 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDCT: Frequency-Aware Decomposition and Cross-Modal Token-Alignment for Multi-Sensor Target Classification
Mar 12, 2025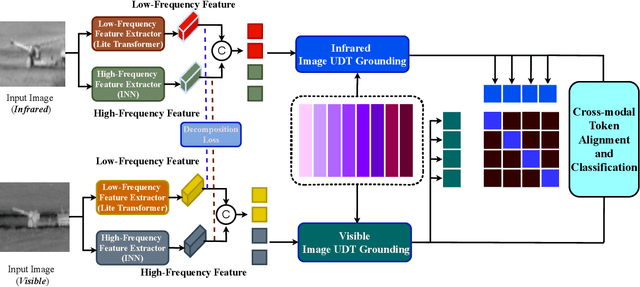
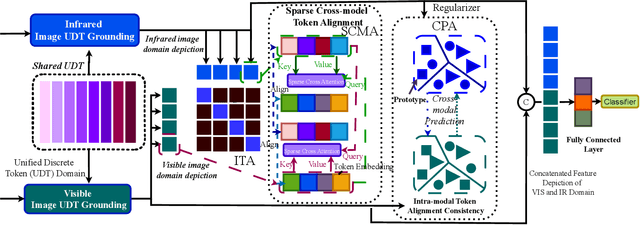
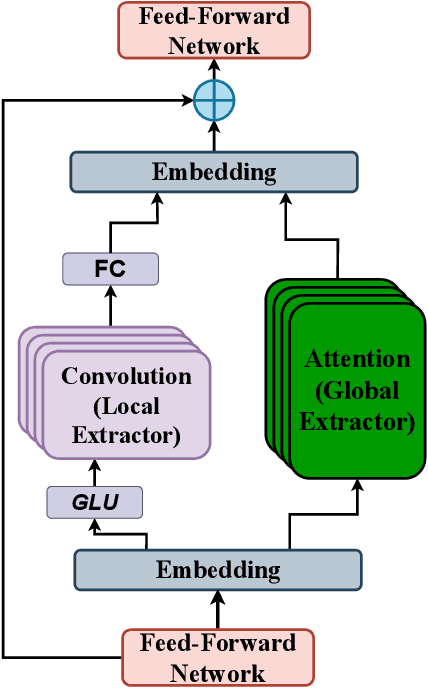
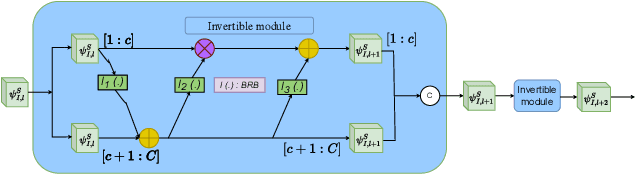
In automatic target recognition (ATR) systems, sensors may fail to capture discriminative, fine-grained detail features due to environmental conditions, noise created by CMOS chips, occlusion, parallaxes, and sensor misalignment. Therefore, multi-sensor image fusion is an effective choice to overcome these constraints. However, multi-modal image sensors are heterogeneous and have domain and granularity gaps. In addition, the multi-sensor images can be misaligned due to intricate background clutters, fluctuating illumination conditions, and uncontrolled sensor settings. In this paper, to overcome these issues, we decompose, align, and fuse multiple image sensor data for target classification. We extract the domain-specific and domain-invariant features from each sensor data. We propose to develop a shared unified discrete token (UDT) space between sensors to reduce the domain and granularity gaps. Additionally, we develop an alignment module to overcome the misalignment between multi-sensors and emphasize the discriminative representation of the UDT space. In the alignment module, we introduce sparsity constraints to provide a better cross-modal representation of the UDT space and robustness against various sensor settings. We achieve superior classification performance compared to single-modality classifiers and several state-of-the-art multi-modal fusion algorithms on four multi-sensor ATR datasets.
CLFace: A Scalable and Resource-Efficient Continual Learning Framework for Lifelong Face Recognition
Nov 21, 2024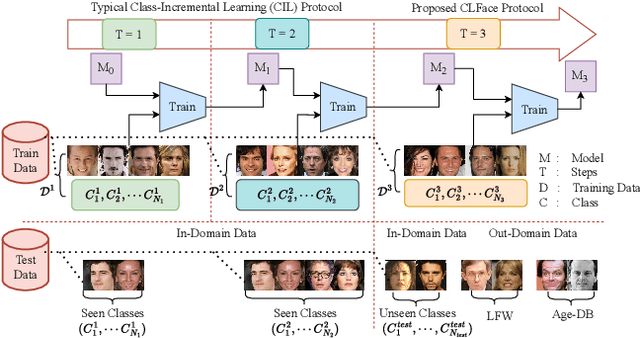

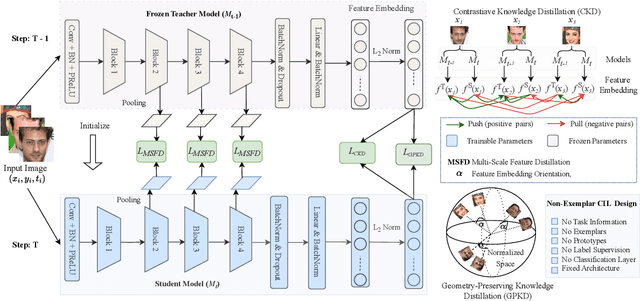
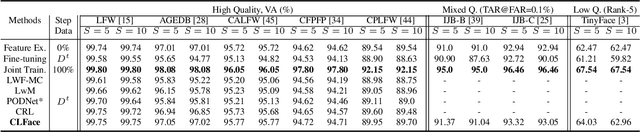
An important aspect of deploying face recognition (FR) algorithms in real-world applications is their ability to learn new face identities from a continuous data stream. However, the online training of existing deep neural network-based FR algorithms, which are pre-trained offline on large-scale stationary datasets, encounter two major challenges: (I) catastrophic forgetting of previously learned identities, and (II) the need to store past data for complete retraining from scratch, leading to significant storage constraints and privacy concerns. In this paper, we introduce CLFace, a continual learning framework designed to preserve and incrementally extend the learned knowledge. CLFace eliminates the classification layer, resulting in a resource-efficient FR model that remains fixed throughout lifelong learning and provides label-free supervision to a student model, making it suitable for open-set face recognition during incremental steps. We introduce an objective function that employs feature-level distillation to reduce drift between feature maps of the student and teacher models across multiple stages. Additionally, it incorporates a geometry-preserving distillation scheme to maintain the orientation of the teacher model's feature embedding. Furthermore, a contrastive knowledge distillation is incorporated to continually enhance the discriminative power of the feature representation by matching similarities between new identities. Experiments on several benchmark FR datasets demonstrate that CLFace outperforms baseline approaches and state-of-the-art methods on unseen identities using both in-domain and out-of-domain datasets.
HF-Diff: High-Frequency Perceptual Loss and Distribution Matching for One-Step Diffusion-Based Image Super-Resolution
Nov 20, 2024Although recent diffusion-based single-step super-resolution methods achieve better performance as compared to SinSR, they are computationally complex. To improve the performance of SinSR, we investigate preserving the high-frequency detail features during super-resolution (SR) because the downgraded images lack detailed information. For this purpose, we introduce a high-frequency perceptual loss by utilizing an invertible neural network (INN) pretrained on the ImageNet dataset. Different feature maps of pretrained INN produce different high-frequency aspects of an image. During the training phase, we impose to preserve the high-frequency features of super-resolved and ground truth (GT) images that improve the SR image quality during inference. Furthermore, we also utilize the Jenson-Shannon divergence between GT and SR images in the pretrained DINO-v2 embedding space to match their distribution. By introducing the $\textbf{h}igh$- $\textbf{f}requency$ preserving loss and distribution matching constraint in the single-step $\textbf{diff}usion-based$ SR ($\textbf{HF-Diff}$), we achieve a state-of-the-art CLIPIQA score in the benchmark RealSR, RealSet65, DIV2K-Val, and ImageNet datasets. Furthermore, the experimental results in several datasets demonstrate that our high-frequency perceptual loss yields better SR image quality than LPIPS and VGG-based perceptual losses. Our code will be released at https://github.com/shoaib-sami/HF-Diff.
Contrastive Learning and Cycle Consistency-based Transductive Transfer Learning for Target Annotation
Jan 22, 2024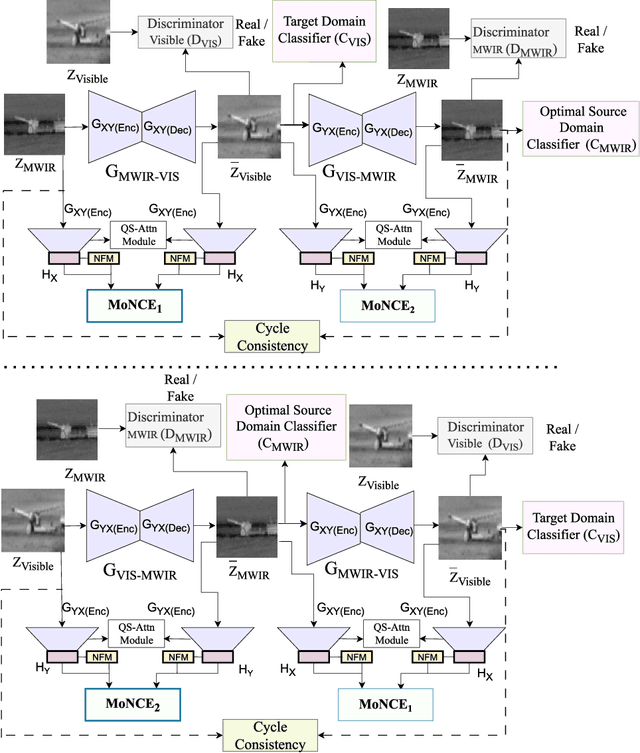
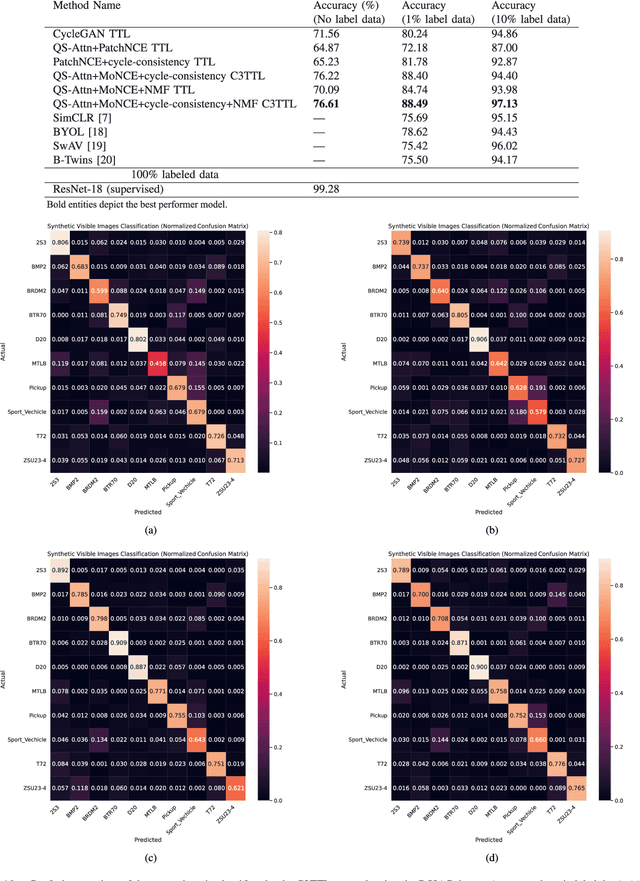
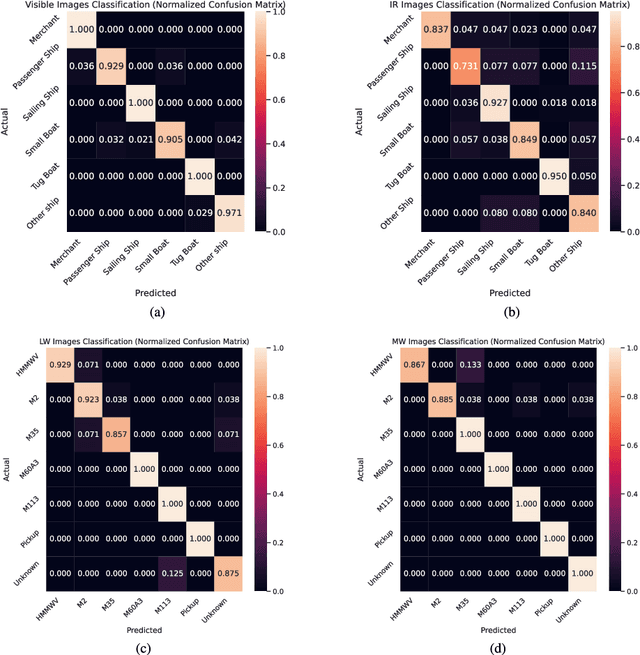
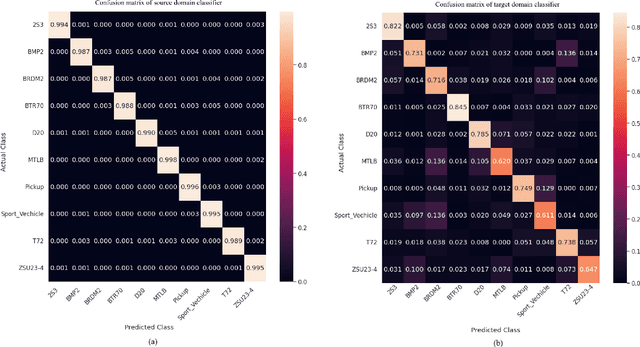
Annotating automatic target recognition (ATR) is a highly challenging task, primarily due to the unavailability of labeled data in the target domain. Hence, it is essential to construct an optimal target domain classifier by utilizing the labeled information of the source domain images. The transductive transfer learning (TTL) method that incorporates a CycleGAN-based unpaired domain translation network has been previously proposed in the literature for effective ATR annotation. Although this method demonstrates great potential for ATR, it severely suffers from lower annotation performance, higher Fr\'echet Inception Distance (FID) score, and the presence of visual artifacts in the synthetic images. To address these issues, we propose a hybrid contrastive learning base unpaired domain translation (H-CUT) network that achieves a significantly lower FID score. It incorporates both attention and entropy to emphasize the domain-specific region, a noisy feature mixup module to generate high variational synthetic negative patches, and a modulated noise contrastive estimation (MoNCE) loss to reweight all negative patches using optimal transport for better performance. Our proposed contrastive learning and cycle-consistency-based TTL (C3TTL) framework consists of two H-CUT networks and two classifiers. It simultaneously optimizes cycle-consistency, MoNCE, and identity losses. In C3TTL, two H-CUT networks have been employed through a bijection mapping to feed the reconstructed source domain images into a pretrained classifier to guide the optimal target domain classifier. Extensive experimental analysis conducted on three ATR datasets demonstrates that the proposed C3TTL method is effective in annotating civilian and military vehicles, as well as ship targets.
Text-Guided Face Recognition using Multi-Granularity Cross-Modal Contrastive Learning
Dec 14, 2023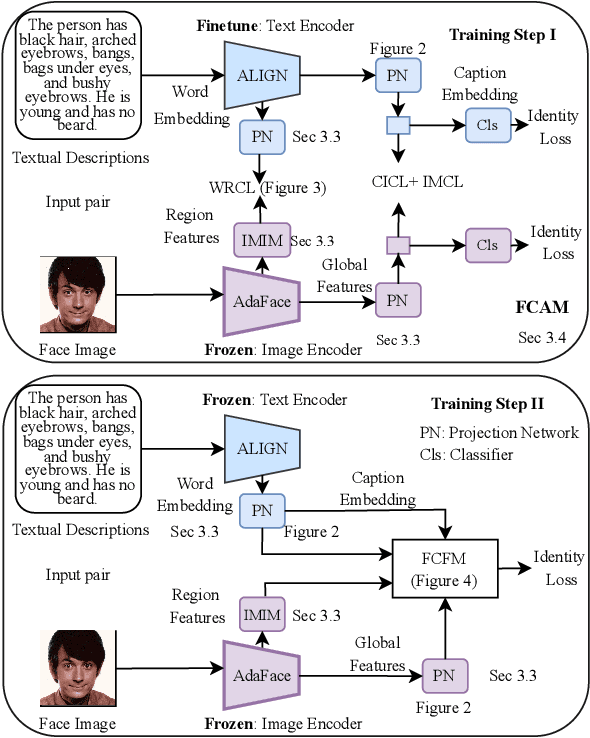
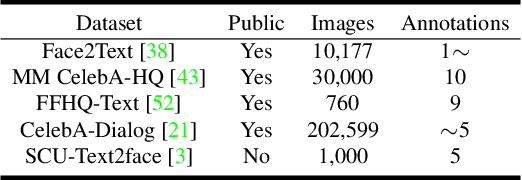
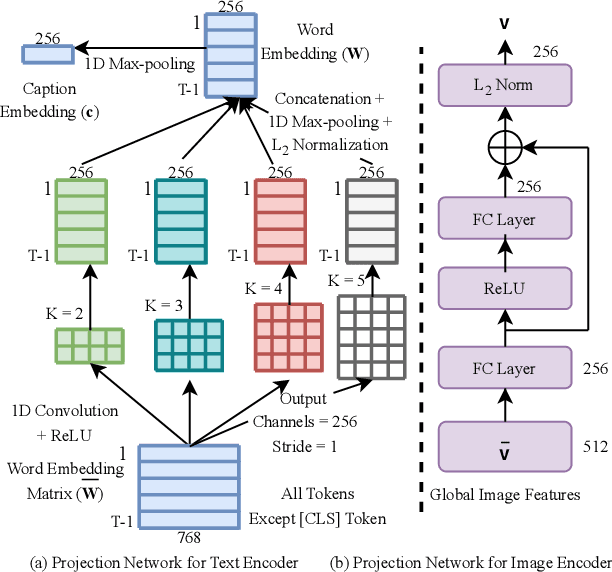
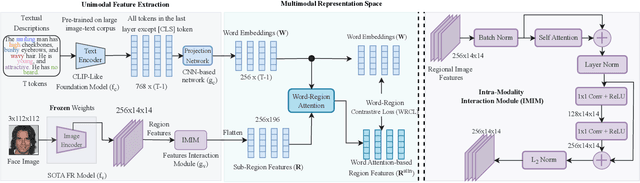
State-of-the-art face recognition (FR) models often experience a significant performance drop when dealing with facial images in surveillance scenarios where images are in low quality and often corrupted with noise. Leveraging facial characteristics, such as freckles, scars, gender, and ethnicity, becomes highly beneficial in improving FR performance in such scenarios. In this paper, we introduce text-guided face recognition (TGFR) to analyze the impact of integrating facial attributes in the form of natural language descriptions. We hypothesize that adding semantic information into the loop can significantly improve the image understanding capability of an FR algorithm compared to other soft biometrics. However, learning a discriminative joint embedding within the multimodal space poses a considerable challenge due to the semantic gap in the unaligned image-text representations, along with the complexities arising from ambiguous and incoherent textual descriptions of the face. To address these challenges, we introduce a face-caption alignment module (FCAM), which incorporates cross-modal contrastive losses across multiple granularities to maximize the mutual information between local and global features of the face-caption pair. Within FCAM, we refine both facial and textual features for learning aligned and discriminative features. We also design a face-caption fusion module (FCFM) that applies fine-grained interactions and coarse-grained associations among cross-modal features. Through extensive experiments conducted on three face-caption datasets, proposed TGFR demonstrates remarkable improvements, particularly on low-quality images, over existing FR models and outperforms other related methods and benchmarks.
Robust Ensemble Morph Detection with Domain Generalization
Sep 16, 2022
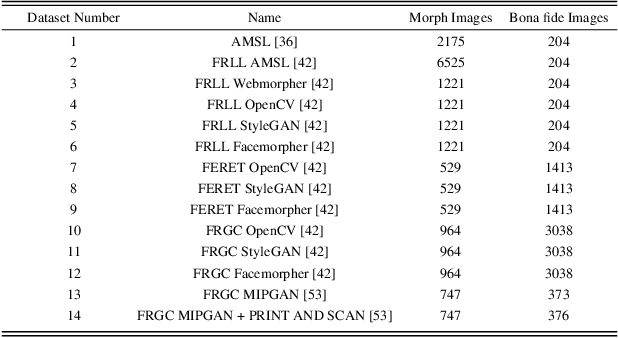
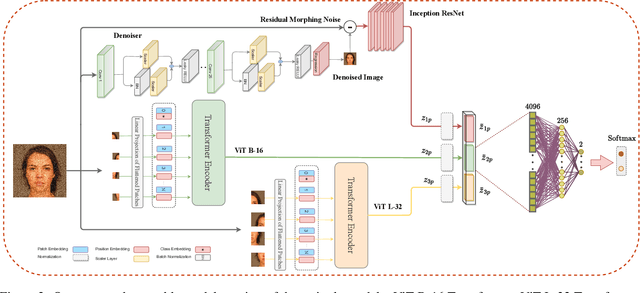
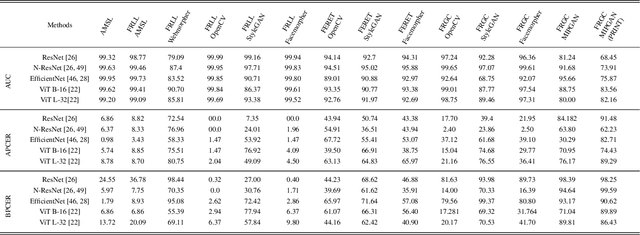
Although a substantial amount of studies is dedicated to morph detection, most of them fail to generalize for morph faces outside of their training paradigm. Moreover, recent morph detection methods are highly vulnerable to adversarial attacks. In this paper, we intend to learn a morph detection model with high generalization to a wide range of morphing attacks and high robustness against different adversarial attacks. To this aim, we develop an ensemble of convolutional neural networks (CNNs) and Transformer models to benefit from their capabilities simultaneously. To improve the robust accuracy of the ensemble model, we employ multi-perturbation adversarial training and generate adversarial examples with high transferability for several single models. Our exhaustive evaluations demonstrate that the proposed robust ensemble model generalizes to several morphing attacks and face datasets. In addition, we validate that our robust ensemble model gain better robustness against several adversarial attacks while outperforming the state-of-the-art studies.
Benchmarking Human Face Similarity Using Identical Twins
Aug 25, 2022
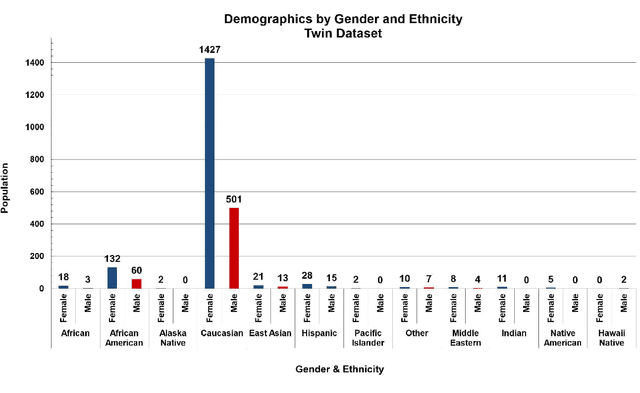
The problem of distinguishing identical twins and non-twin look-alikes in automated facial recognition (FR) applications has become increasingly important with the widespread adoption of facial biometrics. Due to the high facial similarity of both identical twins and look-alikes, these face pairs represent the hardest cases presented to facial recognition tools. This work presents an application of one of the largest twin datasets compiled to date to address two FR challenges: 1) determining a baseline measure of facial similarity between identical twins and 2) applying this similarity measure to determine the impact of doppelgangers, or look-alikes, on FR performance for large face datasets. The facial similarity measure is determined via a deep convolutional neural network. This network is trained on a tailored verification task designed to encourage the network to group together highly similar face pairs in the embedding space and achieves a test AUC of 0.9799. The proposed network provides a quantitative similarity score for any two given faces and has been applied to large-scale face datasets to identify similar face pairs. An additional analysis which correlates the comparison score returned by a facial recognition tool and the similarity score returned by the proposed network has also been performed.
Power Transformer Fault Diagnosis with Intrinsic Time-scale Decomposition and XGBoost Classifier
Oct 21, 2021
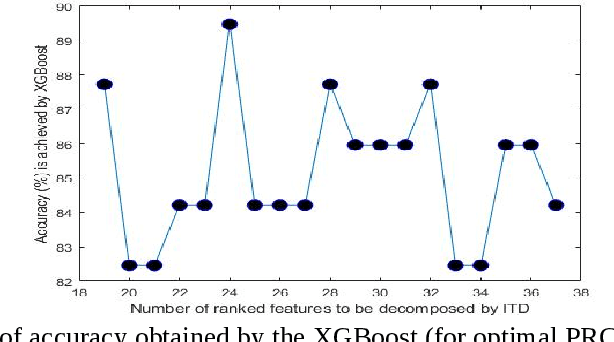

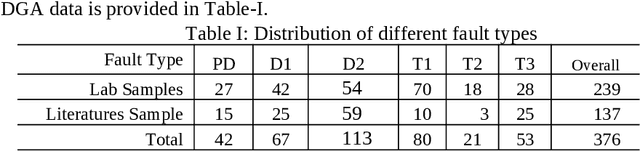
An intrinsic time-scale decomposition (ITD) based method for power transformer fault diagnosis is proposed. Dissolved gas analysis (DGA) parameters are ranked according to their skewness, and then ITD based features extraction is performed. An optimal set of PRC features are determined by an XGBoost classifier. For classification purpose, an XGBoost classifier is used to the optimal PRC features set. The proposed method's performance in classification is studied using publicly available DGA data of 376 power transformers and employing an XGBoost classifier. The Proposed method achieves more than 95% accuracy and high sensitivity and F1-score, better than conventional methods and some recent machine learning-based fault diagnosis approaches. Moreover, it gives better Cohen Kappa and F1-score as compared to the recently introduced EMD-based hierarchical technique for fault diagnosis in power transformers.
An EMD-based Method for the Detection of Power Transformer Faults with a Hierarchical Ensemble Classifier
Oct 21, 2021
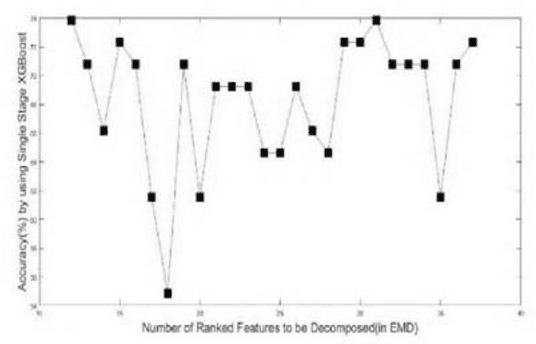


In this paper, an Empirical Mode Decomposition-based method is proposed for the detection of transformer faults from Dissolve gas analysis (DGA) data. Ratio-based DGA parameters are ranked using their skewness. Optimal sets of intrinsic mode function coefficients are obtained from the ranked DGA parameters. A Hierarchical classification scheme employing XGBoost is presented for classifying the features to identify six different categories of transformer faults. Performance of the Proposed Method is studied for publicly available DGA data of 377 transformers. It is shown that the proposed method can yield more than 90% sensitivity and accuracy in the detection of transformer faults, a superior performance as compared to conventional methods as well as several existing machine learning-based techniques.