 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePair DETR: Contrastive Learning Speeds Up DETR Training
Nov 11, 2022



The DETR object detection approach applies the transformer encoder and decoder architecture to detect objects and achieves promising performance. In this paper, we present a simple approach to address the main problem of DETR, the slow convergence, by using representation learning technique. In this approach, we detect an object bounding box as a pair of keypoints, the top-left corner and the center, using two decoders. By detecting objects as paired keypoints, the model builds up a joint classification and pair association on the output queries from two decoders. For the pair association we propose utilizing contrastive self-supervised learning algorithm without requiring specialized architecture. Experimental results on MS COCO dataset show that Pair DETR can converge at least 10x faster than original DETR and 1.5x faster than Conditional DETR during training, while having consistently higher Average Precision scores.
PatchTrack: Multiple Object Tracking Using Frame Patches
Jan 01, 2022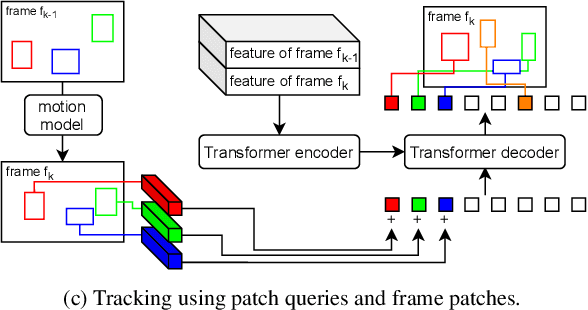
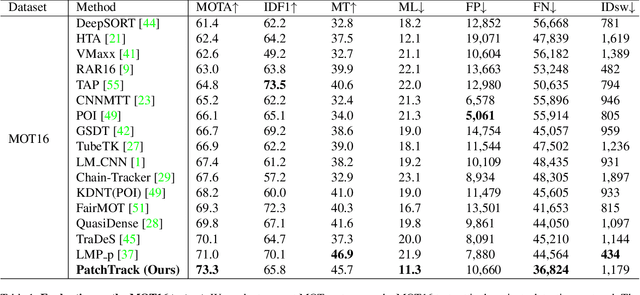
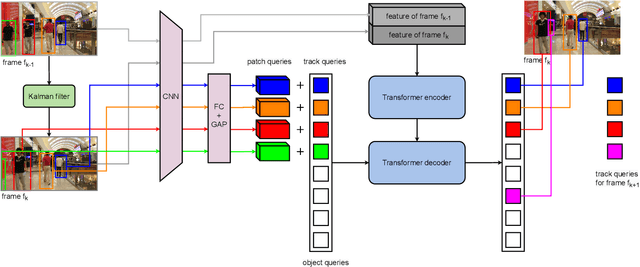
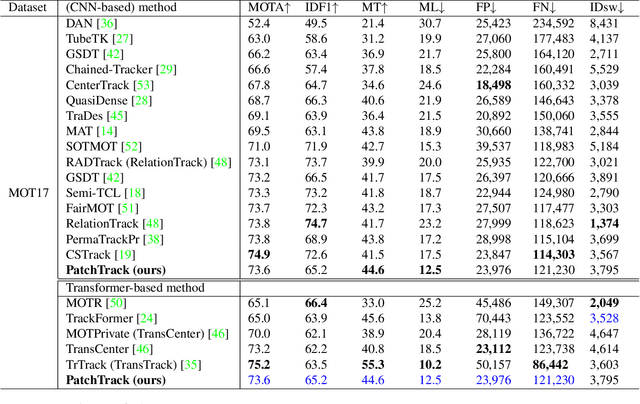
Object motion and object appearance are commonly used information in multiple object tracking (MOT) applications, either for associating detections across frames in tracking-by-detection methods or direct track predictions for joint-detection-and-tracking methods. However, not only are these two types of information often considered separately, but also they do not help optimize the usage of visual information from the current frame of interest directly. In this paper, we present PatchTrack, a Transformer-based joint-detection-and-tracking system that predicts tracks using patches of the current frame of interest. We use the Kalman filter to predict the locations of existing tracks in the current frame from the previous frame. Patches cropped from the predicted bounding boxes are sent to the Transformer decoder to infer new tracks. By utilizing both object motion and object appearance information encoded in patches, the proposed method pays more attention to where new tracks are more likely to occur. We show the effectiveness of PatchTrack on recent MOT benchmarks, including MOT16 (MOTA 73.71%, IDF1 65.77%) and MOT17 (MOTA 73.59%, IDF1 65.23%). The results are published on https://motchallenge.net/method/MOT=4725&chl=10.
Quality-Aware Multimodal Biometric Recognition
Dec 10, 2021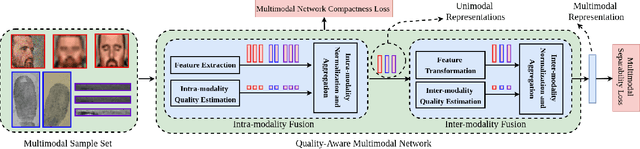
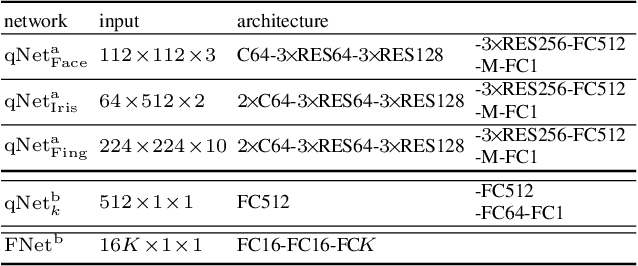
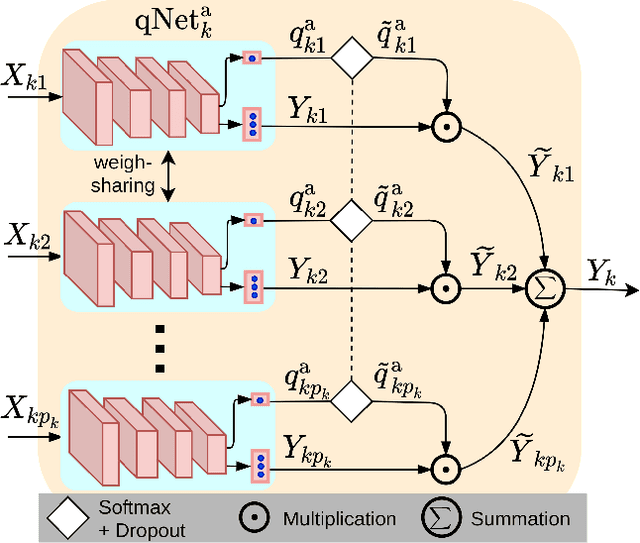
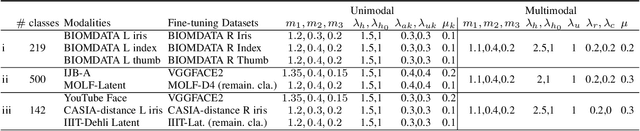
We present a quality-aware multimodal recognition framework that combines representations from multiple biometric traits with varying quality and number of samples to achieve increased recognition accuracy by extracting complimentary identification information based on the quality of the samples. We develop a quality-aware framework for fusing representations of input modalities by weighting their importance using quality scores estimated in a weakly-supervised fashion. This framework utilizes two fusion blocks, each represented by a set of quality-aware and aggregation networks. In addition to architecture modifications, we propose two task-specific loss functions: multimodal separability loss and multimodal compactness loss. The first loss assures that the representations of modalities for a class have comparable magnitudes to provide a better quality estimation, while the multimodal representations of different classes are distributed to achieve maximum discrimination in the embedding space. The second loss, which is considered to regularize the network weights, improves the generalization performance by regularizing the framework. We evaluate the performance by considering three multimodal datasets consisting of face, iris, and fingerprint modalities. The efficacy of the framework is demonstrated through comparison with the state-of-the-art algorithms. In particular, our framework outperforms the rank- and score-level fusion of modalities of BIOMDATA by more than 30% for true acceptance rate at false acceptance rate of $10^{-4}$.
HGAN: Hybrid Generative Adversarial Network
Feb 07, 2021
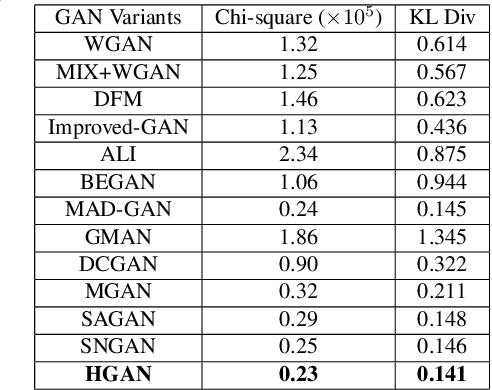


In this paper, we present a simple approach to train Generative Adversarial Networks (GANs) in order to avoid a \textit {mode collapse} issue. Implicit models such as GANs tend to generate better samples compared to explicit models that are trained on tractable data likelihood. However, GANs overlook the explicit data density characteristics which leads to undesirable quantitative evaluations and mode collapse. To bridge this gap, we propose a hybrid generative adversarial network (HGAN) for which we can enforce data density estimation via an autoregressive model and support both adversarial and likelihood framework in a joint training manner which diversify the estimated density in order to cover different modes. We propose to use an adversarial network to \textit {transfer knowledge} from an autoregressive model (teacher) to the generator (student) of a GAN model. A novel deep architecture within the GAN formulation is developed to adversarially distill the autoregressive model information in addition to simple GAN training approach. We conduct extensive experiments on real-world datasets (i.e., MNIST, CIFAR-10, STL-10) to demonstrate the effectiveness of the proposed HGAN under qualitative and quantitative evaluations. The experimental results show the superiority and competitiveness of our method compared to the baselines.
Attribute Adaptive Margin Softmax Loss using Privileged Information
Sep 04, 2020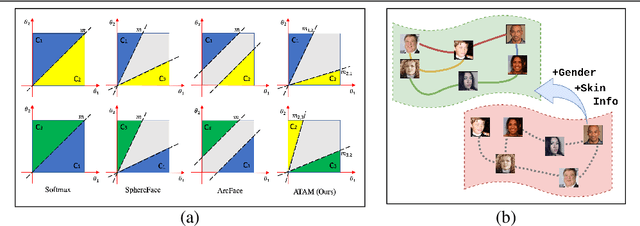
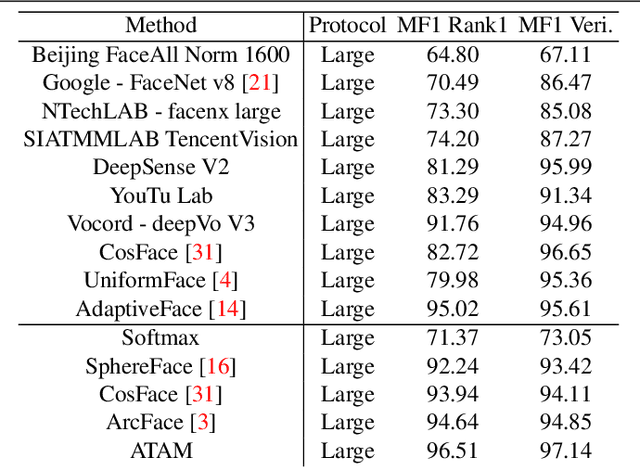
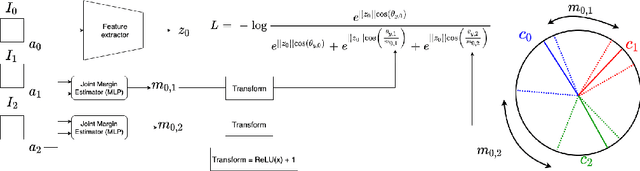
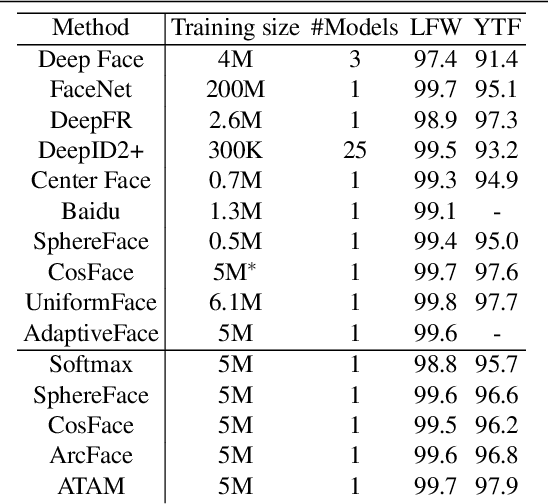
We present a novel framework to exploit privileged information for recognition which is provided only during the training phase. Here, we focus on recognition task where images are provided as the main view and soft biometric traits (attributes) are provided as the privileged data (only available during training phase). We demonstrate that more discriminative feature space can be learned by enforcing a deep network to adjust adaptive margins between classes utilizing attributes. This tight constraint also effectively reduces the class imbalance inherent in the local data neighborhood, thus carving more balanced class boundaries locally and using feature space more efficiently. Extensive experiments are performed on five different datasets and the results show the superiority of our method compared to the state-of-the-art models in both tasks of face recognition and person re-identification.
Robust Facial Landmark Detection via Aggregation on Geometrically Manipulated Faces
Jan 07, 2020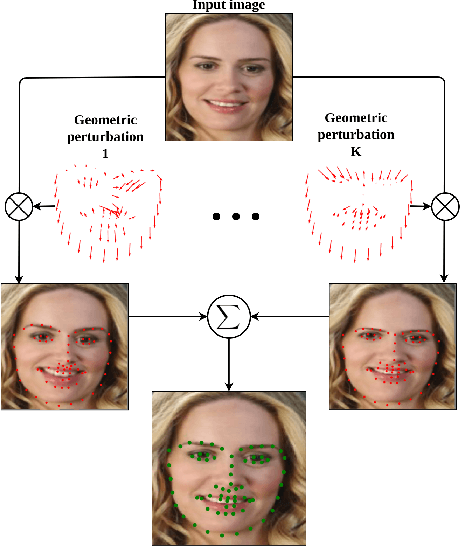

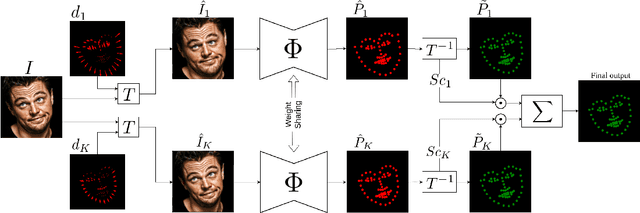

In this work, we present a practical approach to the problem of facial landmark detection. The proposed method can deal with large shape and appearance variations under the rich shape deformation. To handle the shape variations we equip our method with the aggregation of manipulated face images. The proposed framework generates different manipulated faces using only one given face image. The approach utilizes the fact that small but carefully crafted geometric manipulation in the input domain can fool deep face recognition models. We propose three different approaches to generate manipulated faces in which two of them perform the manipulations via adversarial attacks and the other one uses known transformations. Aggregating the manipulated faces provides a more robust landmark detection approach which is able to capture more important deformations and variations of the face shapes. Our approach is demonstrated its superiority compared to the state-of-the-art method on benchmark datasets AFLW, 300-W, and COFW.
Empirical Upper Bound in Object Detection and More
Dec 17, 2019



Object detection remains as one of the most notorious open problems in computer vision. Despite large strides in accuracy in recent years, modern object detectors have started to saturate on popular benchmarks raising the question of how far we can reach with deep learning tools and tricks. Here, by employing 2 state-of-the-art object detection benchmarks, and analyzing more than 15 models over 4 large scale datasets, we I) carefully determine the upperbound in AP, which is 91.6% on VOC (test2007), 78.2% on COCO (val2017), and 58.9% on OpenImages V4 (validation), regardless of the IOU. These numbers are much better than the mAP of the best model1 (47.9% on VOC, and 46.9% on COCO; IOUs=.5:.95), II) characterize the sources of errors in object detectors, in a novel and intuitive way, and find that classification error (confusion with other classes and misses) explains the largest fraction of errors and weighs more than localization and duplicate errors, and III) analyze the invariance properties of models when surrounding context of an object is removed, when an object is placed in an incongruent background, and when images are blurred or flipped vertically. We find that models generate boxes on empty regions and that context is more important for detecting small objects than larger ones. Our work taps into the tight relationship between recognition and detection and offers insights for building better models.
Attribute-Guided Deep Polarimetric Thermal-to-visible Face Recognition
Jul 27, 2019



In this paper, we present an attribute-guided deep coupled learning framework to address the problem of matching polarimetric thermal face photos against a gallery of visible faces. The coupled framework contains two sub-networks, one dedicated to the visible spectrum and the second sub-network dedicated to the polarimetric thermal spectrum. Each sub-network is made of a generative adversarial network (GAN) architecture. We propose a novel Attribute-Guided Coupled Generative Adversarial Network (AGC-GAN) architecture which utilizes facial attributes to improve the thermal-to-visible face recognition performance. The proposed AGC-GAN exploits the facial attributes and leverages multiple loss functions in order to learn rich discriminative features in a common embedding subspace. To achieve a realistic photo reconstruction while preserving the discriminative information, we also add a perceptual loss term to the coupling loss function. An ablation study is performed to show the effectiveness of different loss functions for optimizing the proposed method. Moreover, the superiority of the model compared to the state-of-the-art models is demonstrated using polarimetric dataset.
Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Nov 29, 2018
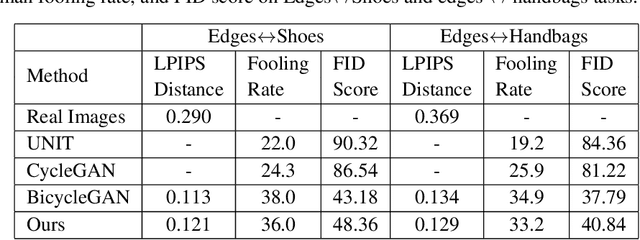
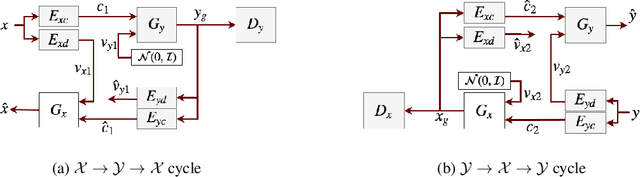
Unsupervised image-to-image translation is a class of computer vision problems which aims at modeling conditional distribution of images in the target domain, given a set of unpaired images in the source and target domains. An image in the source domain might have multiple representations in the target domain. Therefore, ambiguity in modeling of the conditional distribution arises, specially when the images in the source and target domains come from different modalities. Current approaches mostly rely on simplifying assumptions to map both domains into a shared-latent space. Consequently, they are only able to model the domain-invariant information between the two modalities. These approaches usually fail to model domain-specific information which has no representation in the target domain. In this work, we propose an unsupervised image-to-image translation framework which maximizes a domain-specific variational information bound and learns the target domain-invariant representation of the two domain. The proposed framework makes it possible to map a single source image into multiple images in the target domain, utilizing several target domain-specific codes sampled randomly from the prior distribution, or extracted from reference images.
Style and Content Disentanglement in Generative Adversarial Networks
Nov 14, 2018
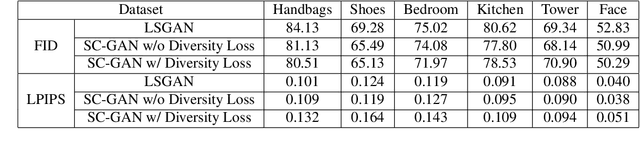
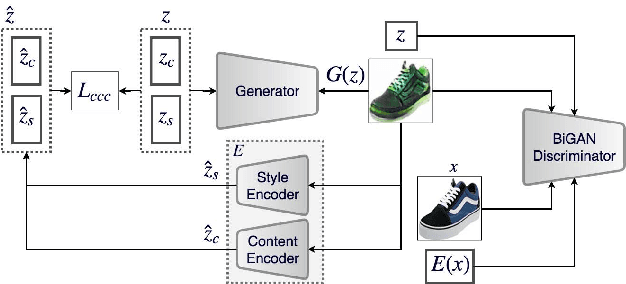
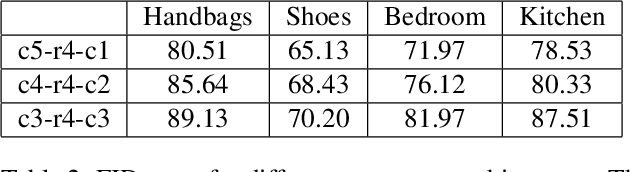
Disentangling factors of variation within data has become a very challenging problem for image generation tasks. Current frameworks for training a Generative Adversarial Network (GAN), learn to disentangle the representations of the data in an unsupervised fashion and capture the most significant factors of the data variations. However, these approaches ignore the principle of content and style disentanglement in image generation, which means their learned latent code may alter the content and style of the generated images at the same time. This paper describes the Style and Content Disentangled GAN (SC-GAN), a new unsupervised algorithm for training GANs that learns disentangled style and content representations of the data. We assume that the representation of an image can be decomposed into a content code that represents the geometrical information of the data, and a style code that captures textural properties. Consequently, by fixing the style portion of the latent representation, we can generate diverse images in a particular style. Reversely, we can set the content code and generate a specific scene in a variety of styles. The proposed SC-GAN has two components: a content code which is the input to the generator, and a style code which modifies the scene style through modification of the Adaptive Instance Normalization (AdaIN) layers' parameters. We evaluate the proposed SC-GAN framework on a set of baseline datasets.