 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-Aware Multimodal Biometric Recognition
Paper and Code
Dec 10, 2021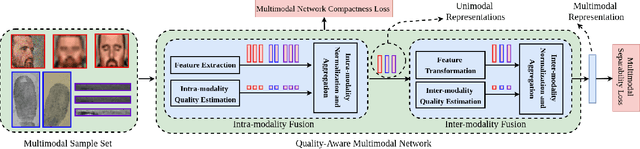
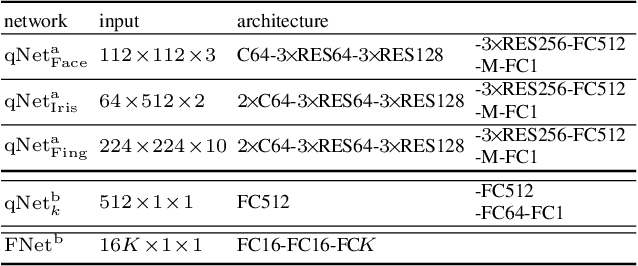
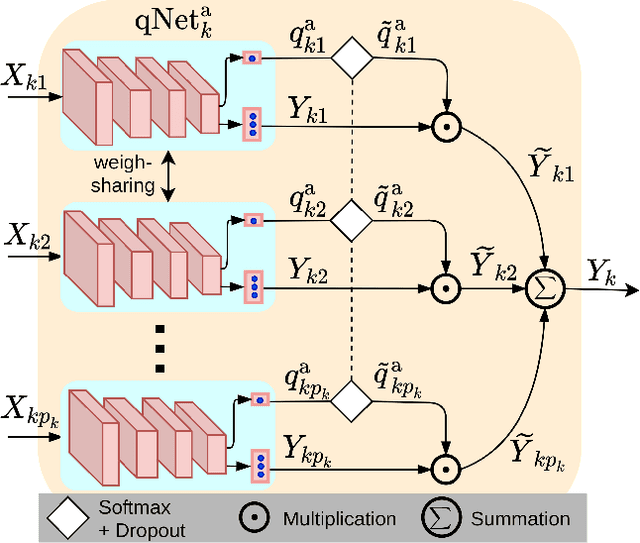
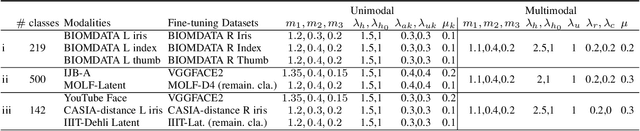
We present a quality-aware multimodal recognition framework that combines representations from multiple biometric traits with varying quality and number of samples to achieve increased recognition accuracy by extracting complimentary identification information based on the quality of the samples. We develop a quality-aware framework for fusing representations of input modalities by weighting their importance using quality scores estimated in a weakly-supervised fashion. This framework utilizes two fusion blocks, each represented by a set of quality-aware and aggregation networks. In addition to architecture modifications, we propose two task-specific loss functions: multimodal separability loss and multimodal compactness loss. The first loss assures that the representations of modalities for a class have comparable magnitudes to provide a better quality estimation, while the multimodal representations of different classes are distributed to achieve maximum discrimination in the embedding space. The second loss, which is considered to regularize the network weights, improves the generalization performance by regularizing the framework. We evaluate the performance by considering three multimodal datasets consisting of face, iris, and fingerprint modalities. The efficacy of the framework is demonstrated through comparison with the state-of-the-art algorithms. In particular, our framework outperforms the rank- and score-level fusion of modalities of BIOMDATA by more than 30% for true acceptance rate at false acceptance rate of $10^{-4}$.