 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT Models in Construction Industry: Opportunities, Limitations, and a Use Case Validation
May 30, 2023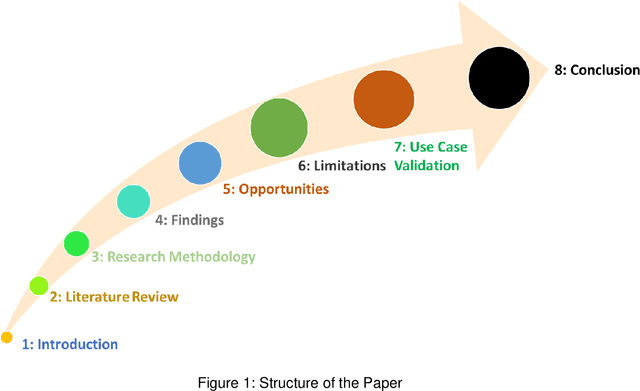
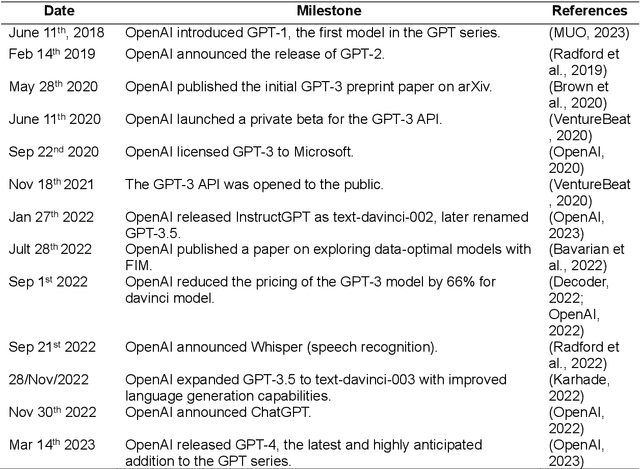

Large Language Models(LLMs) trained on large data sets came into prominence in 2018 after Google introduced BERT. Subsequently, different LLMs such as GPT models from OpenAI have been released. These models perform well on diverse tasks and have been gaining widespread applications in fields such as business and education. However, little is known about the opportunities and challenges of using LLMs in the construction industry. Thus, this study aims to assess GPT models in the construction industry. A critical review, expert discussion and case study validation are employed to achieve the study objectives. The findings revealed opportunities for GPT models throughout the project lifecycle. The challenges of leveraging GPT models are highlighted and a use case prototype is developed for materials selection and optimization. The findings of the study would be of benefit to researchers, practitioners and stakeholders, as it presents research vistas for LLMs in the construction industry.
Matching Distributions via Optimal Transport for Semi-Supervised Learning
Dec 04, 2020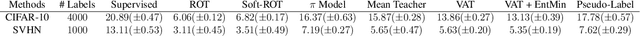
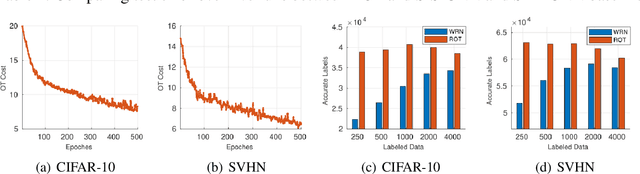
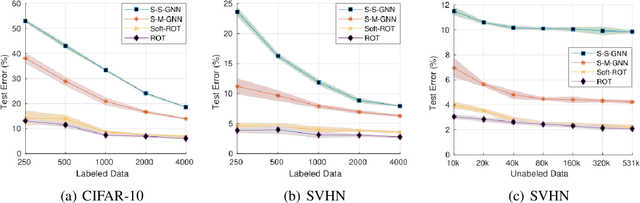
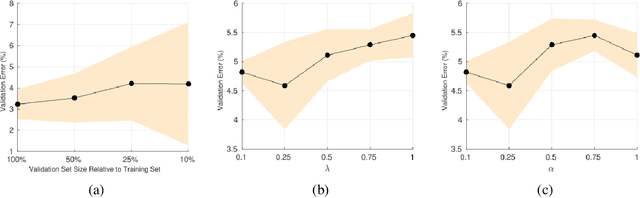
Semi-Supervised Learning (SSL) approaches have been an influential framework for the usage of unlabeled data when there is not a sufficient amount of labeled data available over the course of training. SSL methods based on Convolutional Neural Networks (CNNs) have recently provided successful results on standard benchmark tasks such as image classification. In this work, we consider the general setting of SSL problem where the labeled and unlabeled data come from the same underlying probability distribution. We propose a new approach that adopts an Optimal Transport (OT) technique serving as a metric of similarity between discrete empirical probability measures to provide pseudo-labels for the unlabeled data, which can then be used in conjunction with the initial labeled data to train the CNN model in an SSL manner. We have evaluated and compared our proposed method with state-of-the-art SSL algorithms on standard datasets to demonstrate the superiority and effectiveness of our SSL algorithm.
Quality Guided Sketch-to-Photo Image Synthesis
Apr 20, 2020
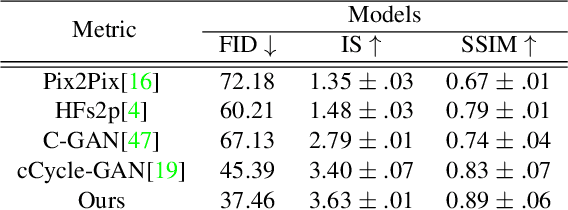
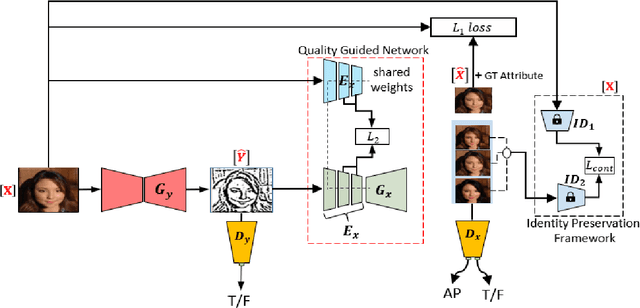
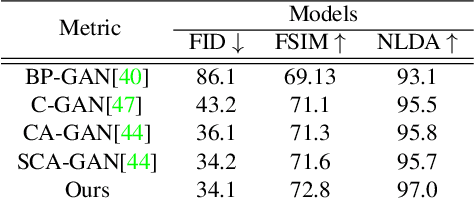
Facial sketches drawn by artists are widely used for visual identification applications and mostly by law enforcement agencies, but the quality of these sketches depend on the ability of the artist to clearly replicate all the key facial features that could aid in capturing the true identity of a subject. Recent works have attempted to synthesize these sketches into plausible visual images to improve visual recognition and identification. However, synthesizing photo-realistic images from sketches proves to be an even more challenging task, especially for sensitive applications such as suspect identification. In this work, we propose a novel approach that adopts a generative adversarial network that synthesizes a single sketch into multiple synthetic images with unique attributes like hair color, sex, etc. We incorporate a hybrid discriminator which performs attribute classification of multiple target attributes, a quality guided encoder that minimizes the perceptual dissimilarity of the latent space embedding of the synthesized and real image at different layers in the network and an identity preserving network that maintains the identity of the synthesised image throughout the training process. Our approach is aimed at improving the visual appeal of the synthesised images while incorporating multiple attribute assignment to the generator without compromising the identity of the synthesised image. We synthesised sketches using XDOG filter for the CelebA, WVU Multi-modal and CelebA-HQ datasets and from an auxiliary generator trained on sketches from CUHK, IIT-D and FERET datasets. Our results are impressive compared to current state of the art.
Robust Facial Landmark Detection via Aggregation on Geometrically Manipulated Faces
Jan 07, 2020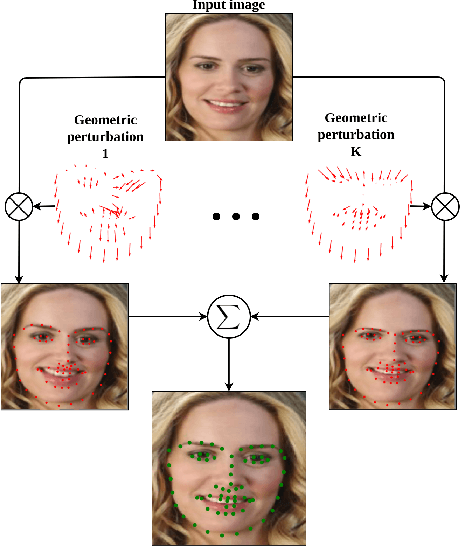

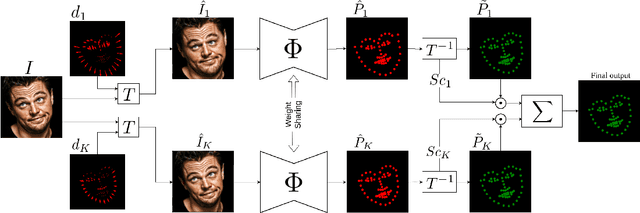

In this work, we present a practical approach to the problem of facial landmark detection. The proposed method can deal with large shape and appearance variations under the rich shape deformation. To handle the shape variations we equip our method with the aggregation of manipulated face images. The proposed framework generates different manipulated faces using only one given face image. The approach utilizes the fact that small but carefully crafted geometric manipulation in the input domain can fool deep face recognition models. We propose three different approaches to generate manipulated faces in which two of them perform the manipulations via adversarial attacks and the other one uses known transformations. Aggregating the manipulated faces provides a more robust landmark detection approach which is able to capture more important deformations and variations of the face shapes. Our approach is demonstrated its superiority compared to the state-of-the-art method on benchmark datasets AFLW, 300-W, and COFW.
Identity-Aware Deep Face Hallucination via Adversarial Face Verification
Sep 17, 2019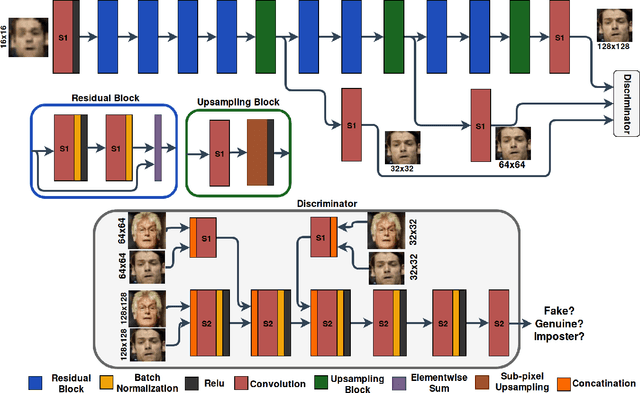
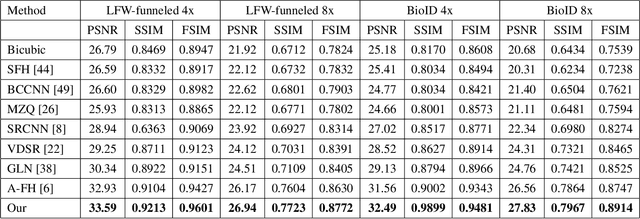

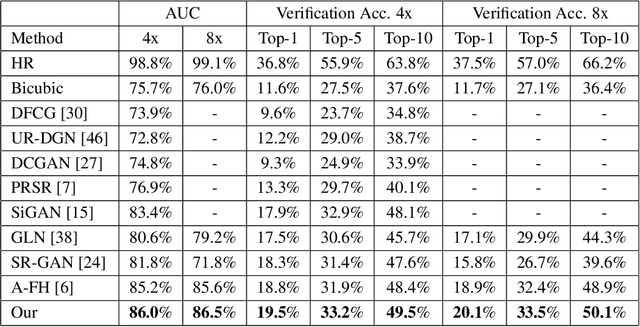
In this paper, we address the problem of face hallucination by proposing a novel multi-scale generative adversarial network (GAN) architecture optimized for face verification. First, we propose a multi-scale generator architecture for face hallucination with a high up-scaling ratio factor, which has multiple intermediate outputs at different resolutions. The intermediate outputs have the growing goal of synthesizing small to large images. Second, we incorporate a face verifier with the original GAN discriminator and propose a novel discriminator which learns to discriminate different identities while distinguishing fake generated HR face images from their ground truth images. In particular, the learned generator cares for not only the visual quality of hallucinated face images but also preserving the discriminative features in the hallucination process. In addition, to capture perceptually relevant differences we employ a perceptual similarity loss, instead of similarity in pixel space. We perform a quantitative and qualitative evaluation of our framework on the LFW and CelebA datasets. The experimental results show the advantages of our proposed method against the state-of-the-art methods on the 8x downsampled testing dataset.
A data-driven proxy to Stoke's flow in porous media
Apr 25, 2019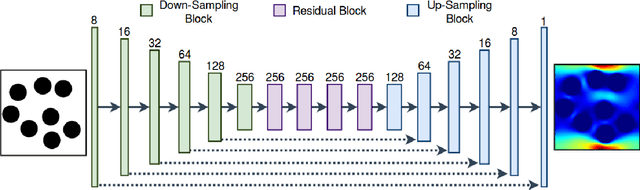
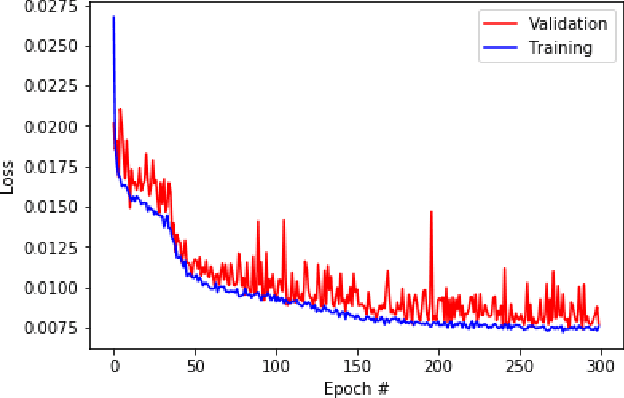
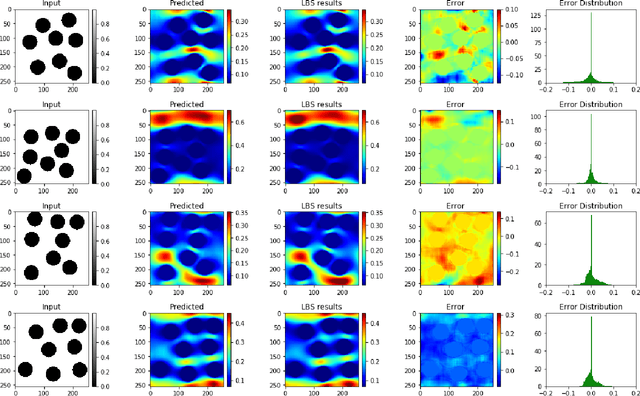
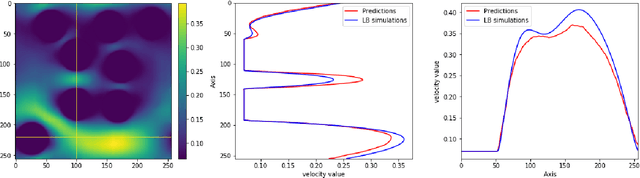
The objective for this work is to develop a data-driven proxy to high-fidelity numerical flow simulations using digital images. The proposed model can capture the flow field and permeability in a large verity of digital porous media based on solid grain geometry and pore size distribution by detailed analyses of the local pore geometry and the local flow fields. To develop the model, the detailed pore space geometry and simulation runs data from 3500 two-dimensional high-fidelity Lattice Boltzmann simulation runs are used to train and to predict the solutions with a high accuracy in much less computational time. The proposed methodology harness the enormous amount of generated data from high-fidelity flow simulations to decode the often under-utilized patterns in simulations and to accurately predict solutions to new cases. The developed model can truly capture the physics of the problem and enhance prediction capabilities of the simulations at a much lower cost. These predictive models, in essence, do not spatio-temporally reduce the order of the problem. They, however, possess the same numerical resolutions as their Lattice Boltzmann simulations equivalents do with the great advantage that their solutions can be achieved by significant reduction in computational costs (speed and memory).
Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Nov 29, 2018
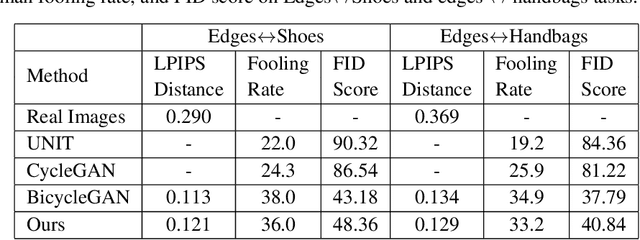
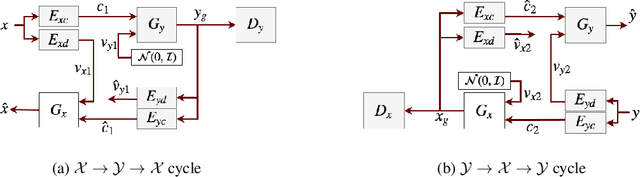
Unsupervised image-to-image translation is a class of computer vision problems which aims at modeling conditional distribution of images in the target domain, given a set of unpaired images in the source and target domains. An image in the source domain might have multiple representations in the target domain. Therefore, ambiguity in modeling of the conditional distribution arises, specially when the images in the source and target domains come from different modalities. Current approaches mostly rely on simplifying assumptions to map both domains into a shared-latent space. Consequently, they are only able to model the domain-invariant information between the two modalities. These approaches usually fail to model domain-specific information which has no representation in the target domain. In this work, we propose an unsupervised image-to-image translation framework which maximizes a domain-specific variational information bound and learns the target domain-invariant representation of the two domain. The proposed framework makes it possible to map a single source image into multiple images in the target domain, utilizing several target domain-specific codes sampled randomly from the prior distribution, or extracted from reference images.
Style and Content Disentanglement in Generative Adversarial Networks
Nov 14, 2018
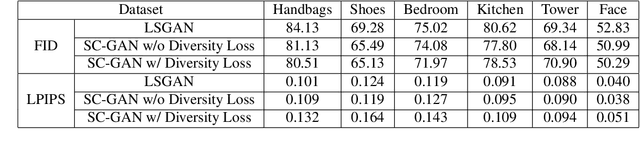
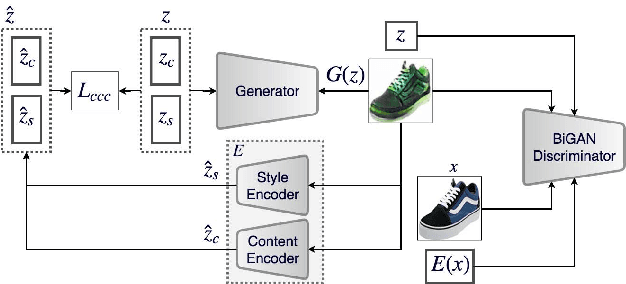
Disentangling factors of variation within data has become a very challenging problem for image generation tasks. Current frameworks for training a Generative Adversarial Network (GAN), learn to disentangle the representations of the data in an unsupervised fashion and capture the most significant factors of the data variations. However, these approaches ignore the principle of content and style disentanglement in image generation, which means their learned latent code may alter the content and style of the generated images at the same time. This paper describes the Style and Content Disentangled GAN (SC-GAN), a new unsupervised algorithm for training GANs that learns disentangled style and content representations of the data. We assume that the representation of an image can be decomposed into a content code that represents the geometrical information of the data, and a style code that captures textural properties. Consequently, by fixing the style portion of the latent representation, we can generate diverse images in a particular style. Reversely, we can set the content code and generate a specific scene in a variety of styles. The proposed SC-GAN has two components: a content code which is the input to the generator, and a style code which modifies the scene style through modification of the Adaptive Instance Normalization (AdaIN) layers' parameters. We evaluate the proposed SC-GAN framework on a set of baseline datasets.
Unsupervised Facial Geometry Learning for Sketch to Photo Synthesis
Oct 12, 2018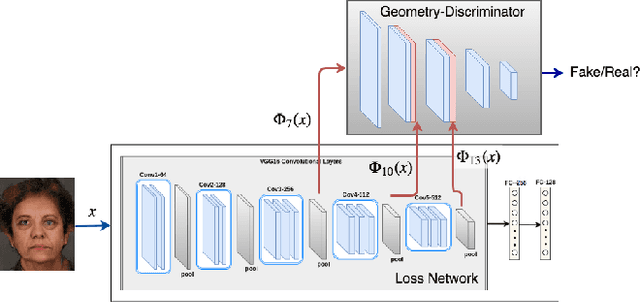
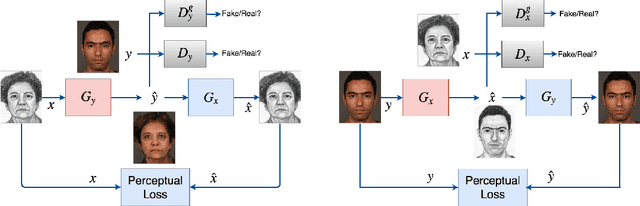

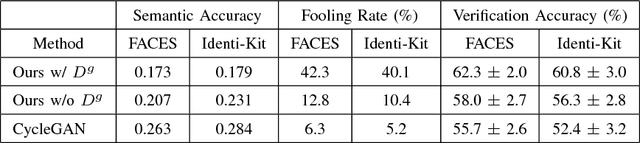
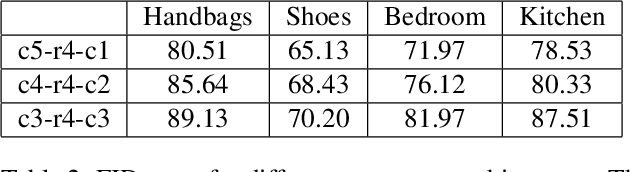
Face sketch-photo synthesis is a critical application in law enforcement and digital entertainment industry where the goal is to learn the mapping between a face sketch image and its corresponding photo-realistic image. However, the limited number of paired sketch-photo training data usually prevents the current frameworks to learn a robust mapping between the geometry of sketches and their matching photo-realistic images. Consequently, in this work, we present an approach for learning to synthesize a photo-realistic image from a face sketch in an unsupervised fashion. In contrast to current unsupervised image-to-image translation techniques, our framework leverages a novel perceptual discriminator to learn the geometry of human face. Learning facial prior information empowers the network to remove the geometrical artifacts in the face sketch. We demonstrate that a simultaneous optimization of the face photo generator network, employing the proposed perceptual discriminator in combination with a texture-wise discriminator, results in a significant improvement in quality and recognition rate of the synthesized photos. We evaluate the proposed network by conducting extensive experiments on multiple baseline sketch-photo datasets.
A Learning-Based Framework for Two-Dimensional Vehicle Maneuver Prediction over V2V Networks
Aug 01, 2018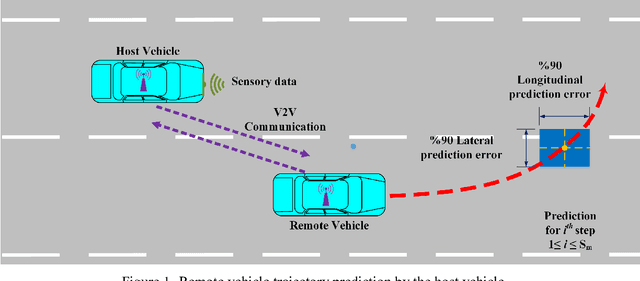
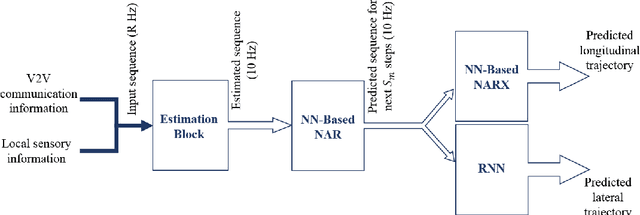
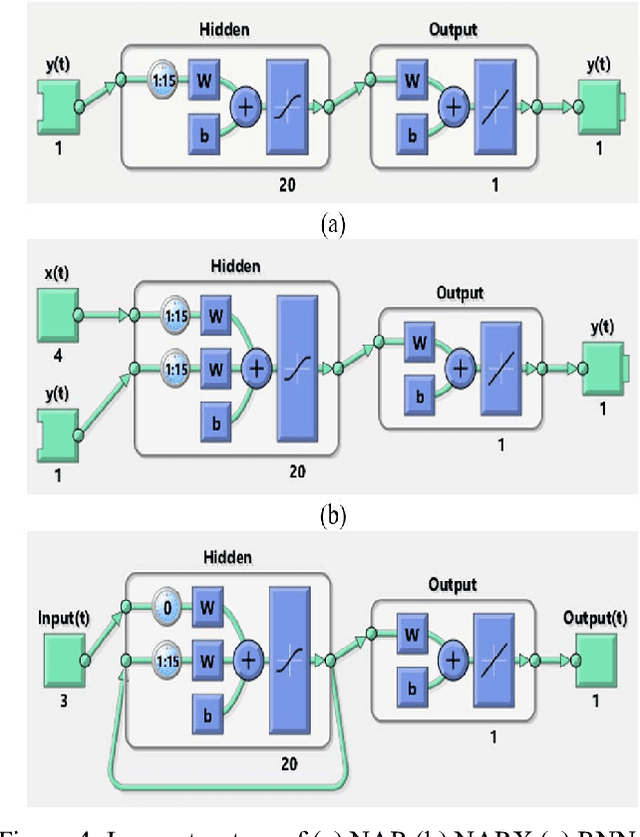

Situational awareness in vehicular networks could be substantially improved utilizing reliable trajectory prediction methods. More precise situational awareness, in turn, results in notably better performance of critical safety applications, such as Forward Collision Warning (FCW), as well as comfort applications like Cooperative Adaptive Cruise Control (CACC). Therefore, vehicle trajectory prediction problem needs to be deeply investigated in order to come up with an end to end framework with enough precision required by the safety applications' controllers. This problem has been tackled in the literature using different methods. However, machine learning, which is a promising and emerging field with remarkable potential for time series prediction, has not been explored enough for this purpose. In this paper, a two-layer neural network-based system is developed which predicts the future values of vehicle parameters, such as velocity, acceleration, and yaw rate, in the first layer and then predicts the two-dimensional, i.e. longitudinal and lateral, trajectory points based on the first layer's outputs. The performance of the proposed framework has been evaluated in realistic cut-in scenarios from Safety Pilot Model Deployment (SPMD) dataset and the results show a noticeable improvement in the prediction accuracy in comparison with the kinematics model which is the dominant employed model by the automotive industry. Both ideal and nonideal communication circumstances have been investigated for our system evaluation. For non-ideal case, an estimation step is included in the framework before the parameter prediction block to handle the drawbacks of packet drops or sensor failures and reconstruct the time series of vehicle parameters at a desirable frequency.