 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Contextual Appointment Scheduling Problem
Aug 12, 2021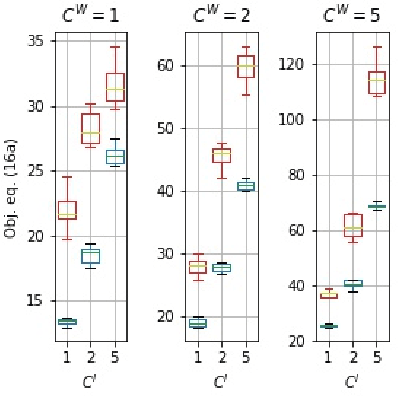
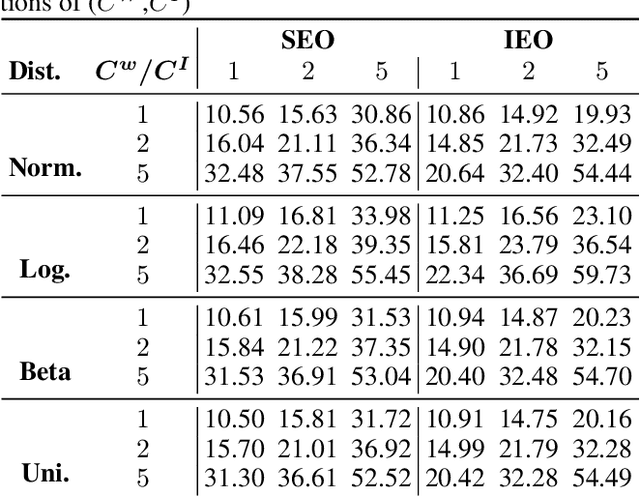
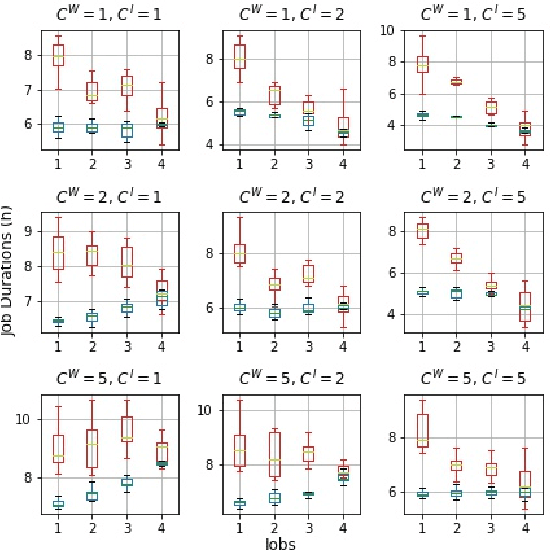
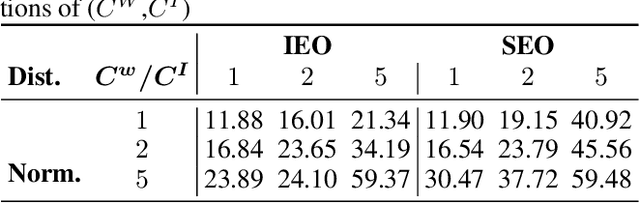
This study is concerned with the determination of optimal appointment times for a sequence of jobs with uncertain duration. We investigate the data-driven Appointment Scheduling Problem (ASP) when one has $n$ observations of $p$ features (covariates) related to the jobs as well as historical data. We formulate ASP as an Integrated Estimation and Optimization problem using a task-based loss function. We justify the use of contexts by showing that not including the them yields to inconsistent decisions, which translates to sub-optimal appointments. We validate our approach through two numerical experiments.
Generating multi-type sequences of temporal events to improve fraud detection in game advertising
Apr 07, 2021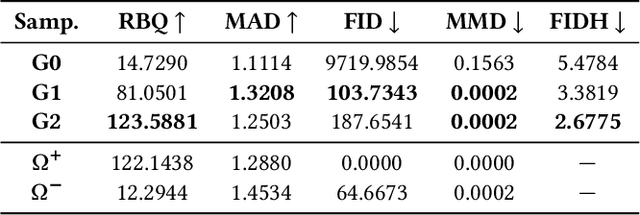
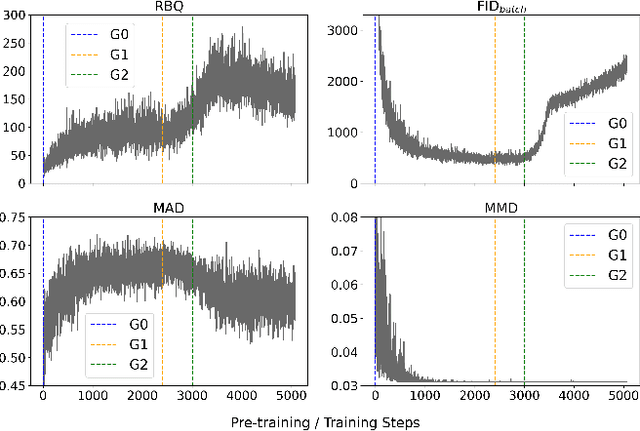
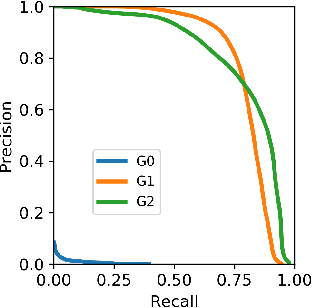
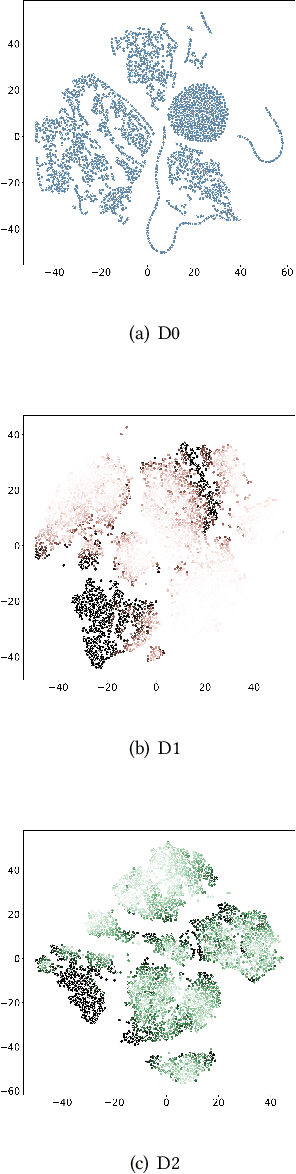
Fraudulent activities related to online advertising can potentially harm the trust advertisers put in advertising networks and sour the gaming experience for users. Pay-Per-Click/Install (PPC/I) advertising is one of the main revenue models in game monetization. Widespread use of the PPC/I model has led to a rise in click/install fraud events in games. The majority of traffic in ad networks is non-fraudulent, which imposes difficulties on machine learning based fraud detection systems to deal with highly skewed labels. From the ad network standpoint, user activities are multi-type sequences of temporal events consisting of event types and corresponding time intervals. Time Long Short-Term Memory (Time-LSTM) network cells have been proved effective in modeling intrinsic hidden patterns with non-uniform time intervals. In this study, we propose using a variant of Time-LSTM cells in combination with a modified version of Sequence Generative Adversarial Generative (SeqGAN)to generate artificial sequences to mimic the fraudulent user patterns in ad traffic. We also propose using a Critic network instead of Monte-Carlo (MC) roll-out in training SeqGAN to reduce computational costs. The GAN-generated sequences can be used to enhance the classification ability of event-based fraud detection classifiers. Our extensive experiments based on synthetic data have shown the trained generator has the capability to generate sequences with desired properties measured by multiple criteria.