 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHF-Diff: High-Frequency Perceptual Loss and Distribution Matching for One-Step Diffusion-Based Image Super-Resolution
Nov 20, 2024Although recent diffusion-based single-step super-resolution methods achieve better performance as compared to SinSR, they are computationally complex. To improve the performance of SinSR, we investigate preserving the high-frequency detail features during super-resolution (SR) because the downgraded images lack detailed information. For this purpose, we introduce a high-frequency perceptual loss by utilizing an invertible neural network (INN) pretrained on the ImageNet dataset. Different feature maps of pretrained INN produce different high-frequency aspects of an image. During the training phase, we impose to preserve the high-frequency features of super-resolved and ground truth (GT) images that improve the SR image quality during inference. Furthermore, we also utilize the Jenson-Shannon divergence between GT and SR images in the pretrained DINO-v2 embedding space to match their distribution. By introducing the $\textbf{h}igh$- $\textbf{f}requency$ preserving loss and distribution matching constraint in the single-step $\textbf{diff}usion-based$ SR ($\textbf{HF-Diff}$), we achieve a state-of-the-art CLIPIQA score in the benchmark RealSR, RealSet65, DIV2K-Val, and ImageNet datasets. Furthermore, the experimental results in several datasets demonstrate that our high-frequency perceptual loss yields better SR image quality than LPIPS and VGG-based perceptual losses. Our code will be released at https://github.com/shoaib-sami/HF-Diff.
FDWST: Fingerphoto Deblurring using Wavelet Style Transfer
Jul 22, 2024
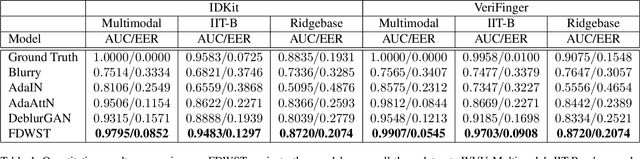
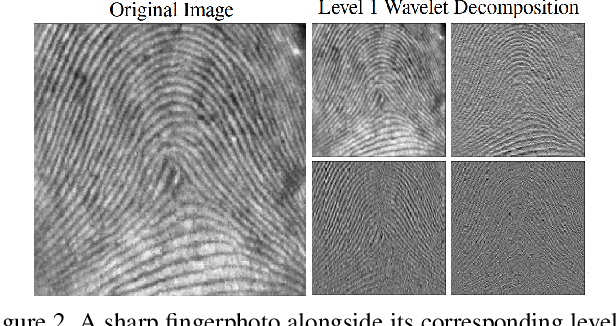
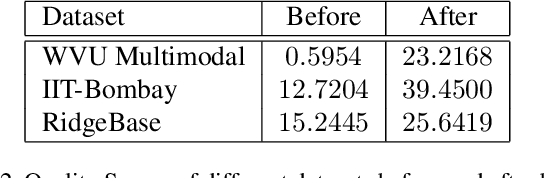
The challenge of deblurring fingerphoto images, or generating a sharp fingerphoto from a given blurry one, is a significant problem in the realm of computer vision. To address this problem, we propose a fingerphoto deblurring architecture referred to as Fingerphoto Deblurring using Wavelet Style Transfer (FDWST), which aims to utilize the information transmission of Style Transfer techniques to deblur fingerphotos. Additionally, we incorporate the Discrete Wavelet Transform (DWT) for its ability to split images into different frequency bands. By combining these two techniques, we can perform Style Transfer over a wide array of wavelet frequency bands, thereby increasing the quality and variety of sharpness information transferred from sharp to blurry images. Using this technique, our model was able to drastically increase the quality of the generated fingerphotos compared to their originals, and achieve a peak matching accuracy of 0.9907 when tasked with matching a deblurred fingerphoto to its sharp counterpart, outperforming multiple other state-of-the-art deblurring and style transfer techniques.
UFQA: Utility guided Fingerphoto Quality Assessment
Jul 15, 2024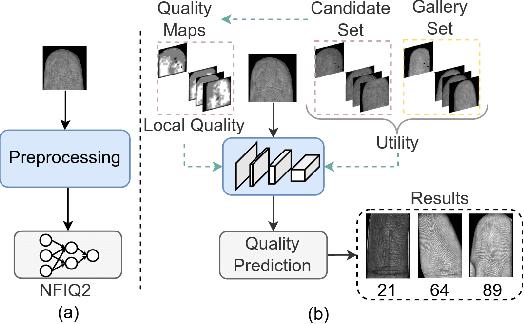
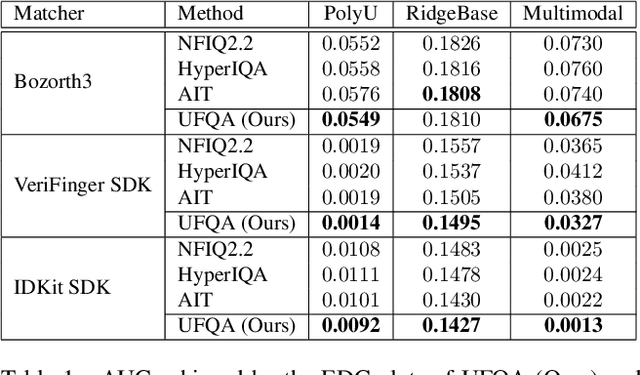
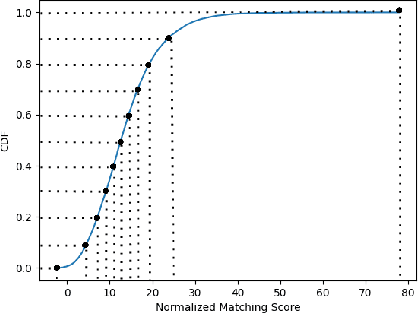
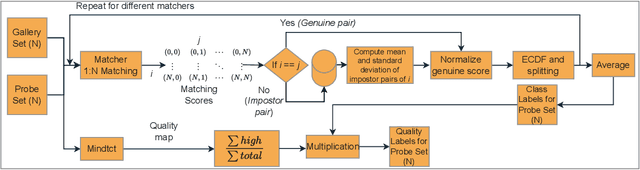
Quality assessment of fingerprints captured using digital cameras and smartphones, also called fingerphotos, is a challenging problem in biometric recognition systems. As contactless biometric modalities are gaining more attention, their reliability should also be improved. Many factors, such as illumination, image contrast, camera angle, etc., in fingerphoto acquisition introduce various types of distortion that may render the samples useless. Current quality estimation methods developed for fingerprints collected using contact-based sensors are inadequate for fingerphotos. We propose Utility guided Fingerphoto Quality Assessment (UFQA), a self-supervised dual encoder framework to learn meaningful feature representations to assess fingerphoto quality. A quality prediction model is trained to assess fingerphoto quality with additional supervision of quality maps. The quality metric is a predictor of the utility of fingerphotos in matching scenarios. Therefore, we use a holistic approach by including fingerphoto utility and local quality when labeling the training data. Experimental results verify that our approach performs better than the widely used fingerprint quality metric NFIQ2.2 and state-of-the-art image quality assessment algorithms on multiple publicly available fingerphoto datasets.
Synthetic Latent Fingerprint Generation Using Style Transfer
Sep 27, 2023
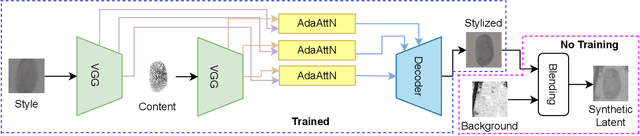
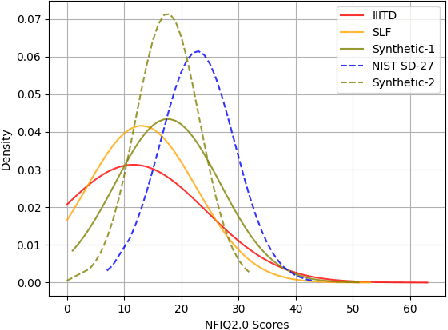
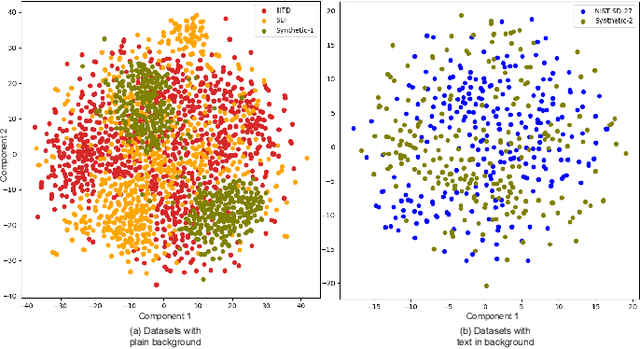
Limited data availability is a challenging problem in the latent fingerprint domain. Synthetically generated fingerprints are vital for training data-hungry neural network-based algorithms. Conventional methods distort clean fingerprints to generate synthetic latent fingerprints. We propose a simple and effective approach using style transfer and image blending to synthesize realistic latent fingerprints. Our evaluation criteria and experiments demonstrate that the generated synthetic latent fingerprints preserve the identity information from the input contact-based fingerprints while possessing similar characteristics as real latent fingerprints. Additionally, we show that the generated fingerprints exhibit several qualities and styles, suggesting that the proposed method can generate multiple samples from a single fingerprint.
Benchmarking Human Face Similarity Using Identical Twins
Aug 25, 2022
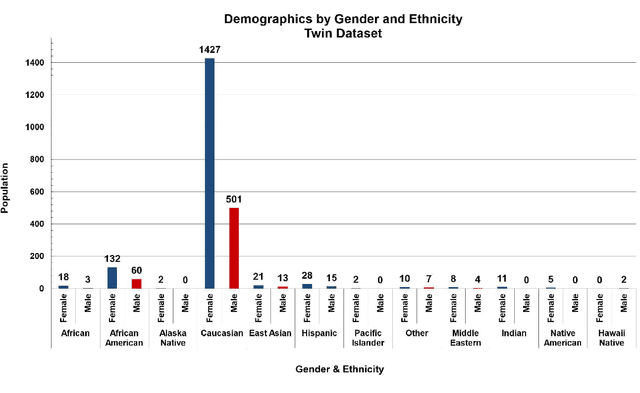
The problem of distinguishing identical twins and non-twin look-alikes in automated facial recognition (FR) applications has become increasingly important with the widespread adoption of facial biometrics. Due to the high facial similarity of both identical twins and look-alikes, these face pairs represent the hardest cases presented to facial recognition tools. This work presents an application of one of the largest twin datasets compiled to date to address two FR challenges: 1) determining a baseline measure of facial similarity between identical twins and 2) applying this similarity measure to determine the impact of doppelgangers, or look-alikes, on FR performance for large face datasets. The facial similarity measure is determined via a deep convolutional neural network. This network is trained on a tailored verification task designed to encourage the network to group together highly similar face pairs in the embedding space and achieves a test AUC of 0.9799. The proposed network provides a quantitative similarity score for any two given faces and has been applied to large-scale face datasets to identify similar face pairs. An additional analysis which correlates the comparison score returned by a facial recognition tool and the similarity score returned by the proposed network has also been performed.
Quality-Aware Multimodal Biometric Recognition
Dec 10, 2021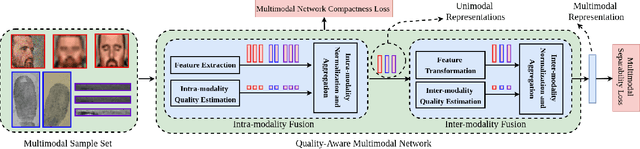
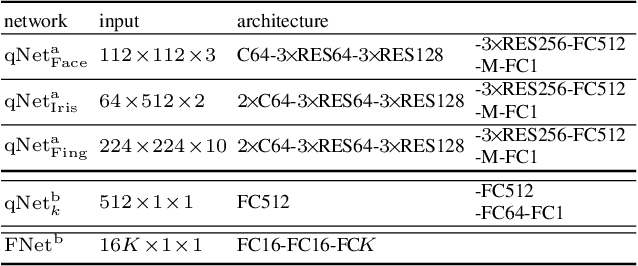
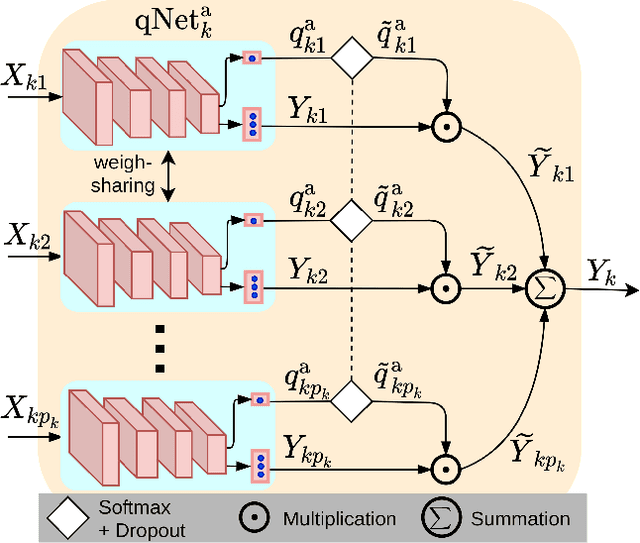
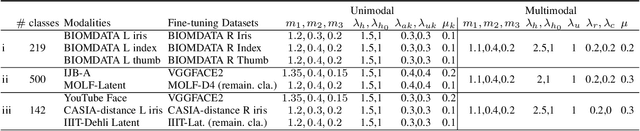
We present a quality-aware multimodal recognition framework that combines representations from multiple biometric traits with varying quality and number of samples to achieve increased recognition accuracy by extracting complimentary identification information based on the quality of the samples. We develop a quality-aware framework for fusing representations of input modalities by weighting their importance using quality scores estimated in a weakly-supervised fashion. This framework utilizes two fusion blocks, each represented by a set of quality-aware and aggregation networks. In addition to architecture modifications, we propose two task-specific loss functions: multimodal separability loss and multimodal compactness loss. The first loss assures that the representations of modalities for a class have comparable magnitudes to provide a better quality estimation, while the multimodal representations of different classes are distributed to achieve maximum discrimination in the embedding space. The second loss, which is considered to regularize the network weights, improves the generalization performance by regularizing the framework. We evaluate the performance by considering three multimodal datasets consisting of face, iris, and fingerprint modalities. The efficacy of the framework is demonstrated through comparison with the state-of-the-art algorithms. In particular, our framework outperforms the rank- and score-level fusion of modalities of BIOMDATA by more than 30% for true acceptance rate at false acceptance rate of $10^{-4}$.
Morph Detection Enhanced by Structured Group Sparsity
Nov 29, 2021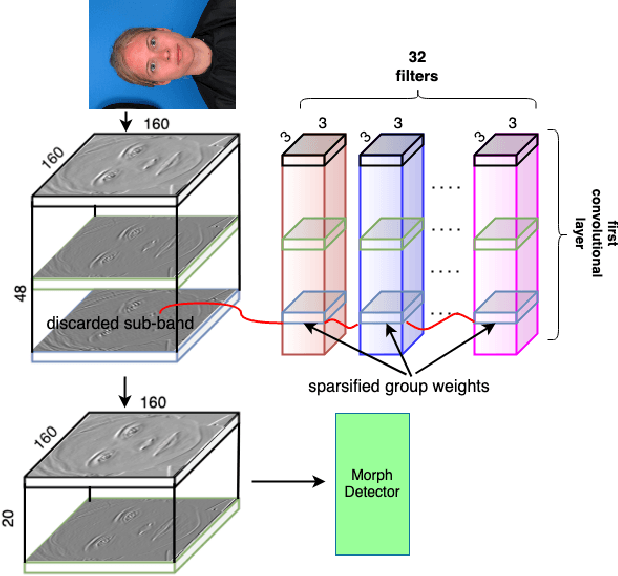
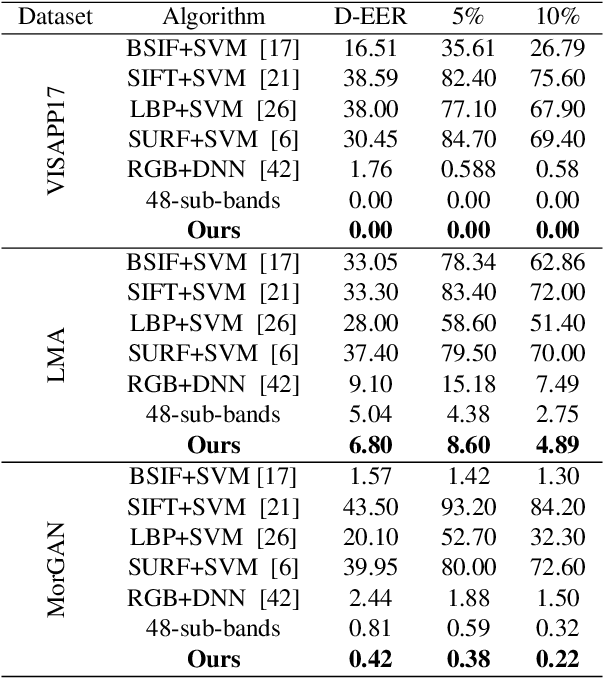
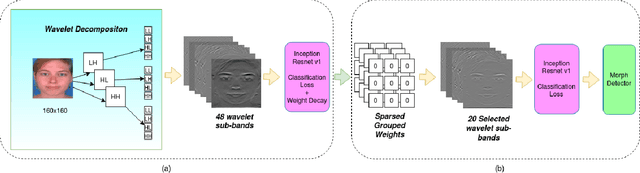
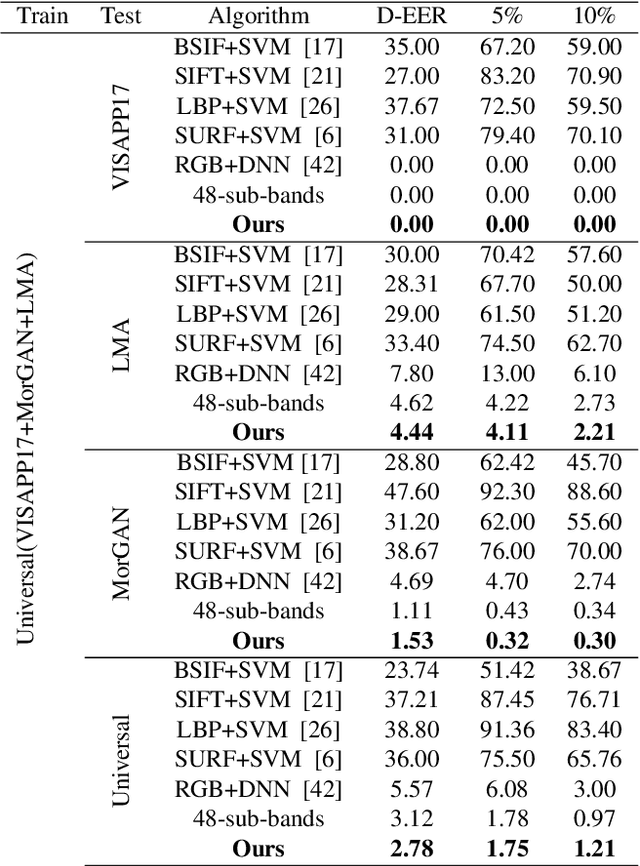
In this paper, we consider the challenge of face morphing attacks, which substantially undermine the integrity of face recognition systems such as those adopted for use in border protection agencies. Morph detection can be formulated as extracting fine-grained representations, where local discriminative features are harnessed for learning a hypothesis. To acquire discriminative features at different granularity as well as a decoupled spectral information, we leverage wavelet domain analysis to gain insight into the spatial-frequency content of a morphed face. As such, instead of using images in the RGB domain, we decompose every image into its wavelet sub-bands using 2D wavelet decomposition and a deep supervised feature selection scheme is employed to find the most discriminative wavelet sub-bands of input images. To this end, we train a Deep Neural Network (DNN) morph detector using the decomposed wavelet sub-bands of the morphed and bona fide images. In the training phase, our structured group sparsity-constrained DNN picks the most discriminative wavelet sub-bands out of all the sub-bands, with which we retrain our DNN, resulting in a precise detection of morphed images when inference is achieved on a probe image. The efficacy of our deep morph detector which is enhanced by structured group lasso is validated through experiments on three facial morph image databases, i.e., VISAPP17, LMA, and MorGAN.
Adversarially Perturbed Wavelet-based Morphed Face Generation
Nov 03, 2021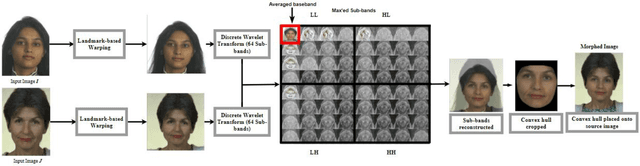
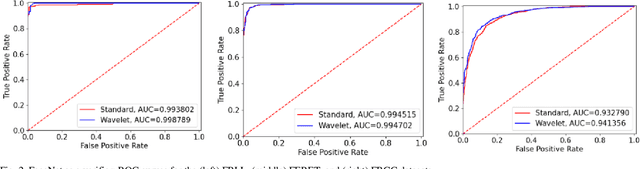
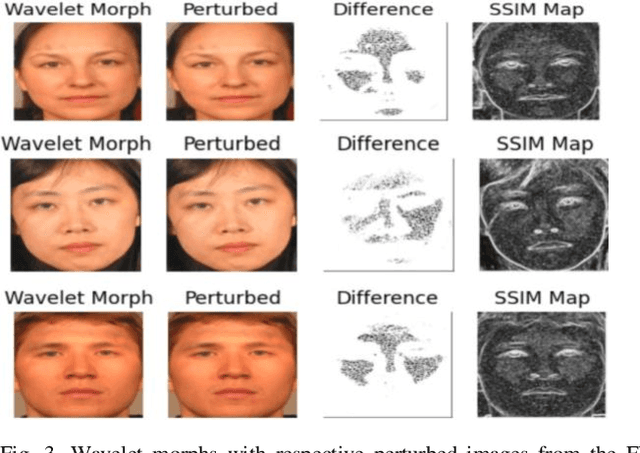
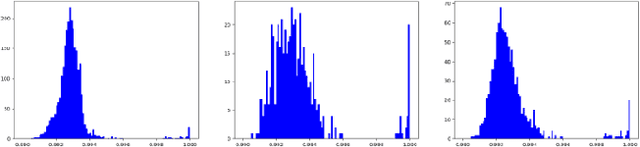
Morphing is the process of combining two or more subjects in an image in order to create a new identity which contains features of both individuals. Morphed images can fool Facial Recognition Systems (FRS) into falsely accepting multiple people, leading to failures in national security. As morphed image synthesis becomes easier, it is vital to expand the research community's available data to help combat this dilemma. In this paper, we explore combination of two methods for morphed image generation, those of geometric transformation (warping and blending to create morphed images) and photometric perturbation. We leverage both methods to generate high-quality adversarially perturbed morphs from the FERET, FRGC, and FRLL datasets. The final images retain high similarity to both input subjects while resulting in minimal artifacts in the visual domain. Images are synthesized by fusing the wavelet sub-bands from the two look-alike subjects, and then adversarially perturbed to create highly convincing imagery to deceive both humans and deep morph detectors.
Tasks Structure Regularization in Multi-Task Learning for Improving Facial Attribute Prediction
Aug 18, 2021
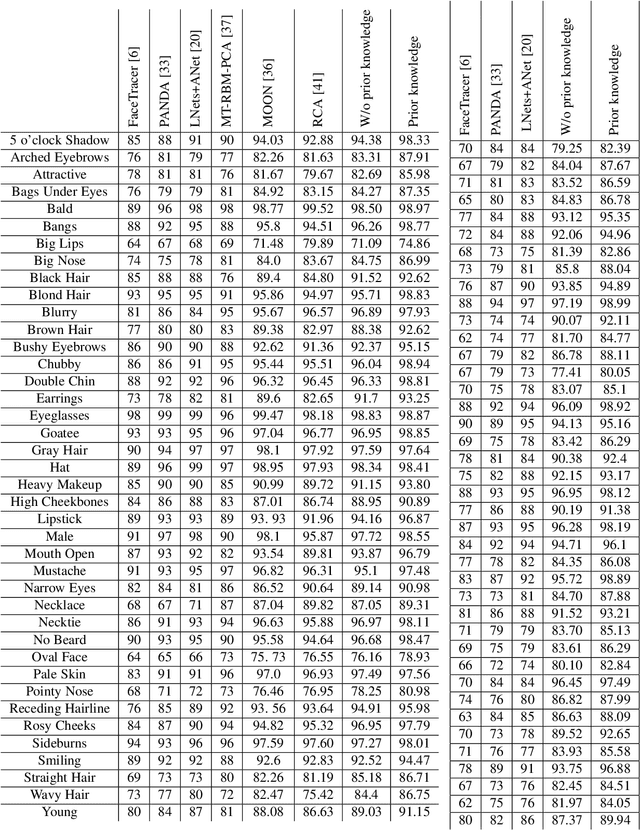
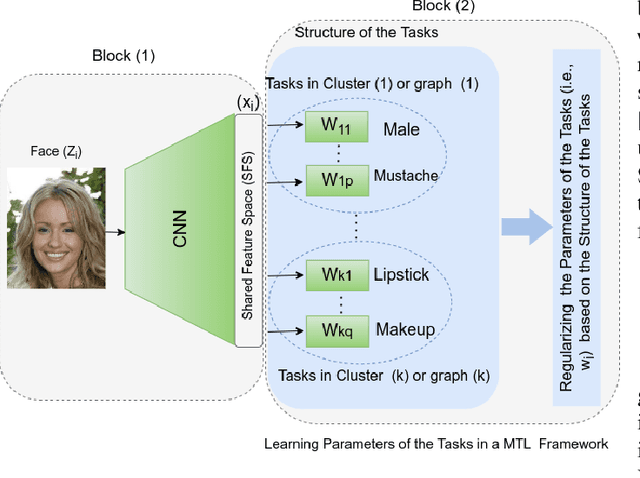
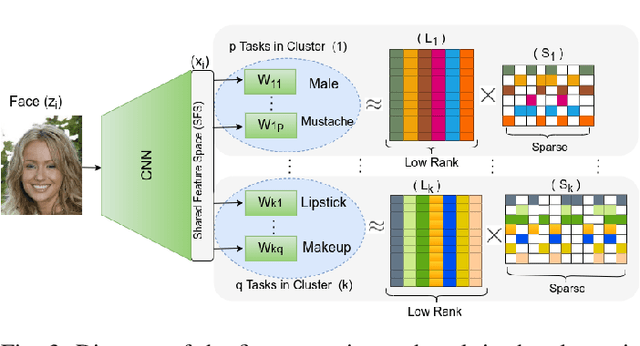
The great success of Convolutional Neural Networks (CNN) for facial attribute prediction relies on a large amount of labeled images. Facial image datasets are usually annotated by some commonly used attributes (e.g., gender), while labels for the other attributes (e.g., big nose) are limited which causes their prediction challenging. To address this problem, we use a new Multi-Task Learning (MTL) paradigm in which a facial attribute predictor uses the knowledge of other related attributes to obtain a better generalization performance. Here, we leverage MLT paradigm in two problem settings. First, it is assumed that the structure of the tasks (e.g., grouping pattern of facial attributes) is known as a prior knowledge, and parameters of the tasks (i.e., predictors) within the same group are represented by a linear combination of a limited number of underlying basis tasks. Here, a sparsity constraint on the coefficients of this linear combination is also considered such that each task is represented in a more structured and simpler manner. Second, it is assumed that the structure of the tasks is unknown, and then structure and parameters of the tasks are learned jointly by using a Laplacian regularization framework. Our MTL methods are compared with competing methods for facial attribute prediction to show its effectiveness.
Deep GAN-Based Cross-Spectral Cross-Resolution Iris Recognition
Aug 03, 2021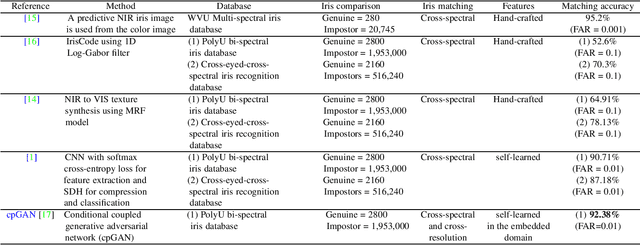
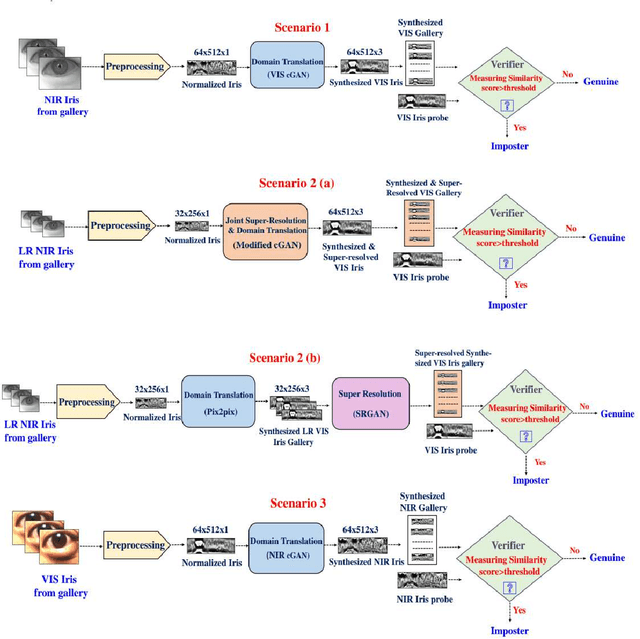
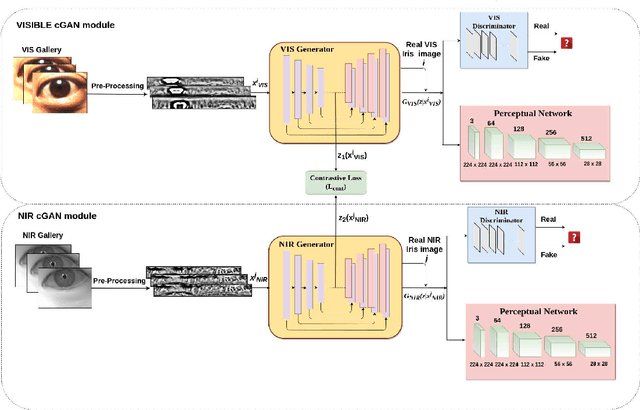
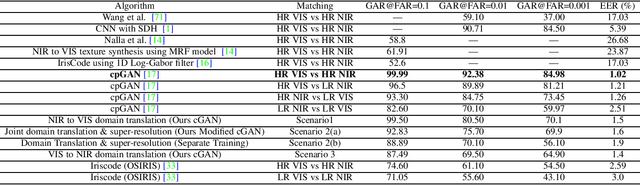
In recent years, cross-spectral iris recognition has emerged as a promising biometric approach to establish the identity of individuals. However, matching iris images acquired at different spectral bands (i.e., matching a visible (VIS) iris probe to a gallery of near-infrared (NIR) iris images or vice versa) shows a significant performance degradation when compared to intraband NIR matching. Hence, in this paper, we have investigated a range of deep convolutional generative adversarial network (DCGAN) architectures to further improve the accuracy of cross-spectral iris recognition methods. Moreover, unlike the existing works in the literature, we introduce a resolution difference into the classical cross-spectral matching problem domain. We have developed two different techniques using the conditional generative adversarial network (cGAN) as a backbone architecture for cross-spectral iris matching. In the first approach, we simultaneously address the cross-resolution and cross-spectral matching problem by training a cGAN that jointly translates cross-resolution as well as cross-spectral tasks to the same resolution and within the same spectrum. In the second approach, we design a coupled generative adversarial network (cpGAN) architecture consisting of a pair of cGAN modules that project the VIS and NIR iris images into a low-dimensional embedding domain to ensure maximum pairwise similarity between the feature vectors from the two iris modalities of the same subject.