 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Outer Optimization in Adversarial Training
Paper and Code

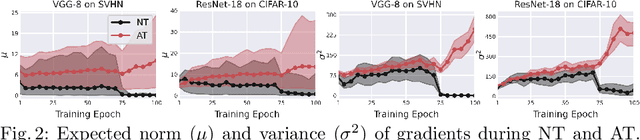
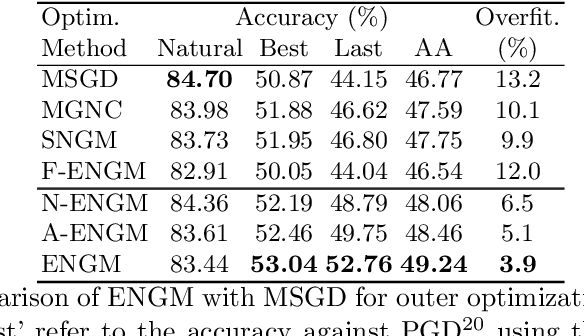

Despite the fundamental distinction between adversarial and natural training (AT and NT), AT methods generally adopt momentum SGD (MSGD) for the outer optimization. This paper aims to analyze this choice by investigating the overlooked role of outer optimization in AT. Our exploratory evaluations reveal that AT induces higher gradient norm and variance compared to NT. This phenomenon hinders the outer optimization in AT since the convergence rate of MSGD is highly dependent on the variance of the gradients. To this end, we propose an optimization method called ENGM which regularizes the contribution of each input example to the average mini-batch gradients. We prove that the convergence rate of ENGM is independent of the variance of the gradients, and thus, it is suitable for AT. We introduce a trick to reduce the computational cost of ENGM using empirical observations on the correlation between the norm of gradients w.r.t. the network parameters and input examples. Our extensive evaluations and ablation studies on CIFAR-10, CIFAR-100, and TinyImageNet demonstrate that ENGM and its variants consistently improve the performance of a wide range of AT methods. Furthermore, ENGM alleviates major shortcomings of AT including robust overfitting and high sensitivity to hyperparameter settings.