 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandmark Enforcement and Style Manipulation for Generative Morphing
Oct 18, 2022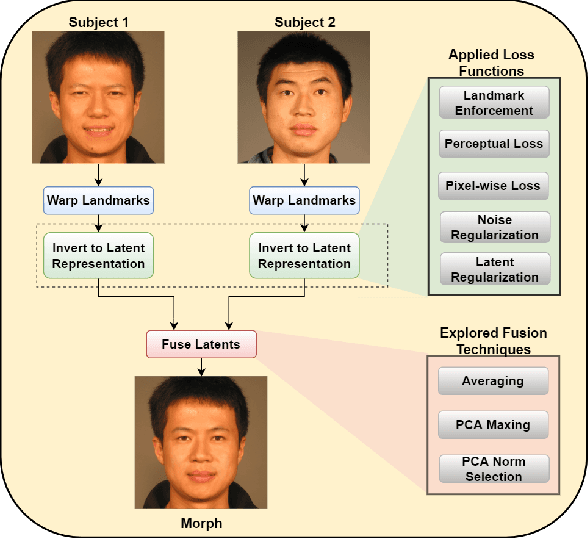
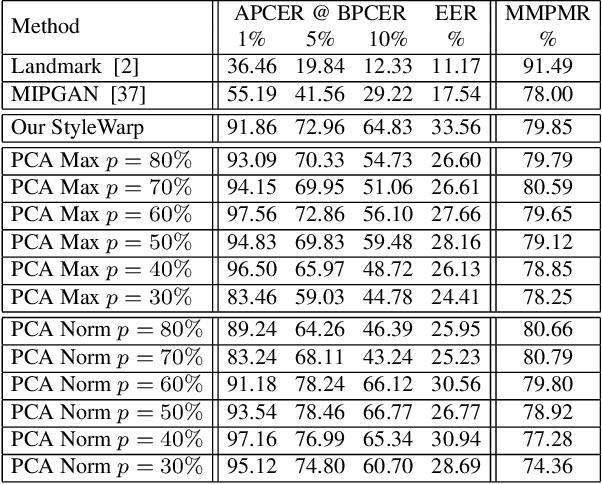


Morph images threaten Facial Recognition Systems (FRS) by presenting as multiple individuals, allowing an adversary to swap identities with another subject. Morph generation using generative adversarial networks (GANs) results in high-quality morphs unaffected by the spatial artifacts caused by landmark-based methods, but there is an apparent loss in identity with standard GAN-based morphing methods. In this paper, we propose a novel StyleGAN morph generation technique by introducing a landmark enforcement method to resolve this issue. Considering this method, we aim to enforce the landmarks of the morph image to represent the spatial average of the landmarks of the bona fide faces and subsequently the morph images to inherit the geometric identity of both bona fide faces. Exploration of the latent space of our model is conducted using Principal Component Analysis (PCA) to accentuate the effect of both the bona fide faces on the morphed latent representation and address the identity loss issue with latent domain averaging. Additionally, to improve high frequency reconstruction in the morphs, we study the train-ability of the noise input for the StyleGAN2 model.
Robust Ensemble Morph Detection with Domain Generalization
Sep 16, 2022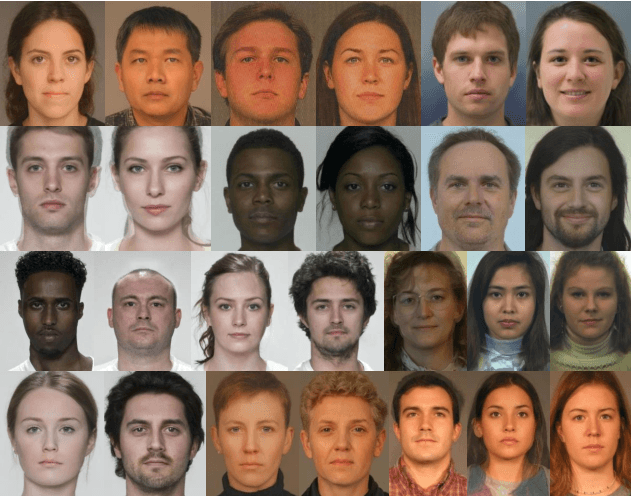
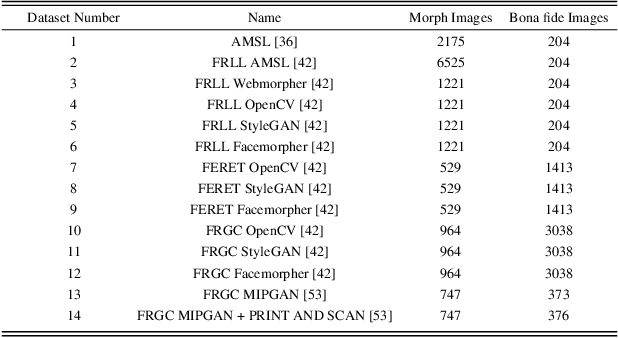
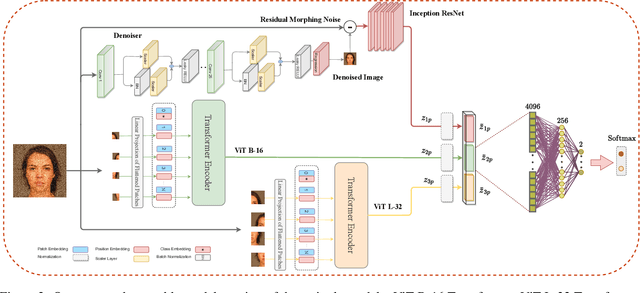
Although a substantial amount of studies is dedicated to morph detection, most of them fail to generalize for morph faces outside of their training paradigm. Moreover, recent morph detection methods are highly vulnerable to adversarial attacks. In this paper, we intend to learn a morph detection model with high generalization to a wide range of morphing attacks and high robustness against different adversarial attacks. To this aim, we develop an ensemble of convolutional neural networks (CNNs) and Transformer models to benefit from their capabilities simultaneously. To improve the robust accuracy of the ensemble model, we employ multi-perturbation adversarial training and generate adversarial examples with high transferability for several single models. Our exhaustive evaluations demonstrate that the proposed robust ensemble model generalizes to several morphing attacks and face datasets. In addition, we validate that our robust ensemble model gain better robustness against several adversarial attacks while outperforming the state-of-the-art studies.
Information Maximization for Extreme Pose Face Recognition
Sep 07, 2022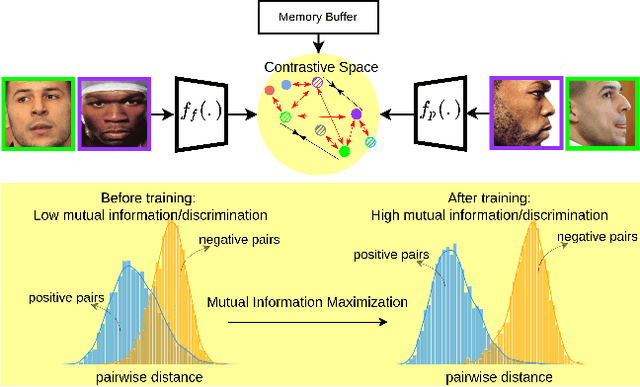
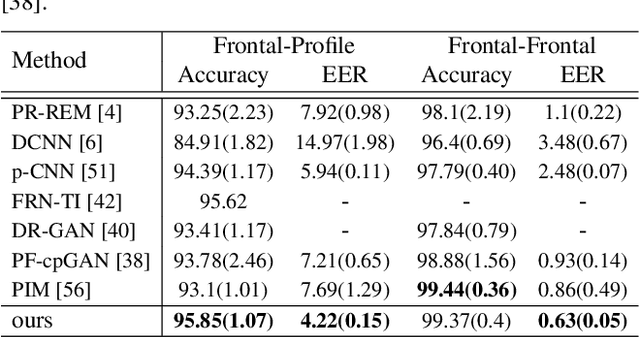
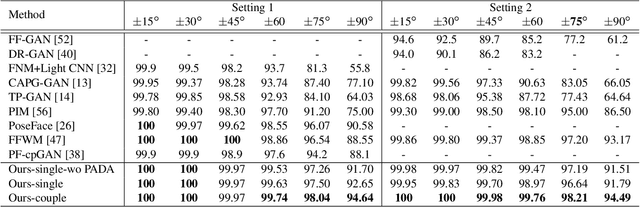
In this paper, we seek to draw connections between the frontal and profile face images in an abstract embedding space. We exploit this connection using a coupled-encoder network to project frontal/profile face images into a common latent embedding space. The proposed model forces the similarity of representations in the embedding space by maximizing the mutual information between two views of the face. The proposed coupled-encoder benefits from three contributions for matching faces with extreme pose disparities. First, we leverage our pose-aware contrastive learning to maximize the mutual information between frontal and profile representations of identities. Second, a memory buffer, which consists of latent representations accumulated over past iterations, is integrated into the model so it can refer to relatively much more instances than the mini-batch size. Third, a novel pose-aware adversarial domain adaptation method forces the model to learn an asymmetric mapping from profile to frontal representation. In our framework, the coupled-encoder learns to enlarge the margin between the distribution of genuine and imposter faces, which results in high mutual information between different views of the same identity. The effectiveness of the proposed model is investigated through extensive experiments, evaluations, and ablation studies on four benchmark datasets, and comparison with the compelling state-of-the-art algorithms.
Revisiting Outer Optimization in Adversarial Training
Sep 02, 2022
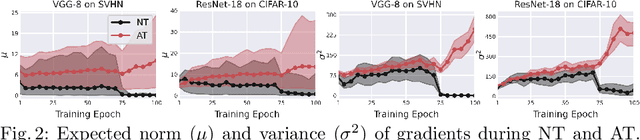
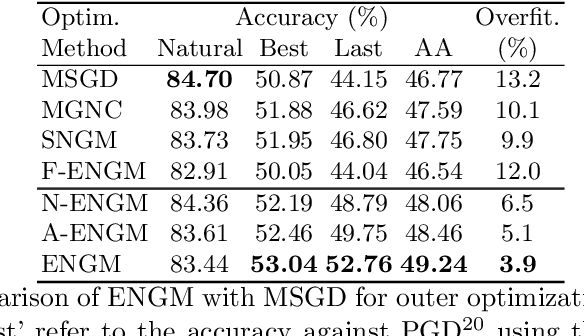

Despite the fundamental distinction between adversarial and natural training (AT and NT), AT methods generally adopt momentum SGD (MSGD) for the outer optimization. This paper aims to analyze this choice by investigating the overlooked role of outer optimization in AT. Our exploratory evaluations reveal that AT induces higher gradient norm and variance compared to NT. This phenomenon hinders the outer optimization in AT since the convergence rate of MSGD is highly dependent on the variance of the gradients. To this end, we propose an optimization method called ENGM which regularizes the contribution of each input example to the average mini-batch gradients. We prove that the convergence rate of ENGM is independent of the variance of the gradients, and thus, it is suitable for AT. We introduce a trick to reduce the computational cost of ENGM using empirical observations on the correlation between the norm of gradients w.r.t. the network parameters and input examples. Our extensive evaluations and ablation studies on CIFAR-10, CIFAR-100, and TinyImageNet demonstrate that ENGM and its variants consistently improve the performance of a wide range of AT methods. Furthermore, ENGM alleviates major shortcomings of AT including robust overfitting and high sensitivity to hyperparameter settings.
Benchmarking Human Face Similarity Using Identical Twins
Aug 25, 2022
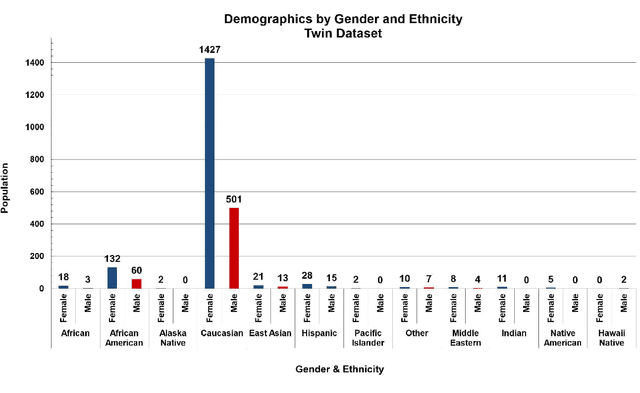
The problem of distinguishing identical twins and non-twin look-alikes in automated facial recognition (FR) applications has become increasingly important with the widespread adoption of facial biometrics. Due to the high facial similarity of both identical twins and look-alikes, these face pairs represent the hardest cases presented to facial recognition tools. This work presents an application of one of the largest twin datasets compiled to date to address two FR challenges: 1) determining a baseline measure of facial similarity between identical twins and 2) applying this similarity measure to determine the impact of doppelgangers, or look-alikes, on FR performance for large face datasets. The facial similarity measure is determined via a deep convolutional neural network. This network is trained on a tailored verification task designed to encourage the network to group together highly similar face pairs in the embedding space and achieves a test AUC of 0.9799. The proposed network provides a quantitative similarity score for any two given faces and has been applied to large-scale face datasets to identify similar face pairs. An additional analysis which correlates the comparison score returned by a facial recognition tool and the similarity score returned by the proposed network has also been performed.
Quality-Aware Multimodal Biometric Recognition
Dec 10, 2021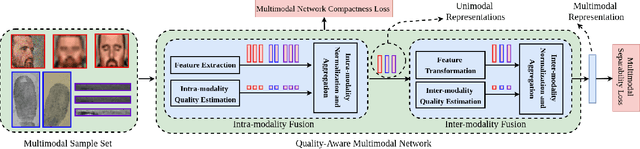
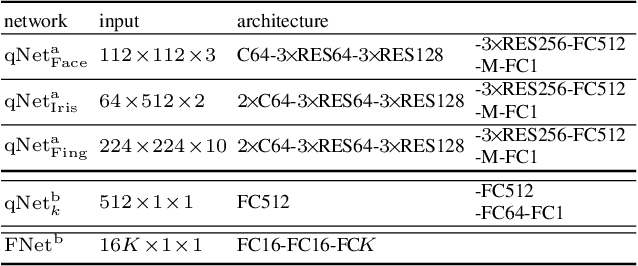
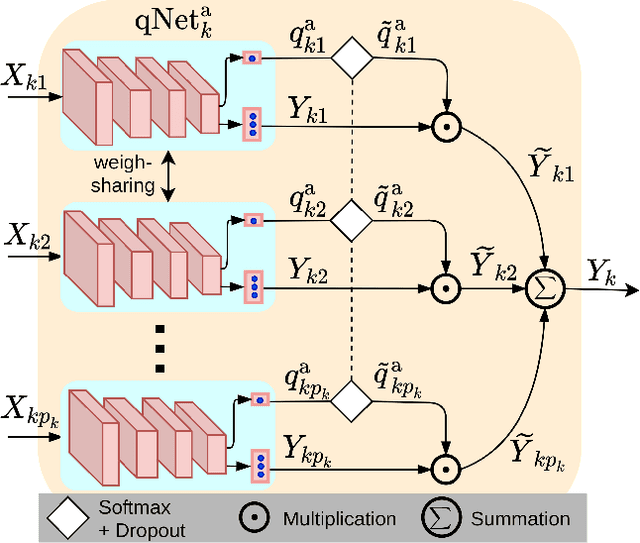
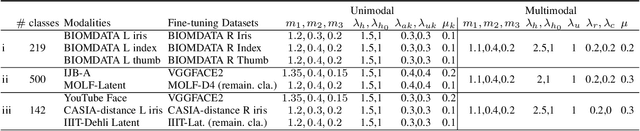
We present a quality-aware multimodal recognition framework that combines representations from multiple biometric traits with varying quality and number of samples to achieve increased recognition accuracy by extracting complimentary identification information based on the quality of the samples. We develop a quality-aware framework for fusing representations of input modalities by weighting their importance using quality scores estimated in a weakly-supervised fashion. This framework utilizes two fusion blocks, each represented by a set of quality-aware and aggregation networks. In addition to architecture modifications, we propose two task-specific loss functions: multimodal separability loss and multimodal compactness loss. The first loss assures that the representations of modalities for a class have comparable magnitudes to provide a better quality estimation, while the multimodal representations of different classes are distributed to achieve maximum discrimination in the embedding space. The second loss, which is considered to regularize the network weights, improves the generalization performance by regularizing the framework. We evaluate the performance by considering three multimodal datasets consisting of face, iris, and fingerprint modalities. The efficacy of the framework is demonstrated through comparison with the state-of-the-art algorithms. In particular, our framework outperforms the rank- and score-level fusion of modalities of BIOMDATA by more than 30% for true acceptance rate at false acceptance rate of $10^{-4}$.
Morph Detection Enhanced by Structured Group Sparsity
Nov 29, 2021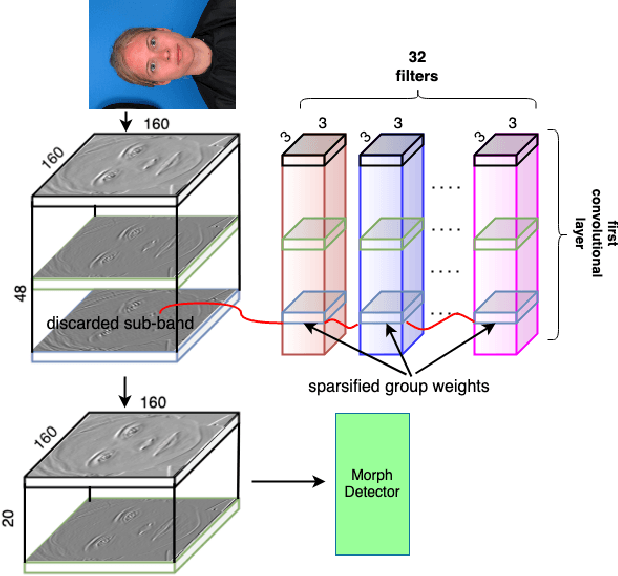
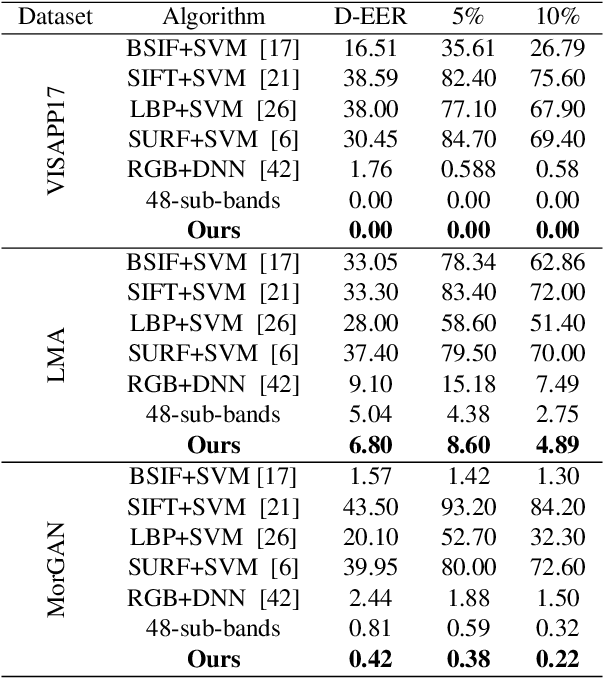
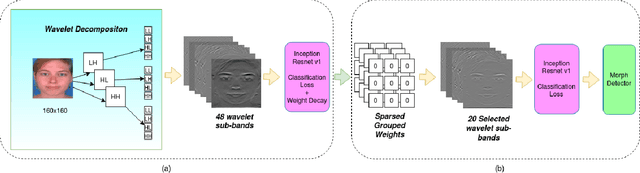
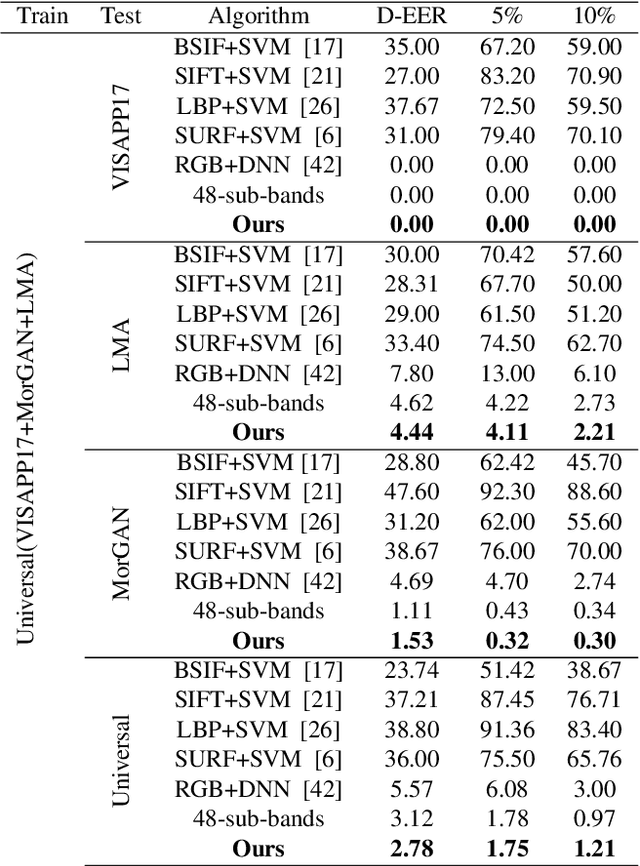
In this paper, we consider the challenge of face morphing attacks, which substantially undermine the integrity of face recognition systems such as those adopted for use in border protection agencies. Morph detection can be formulated as extracting fine-grained representations, where local discriminative features are harnessed for learning a hypothesis. To acquire discriminative features at different granularity as well as a decoupled spectral information, we leverage wavelet domain analysis to gain insight into the spatial-frequency content of a morphed face. As such, instead of using images in the RGB domain, we decompose every image into its wavelet sub-bands using 2D wavelet decomposition and a deep supervised feature selection scheme is employed to find the most discriminative wavelet sub-bands of input images. To this end, we train a Deep Neural Network (DNN) morph detector using the decomposed wavelet sub-bands of the morphed and bona fide images. In the training phase, our structured group sparsity-constrained DNN picks the most discriminative wavelet sub-bands out of all the sub-bands, with which we retrain our DNN, resulting in a precise detection of morphed images when inference is achieved on a probe image. The efficacy of our deep morph detector which is enhanced by structured group lasso is validated through experiments on three facial morph image databases, i.e., VISAPP17, LMA, and MorGAN.
Adversarially Perturbed Wavelet-based Morphed Face Generation
Nov 03, 2021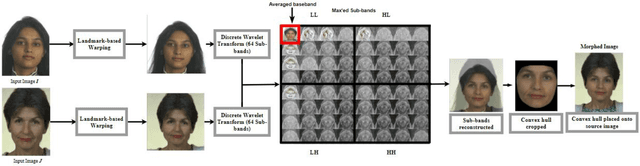
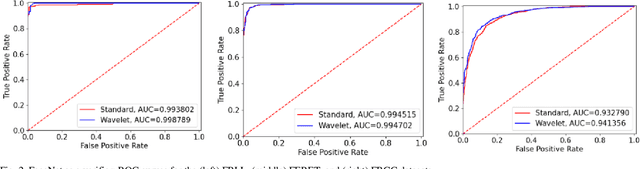
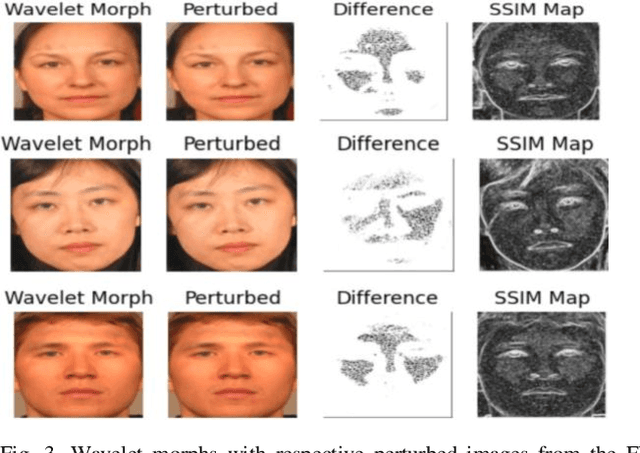
Morphing is the process of combining two or more subjects in an image in order to create a new identity which contains features of both individuals. Morphed images can fool Facial Recognition Systems (FRS) into falsely accepting multiple people, leading to failures in national security. As morphed image synthesis becomes easier, it is vital to expand the research community's available data to help combat this dilemma. In this paper, we explore combination of two methods for morphed image generation, those of geometric transformation (warping and blending to create morphed images) and photometric perturbation. We leverage both methods to generate high-quality adversarially perturbed morphs from the FERET, FRGC, and FRLL datasets. The final images retain high similarity to both input subjects while resulting in minimal artifacts in the visual domain. Images are synthesized by fusing the wavelet sub-bands from the two look-alike subjects, and then adversarially perturbed to create highly convincing imagery to deceive both humans and deep morph detectors.
Tasks Structure Regularization in Multi-Task Learning for Improving Facial Attribute Prediction
Aug 18, 2021
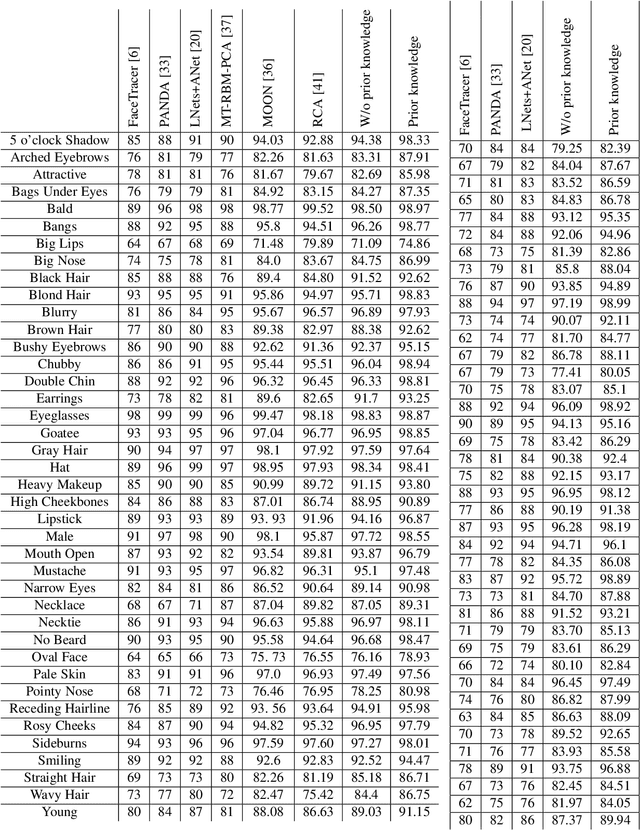
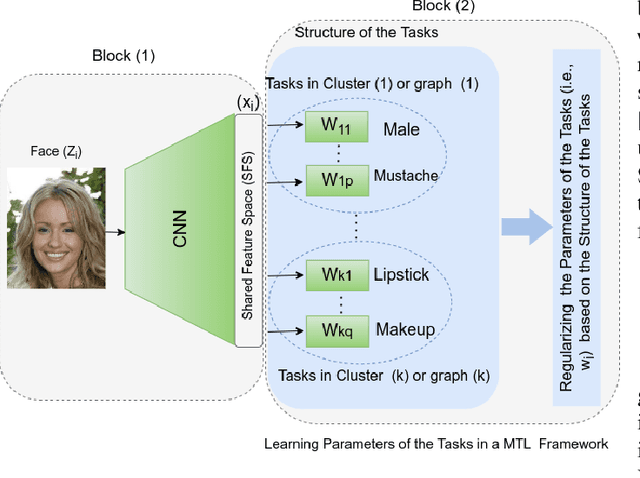
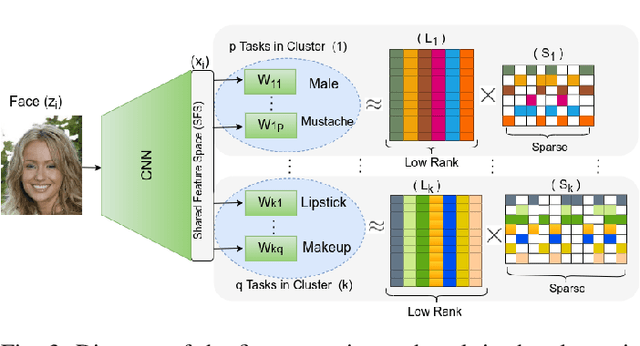
The great success of Convolutional Neural Networks (CNN) for facial attribute prediction relies on a large amount of labeled images. Facial image datasets are usually annotated by some commonly used attributes (e.g., gender), while labels for the other attributes (e.g., big nose) are limited which causes their prediction challenging. To address this problem, we use a new Multi-Task Learning (MTL) paradigm in which a facial attribute predictor uses the knowledge of other related attributes to obtain a better generalization performance. Here, we leverage MLT paradigm in two problem settings. First, it is assumed that the structure of the tasks (e.g., grouping pattern of facial attributes) is known as a prior knowledge, and parameters of the tasks (i.e., predictors) within the same group are represented by a linear combination of a limited number of underlying basis tasks. Here, a sparsity constraint on the coefficients of this linear combination is also considered such that each task is represented in a more structured and simpler manner. Second, it is assumed that the structure of the tasks is unknown, and then structure and parameters of the tasks are learned jointly by using a Laplacian regularization framework. Our MTL methods are compared with competing methods for facial attribute prediction to show its effectiveness.
Attribute Guided Sparse Tensor-Based Model for Person Re-Identification
Jul 29, 2021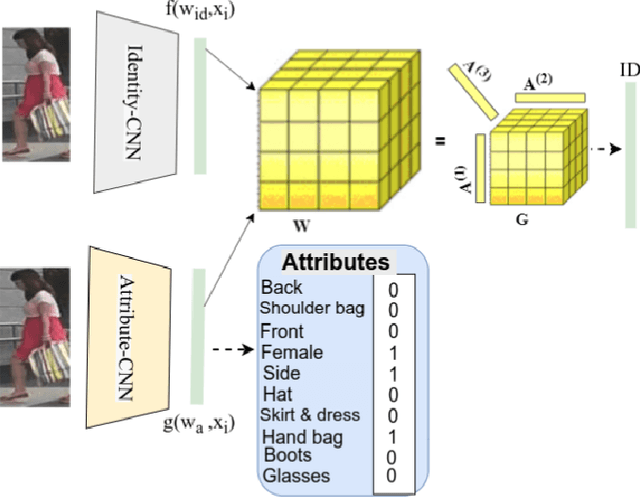

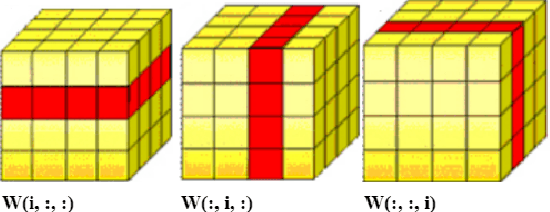

Visual perception of a person is easily influenced by many factors such as camera parameters, pose and viewpoint variations. These variations make person Re-Identification (ReID) a challenging problem. Nevertheless, human attributes usually stand as robust visual properties to such variations. In this paper, we propose a new method to leverage features from human attributes for person ReID. Our model uses a tensor to non-linearly fuse identity and attribute features, and then forces the parameters of the tensor in the loss function to generate discriminative fused features for ReID. Since tensor-based methods usually contain a large number of parameters, training all of these parameters becomes very slow, and the chance of overfitting increases as well. To address this issue, we propose two new techniques based on Structural Sparsity Learning (SSL) and Tensor Decomposition (TD) methods to create an accurate and stable learning problem. We conducted experiments on several standard pedestrian datasets, and experimental results indicate that our tensor-based approach significantly improves person ReID baselines and also outperforms state of the art methods.