 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Outer Optimization in Adversarial Training
Sep 02, 2022
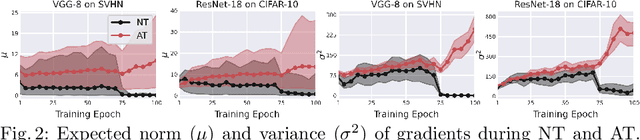
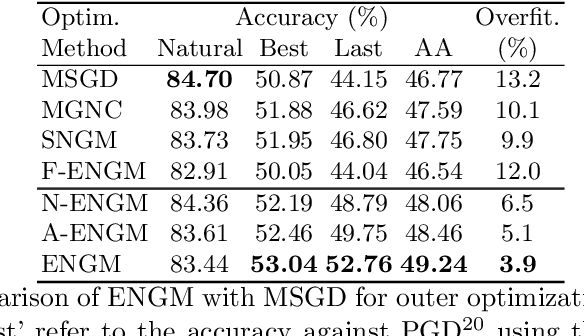

Despite the fundamental distinction between adversarial and natural training (AT and NT), AT methods generally adopt momentum SGD (MSGD) for the outer optimization. This paper aims to analyze this choice by investigating the overlooked role of outer optimization in AT. Our exploratory evaluations reveal that AT induces higher gradient norm and variance compared to NT. This phenomenon hinders the outer optimization in AT since the convergence rate of MSGD is highly dependent on the variance of the gradients. To this end, we propose an optimization method called ENGM which regularizes the contribution of each input example to the average mini-batch gradients. We prove that the convergence rate of ENGM is independent of the variance of the gradients, and thus, it is suitable for AT. We introduce a trick to reduce the computational cost of ENGM using empirical observations on the correlation between the norm of gradients w.r.t. the network parameters and input examples. Our extensive evaluations and ablation studies on CIFAR-10, CIFAR-100, and TinyImageNet demonstrate that ENGM and its variants consistently improve the performance of a wide range of AT methods. Furthermore, ENGM alleviates major shortcomings of AT including robust overfitting and high sensitivity to hyperparameter settings.
Controllable 3D Generative Adversarial Face Model via Disentangling Shape and Appearance
Aug 30, 2022
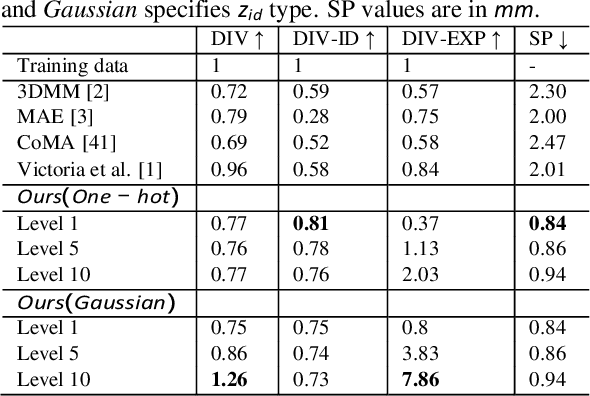
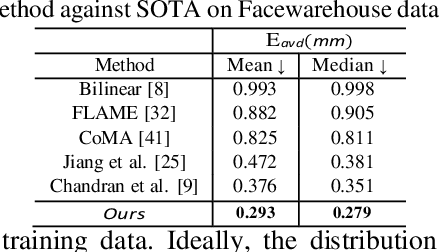
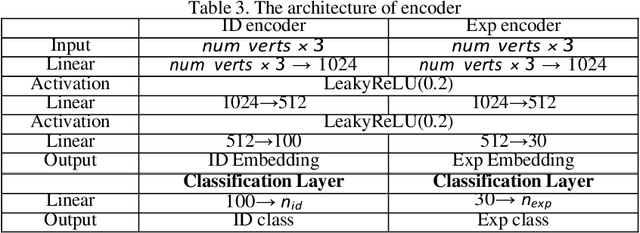
3D face modeling has been an active area of research in computer vision and computer graphics, fueling applications ranging from facial expression transfer in virtual avatars to synthetic data generation. Existing 3D deep learning generative models (e.g., VAE, GANs) allow generating compact face representations (both shape and texture) that can model non-linearities in the shape and appearance space (e.g., scatter effects, specularities, etc.). However, they lack the capability to control the generation of subtle expressions. This paper proposes a new 3D face generative model that can decouple identity and expression and provides granular control over expressions. In particular, we propose using a pair of supervised auto-encoder and generative adversarial networks to produce high-quality 3D faces, both in terms of appearance and shape. Experimental results in the generation of 3D faces learned with holistic expression labels, or Action Unit labels, show how we can decouple identity and expression; gaining fine-control over expressions while preserving identity.
Quality-Aware Multimodal Biometric Recognition
Dec 10, 2021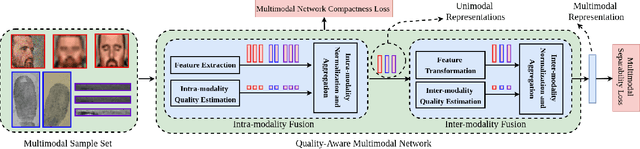
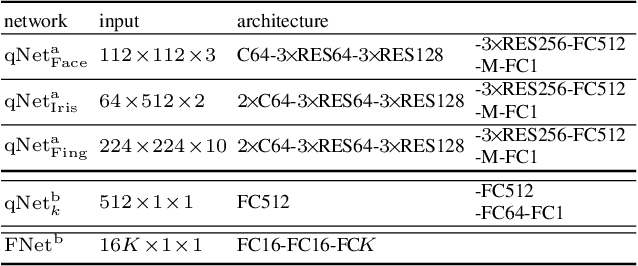
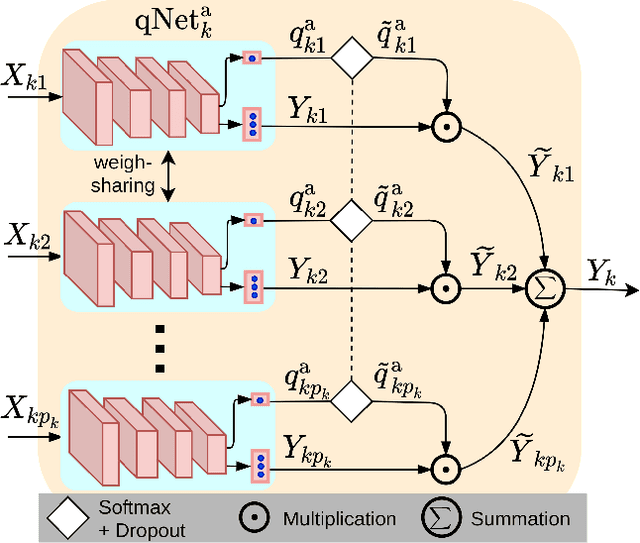
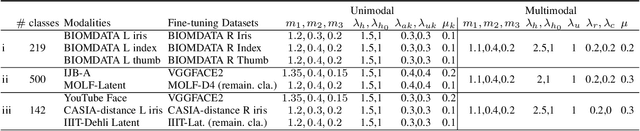
We present a quality-aware multimodal recognition framework that combines representations from multiple biometric traits with varying quality and number of samples to achieve increased recognition accuracy by extracting complimentary identification information based on the quality of the samples. We develop a quality-aware framework for fusing representations of input modalities by weighting their importance using quality scores estimated in a weakly-supervised fashion. This framework utilizes two fusion blocks, each represented by a set of quality-aware and aggregation networks. In addition to architecture modifications, we propose two task-specific loss functions: multimodal separability loss and multimodal compactness loss. The first loss assures that the representations of modalities for a class have comparable magnitudes to provide a better quality estimation, while the multimodal representations of different classes are distributed to achieve maximum discrimination in the embedding space. The second loss, which is considered to regularize the network weights, improves the generalization performance by regularizing the framework. We evaluate the performance by considering three multimodal datasets consisting of face, iris, and fingerprint modalities. The efficacy of the framework is demonstrated through comparison with the state-of-the-art algorithms. In particular, our framework outperforms the rank- and score-level fusion of modalities of BIOMDATA by more than 30% for true acceptance rate at false acceptance rate of $10^{-4}$.
Tasks Structure Regularization in Multi-Task Learning for Improving Facial Attribute Prediction
Aug 18, 2021
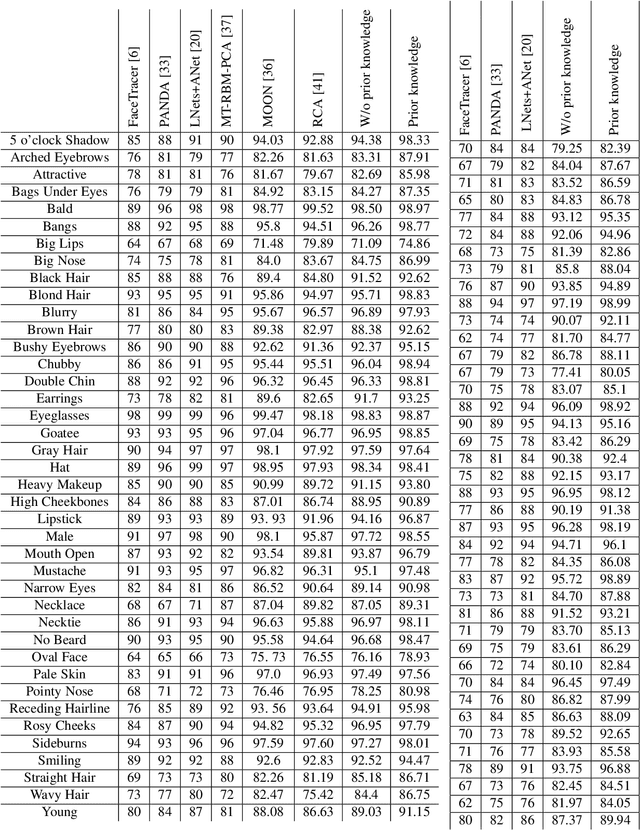
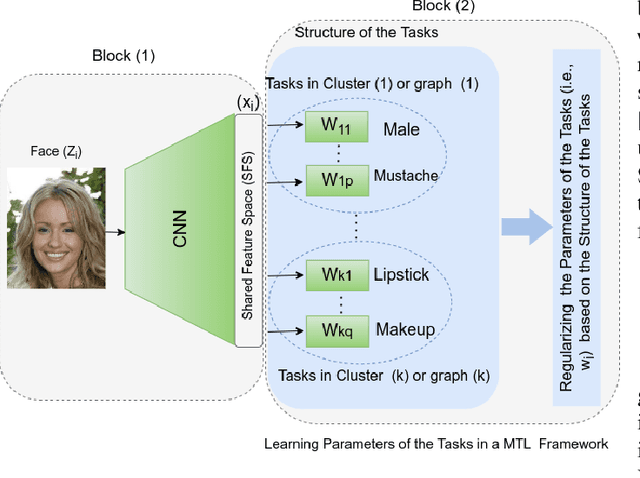
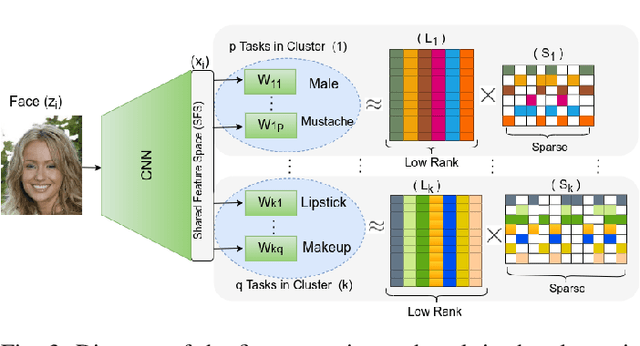
The great success of Convolutional Neural Networks (CNN) for facial attribute prediction relies on a large amount of labeled images. Facial image datasets are usually annotated by some commonly used attributes (e.g., gender), while labels for the other attributes (e.g., big nose) are limited which causes their prediction challenging. To address this problem, we use a new Multi-Task Learning (MTL) paradigm in which a facial attribute predictor uses the knowledge of other related attributes to obtain a better generalization performance. Here, we leverage MLT paradigm in two problem settings. First, it is assumed that the structure of the tasks (e.g., grouping pattern of facial attributes) is known as a prior knowledge, and parameters of the tasks (i.e., predictors) within the same group are represented by a linear combination of a limited number of underlying basis tasks. Here, a sparsity constraint on the coefficients of this linear combination is also considered such that each task is represented in a more structured and simpler manner. Second, it is assumed that the structure of the tasks is unknown, and then structure and parameters of the tasks are learned jointly by using a Laplacian regularization framework. Our MTL methods are compared with competing methods for facial attribute prediction to show its effectiveness.
Profile to Frontal Face Recognition in the Wild Using Coupled Conditional GAN
Jul 29, 2021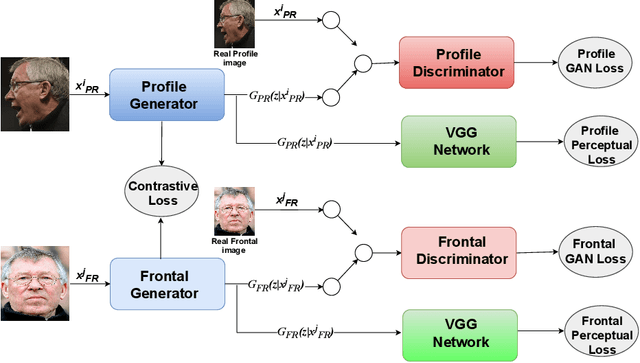
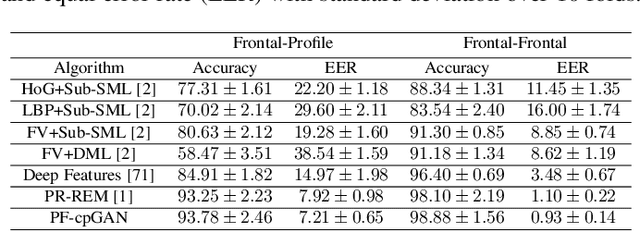
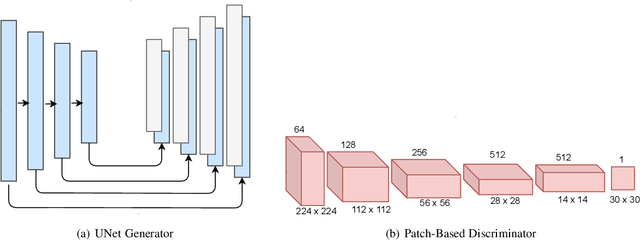
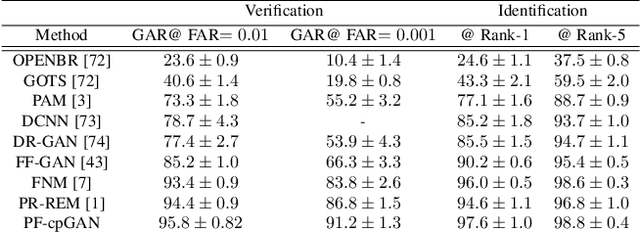
In recent years, with the advent of deep-learning, face recognition has achieved exceptional success. However, many of these deep face recognition models perform much better in handling frontal faces compared to profile faces. The major reason for poor performance in handling of profile faces is that it is inherently difficult to learn pose-invariant deep representations that are useful for profile face recognition. In this paper, we hypothesize that the profile face domain possesses a latent connection with the frontal face domain in a latent feature subspace. We look to exploit this latent connection by projecting the profile faces and frontal faces into a common latent subspace and perform verification or retrieval in the latent domain. We leverage a coupled conditional generative adversarial network (cpGAN) structure to find the hidden relationship between the profile and frontal images in a latent common embedding subspace. Specifically, the cpGAN framework consists of two conditional GAN-based sub-networks, one dedicated to the frontal domain and the other dedicated to the profile domain. Each sub-network tends to find a projection that maximizes the pair-wise correlation between the two feature domains in a common embedding feature subspace. The efficacy of our approach compared with the state-of-the-art is demonstrated using the CFP, CMU Multi-PIE, IJB-A, and IJB-C datasets. Additionally, we have also implemented a coupled convolutional neural network (cpCNN) and an adversarial discriminative domain adaptation network (ADDA) for profile to frontal face recognition. We have evaluated the performance of cpCNN and ADDA and compared it with the proposed cpGAN. Finally, we have also evaluated our cpGAN for reconstruction of frontal faces from input profile faces contained in the VGGFace2 dataset.
Attribute Guided Sparse Tensor-Based Model for Person Re-Identification
Jul 29, 2021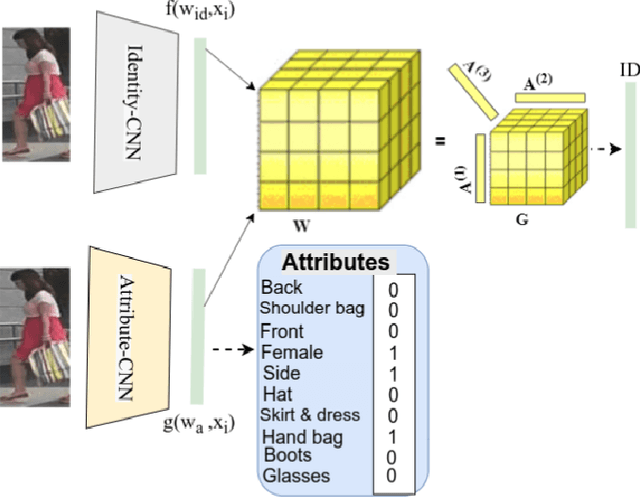

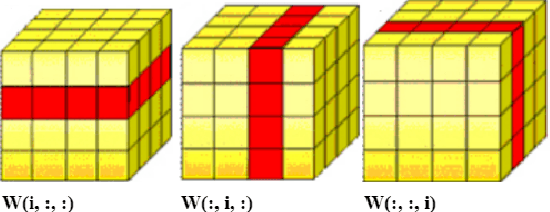

Visual perception of a person is easily influenced by many factors such as camera parameters, pose and viewpoint variations. These variations make person Re-Identification (ReID) a challenging problem. Nevertheless, human attributes usually stand as robust visual properties to such variations. In this paper, we propose a new method to leverage features from human attributes for person ReID. Our model uses a tensor to non-linearly fuse identity and attribute features, and then forces the parameters of the tensor in the loss function to generate discriminative fused features for ReID. Since tensor-based methods usually contain a large number of parameters, training all of these parameters becomes very slow, and the chance of overfitting increases as well. To address this issue, we propose two new techniques based on Structural Sparsity Learning (SSL) and Tensor Decomposition (TD) methods to create an accurate and stable learning problem. We conducted experiments on several standard pedestrian datasets, and experimental results indicate that our tensor-based approach significantly improves person ReID baselines and also outperforms state of the art methods.
Matching Distributions via Optimal Transport for Semi-Supervised Learning
Dec 04, 2020
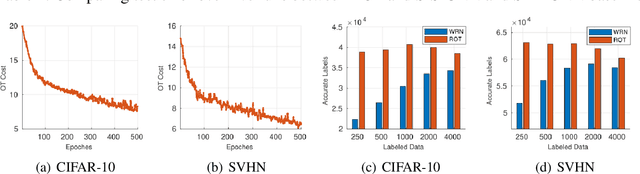
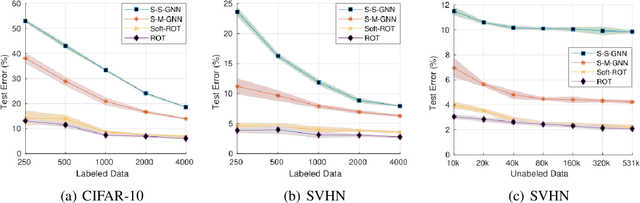
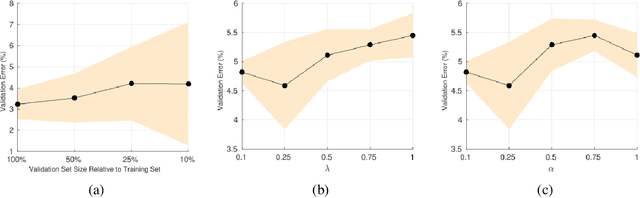
Semi-Supervised Learning (SSL) approaches have been an influential framework for the usage of unlabeled data when there is not a sufficient amount of labeled data available over the course of training. SSL methods based on Convolutional Neural Networks (CNNs) have recently provided successful results on standard benchmark tasks such as image classification. In this work, we consider the general setting of SSL problem where the labeled and unlabeled data come from the same underlying probability distribution. We propose a new approach that adopts an Optimal Transport (OT) technique serving as a metric of similarity between discrete empirical probability measures to provide pseudo-labels for the unlabeled data, which can then be used in conjunction with the initial labeled data to train the CNN model in an SSL manner. We have evaluated and compared our proposed method with state-of-the-art SSL algorithms on standard datasets to demonstrate the superiority and effectiveness of our SSL algorithm.
Mutual Information Maximization on Disentangled Representations for Differential Morph Detection
Dec 02, 2020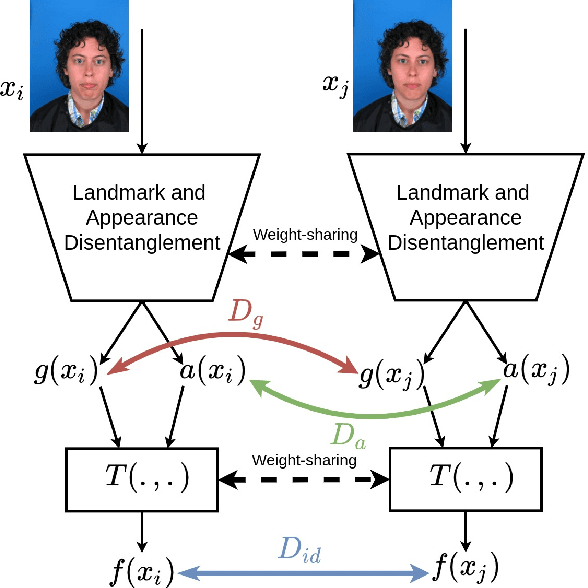
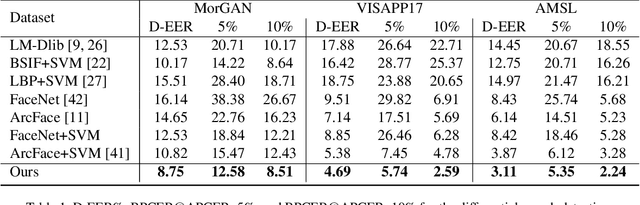
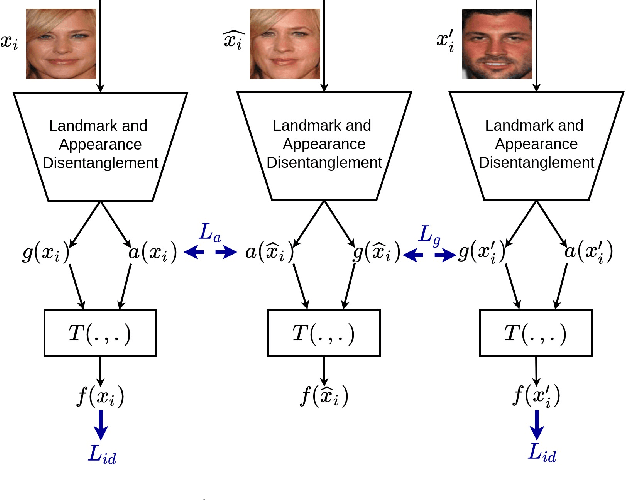
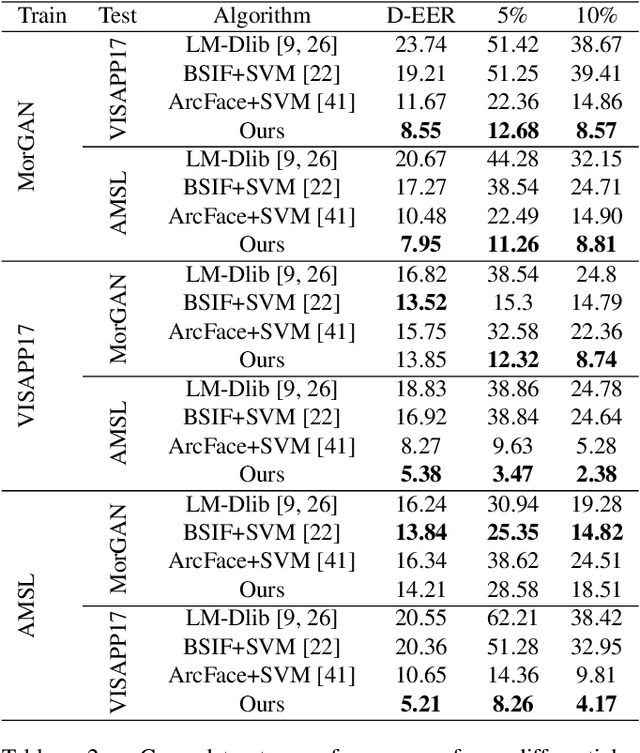
In this paper, we present a novel differential morph detection framework, utilizing landmark and appearance disentanglement. In our framework, the face image is represented in the embedding domain using two disentangled but complementary representations. The network is trained by triplets of face images, in which the intermediate image inherits the landmarks from one image and the appearance from the other image. This initially trained network is further trained for each dataset using contrastive representations. We demonstrate that, by employing appearance and landmark disentanglement, the proposed framework can provide state-of-the-art differential morph detection performance. This functionality is achieved by the using distances in landmark, appearance, and ID domains. The performance of the proposed framework is evaluated using three morph datasets generated with different methodologies.
Cross-Spectral Iris Matching Using Conditional Coupled GAN
Oct 09, 2020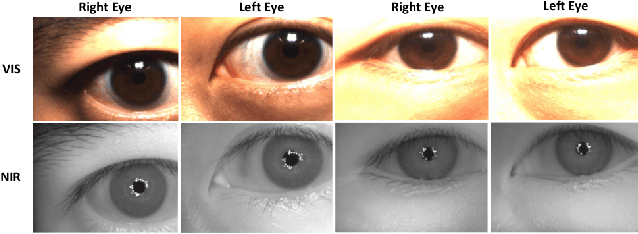
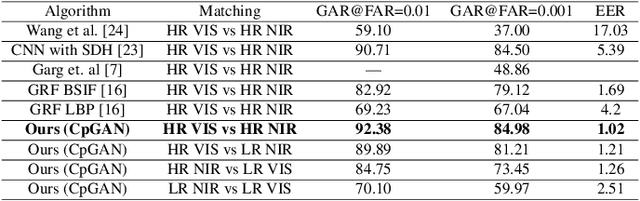
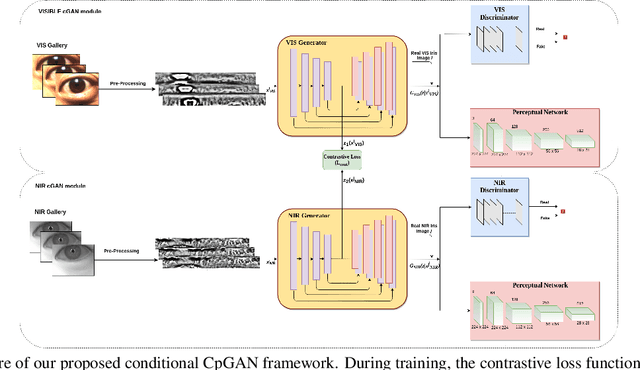

Cross-spectral iris recognition is emerging as a promising biometric approach to authenticating the identity of individuals. However, matching iris images acquired at different spectral bands shows significant performance degradation when compared to single-band near-infrared (NIR) matching due to the spectral gap between iris images obtained in the NIR and visual-light (VIS) spectra. Although researchers have recently focused on deep-learning-based approaches to recover invariant representative features for more accurate recognition performance, the existing methods cannot achieve the expected accuracy required for commercial applications. Hence, in this paper, we propose a conditional coupled generative adversarial network (CpGAN) architecture for cross-spectral iris recognition by projecting the VIS and NIR iris images into a low-dimensional embedding domain to explore the hidden relationship between them. The conditional CpGAN framework consists of a pair of GAN-based networks, one responsible for retrieving images in the visible domain and other responsible for retrieving images in the NIR domain. Both networks try to map the data into a common embedding subspace to ensure maximum pair-wise similarity between the feature vectors from the two iris modalities of the same subject. To prove the usefulness of our proposed approach, extensive experimental results obtained on the PolyU dataset are compared to existing state-of-the-art cross-spectral recognition methods.
PF-cpGAN: Profile to Frontal Coupled GAN for Face Recognition in the Wild
Apr 25, 2020
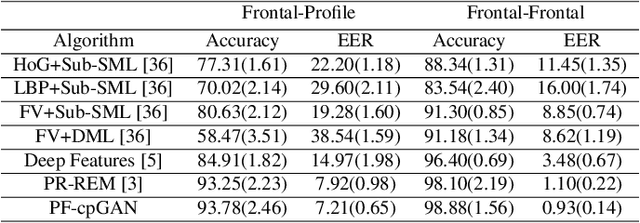
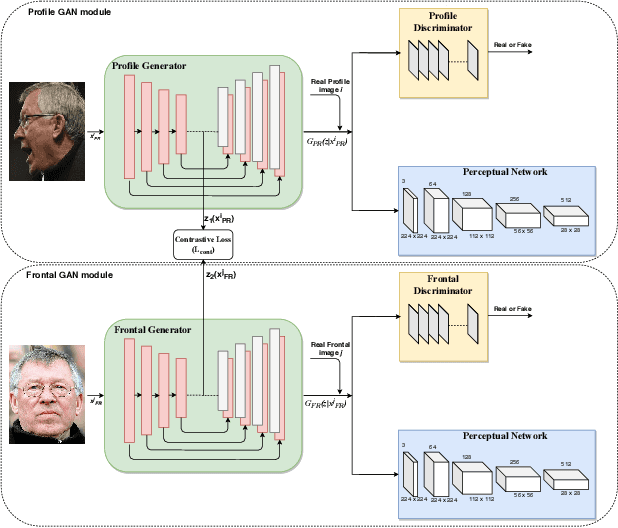
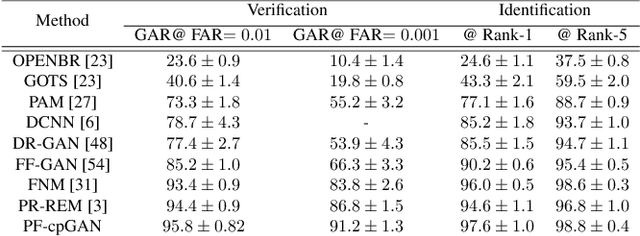
In recent years, due to the emergence of deep learning, face recognition has achieved exceptional success. However, many of these deep face recognition models perform relatively poorly in handling profile faces compared to frontal faces. The major reason for this poor performance is that it is inherently difficult to learn large pose invariant deep representations that are useful for profile face recognition. In this paper, we hypothesize that the profile face domain possesses a gradual connection with the frontal face domain in the deep feature space. We look to exploit this connection by projecting the profile faces and frontal faces into a common latent space and perform verification or retrieval in the latent domain. We leverage a coupled generative adversarial network (cpGAN) structure to find the hidden relationship between the profile and frontal images in a latent common embedding subspace. Specifically, the cpGAN framework consists of two GAN-based sub-networks, one dedicated to the frontal domain and the other dedicated to the profile domain. Each sub-network tends to find a projection that maximizes the pair-wise correlation between two feature domains in a common embedding feature subspace. The efficacy of our approach compared with the state-of-the-art is demonstrated using the CFP, CMU MultiPIE, IJB-A, and IJB-C datasets.