic probability distributions is difficult because of the lack of data. We found that by carefully designing a training scheme whereby the typical binary adversarial discriminator is augmented to distinguish between four different classes, it is possible to effectively address the supervised adaptation problem. In addition, the approach has a high speed of adaptation, i.e. it requires an extremely low number of labeled target training samples, even one per category can be effective. We then extensively compare this approach to the state of the art in domain adaptation in two experiments: one using datasets for handwritten digit recognition, and one using datasets for visual object recognition.
Unified Deep Supervised Domain Adaptation and Generalization
Sep 28, 2017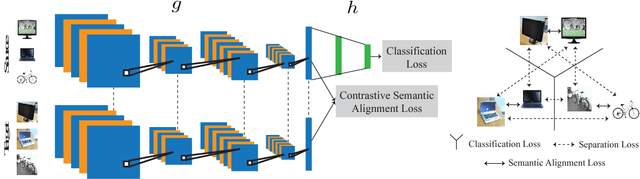



This work provides a unified framework for addressing the problem of visual supervised domain adaptation and generalization with deep models. The main idea is to exploit the Siamese architecture to learn an embedding subspace that is discriminative, and where mapped visual domains are semantically aligned and yet maximally separated. The supervised setting becomes attractive especially when only few target data samples need to be labeled. In this scenario, alignment and separation of semantic probability distributions is difficult because of the lack of data. We found that by reverting to point-wise surrogates of distribution distances and similarities provides an effective solution. In addition, the approach has a high speed of adaptation, which requires an extremely low number of labeled target training samples, even one per category can be effective. The approach is extended to domain generalization. For both applications the experiments show very promising results.