 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptMAD: Cross-Modal Prompting for Multi-Class Visual Anomaly Localization
Jan 30, 2026Visual anomaly detection in multi-class settings poses significant challenges due to the diversity of object categories, the scarcity of anomalous examples, and the presence of camouflaged defects. In this paper, we propose PromptMAD, a cross-modal prompting framework for unsupervised visual anomaly detection and localization that integrates semantic guidance through vision-language alignment. By leveraging CLIP-encoded text prompts describing both normal and anomalous class-specific characteristics, our method enriches visual reconstruction with semantic context, improving the detection of subtle and textural anomalies. To further address the challenge of class imbalance at the pixel level, we incorporate Focal loss function, which emphasizes hard-to-detect anomalous regions during training. Our architecture also includes a supervised segmentor that fuses multi-scale convolutional features with Transformer-based spatial attention and diffusion iterative refinement, yielding precise and high-resolution anomaly maps. Extensive experiments on the MVTec-AD dataset demonstrate that our method achieves state-of-the-art pixel-level performance, improving mean AUC to 98.35% and AP to 66.54%, while maintaining efficiency across diverse categories.
FreqDebias: Towards Generalizable Deepfake Detection via Consistency-Driven Frequency Debiasing
Sep 26, 2025Deepfake detectors often struggle to generalize to novel forgery types due to biases learned from limited training data. In this paper, we identify a new type of model bias in the frequency domain, termed spectral bias, where detectors overly rely on specific frequency bands, restricting their ability to generalize across unseen forgeries. To address this, we propose FreqDebias, a frequency debiasing framework that mitigates spectral bias through two complementary strategies. First, we introduce a novel Forgery Mixup (Fo-Mixup) augmentation, which dynamically diversifies frequency characteristics of training samples. Second, we incorporate a dual consistency regularization (CR), which enforces both local consistency using class activation maps (CAMs) and global consistency through a von Mises-Fisher (vMF) distribution on a hyperspherical embedding space. This dual CR mitigates over-reliance on certain frequency components by promoting consistent representation learning under both local and global supervision. Extensive experiments show that FreqDebias significantly enhances cross-domain generalization and outperforms state-of-the-art methods in both cross-domain and in-domain settings.
DiSa: Directional Saliency-Aware Prompt Learning for Generalizable Vision-Language Models
May 26, 2025Prompt learning has emerged as a powerful paradigm for adapting vision-language models such as CLIP to downstream tasks. However, existing methods often overfit to seen data, leading to significant performance degradation when generalizing to novel classes or unseen domains. To address this limitation, we propose DiSa, a Directional Saliency-Aware Prompt Learning framework that integrates two complementary regularization strategies to enhance generalization. First, our Cross-Interactive Regularization (CIR) fosters cross-modal alignment by enabling cooperative learning between prompted and frozen encoders. Within CIR, a saliency-aware masking strategy guides the image encoder to prioritize semantically critical image regions, reducing reliance on less informative patches. Second, we introduce a directional regularization strategy that aligns visual embeddings with class-wise prototype features in a directional manner to prioritize consistency in feature orientation over strict proximity. This approach ensures robust generalization by leveraging stable prototype directions derived from class-mean statistics. Extensive evaluations on 11 diverse image classification benchmarks demonstrate that DiSa consistently outperforms state-of-the-art prompt learning methods across various settings, including base-to-novel generalization, cross-dataset transfer, domain generalization, and few-shot learning.
Style-Pro: Style-Guided Prompt Learning for Generalizable Vision-Language Models
Nov 25, 2024Pre-trained Vision-language (VL) models, such as CLIP, have shown significant generalization ability to downstream tasks, even with minimal fine-tuning. While prompt learning has emerged as an effective strategy to adapt pre-trained VL models for downstream tasks, current approaches frequently encounter severe overfitting to specific downstream data distributions. This overfitting constrains the original behavior of the VL models to generalize to new domains or unseen classes, posing a critical challenge in enhancing the adaptability and generalization of VL models. To address this limitation, we propose Style-Pro, a novel style-guided prompt learning framework that mitigates overfitting and preserves the zero-shot generalization capabilities of CLIP. Style-Pro employs learnable style bases to synthesize diverse distribution shifts, guided by two specialized loss functions that ensure style diversity and content integrity. Then, to minimize discrepancies between unseen domains and the source domain, Style-Pro maps the unseen styles into the known style representation space as a weighted combination of style bases. Moreover, to maintain consistency between the style-shifted prompted model and the original frozen CLIP, Style-Pro introduces consistency constraints to preserve alignment in the learned embeddings, minimizing deviation during adaptation to downstream tasks. Extensive experiments across 11 benchmark datasets demonstrate the effectiveness of Style-Pro, consistently surpassing state-of-the-art methods in various settings, including base-to-new generalization, cross-dataset transfer, and domain generalization.
ROADS: Robust Prompt-driven Multi-Class Anomaly Detection under Domain Shift
Nov 25, 2024Recent advancements in anomaly detection have shifted focus towards Multi-class Unified Anomaly Detection (MUAD), offering more scalable and practical alternatives compared to traditional one-class-one-model approaches. However, existing MUAD methods often suffer from inter-class interference and are highly susceptible to domain shifts, leading to substantial performance degradation in real-world applications. In this paper, we propose a novel robust prompt-driven MUAD framework, called ROADS, to address these challenges. ROADS employs a hierarchical class-aware prompt integration mechanism that dynamically encodes class-specific information into our anomaly detector to mitigate interference among anomaly classes. Additionally, ROADS incorporates a domain adapter to enhance robustness against domain shifts by learning domain-invariant representations. Extensive experiments on MVTec-AD and VISA datasets demonstrate that ROADS surpasses state-of-the-art methods in both anomaly detection and localization, with notable improvements in out-of-distribution settings.
CATFace: Cross-Attribute-Guided Transformer with Self-Attention Distillation for Low-Quality Face Recognition
Jan 05, 2024Although face recognition (FR) has achieved great success in recent years, it is still challenging to accurately recognize faces in low-quality images due to the obscured facial details. Nevertheless, it is often feasible to make predictions about specific soft biometric (SB) attributes, such as gender, and baldness even in dealing with low-quality images. In this paper, we propose a novel multi-branch neural network that leverages SB attribute information to boost the performance of FR. To this end, we propose a cross-attribute-guided transformer fusion (CATF) module that effectively captures the long-range dependencies and relationships between FR and SB feature representations. The synergy created by the reciprocal flow of information in the dual cross-attention operations of the proposed CATF module enhances the performance of FR. Furthermore, we introduce a novel self-attention distillation framework that effectively highlights crucial facial regions, such as landmarks by aligning low-quality images with those of their high-quality counterparts in the feature space. The proposed self-attention distillation regularizes our network to learn a unified quality-invariant feature representation in unconstrained environments. We conduct extensive experiments on various FR benchmarks varying in quality. Experimental results demonstrate the superiority of our FR method compared to state-of-the-art FR studies.
Multi-Context Dual Hyper-Prior Neural Image Compression
Sep 19, 2023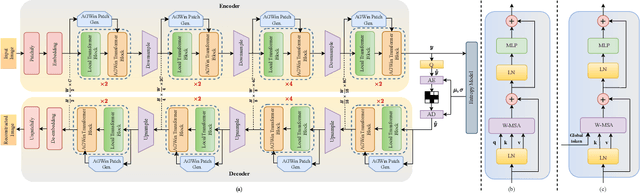
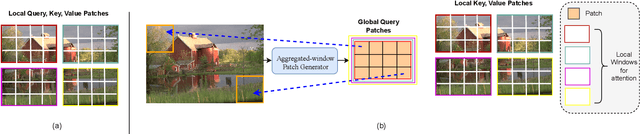
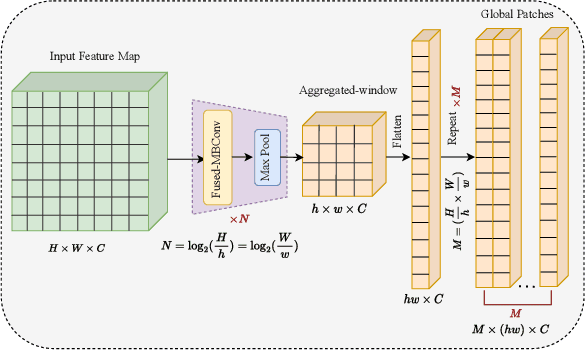
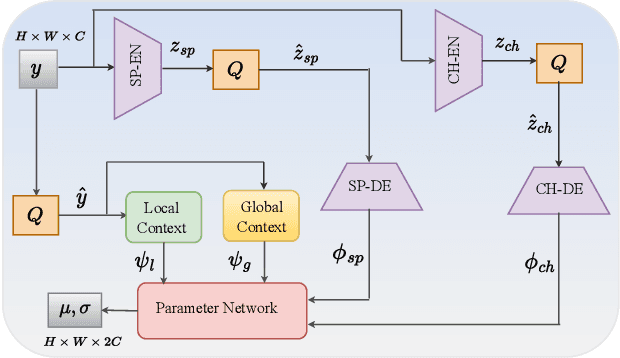
Transform and entropy models are the two core components in deep image compression neural networks. Most existing learning-based image compression methods utilize convolutional-based transform, which lacks the ability to model long-range dependencies, primarily due to the limited receptive field of the convolution operation. To address this limitation, we propose a Transformer-based nonlinear transform. This transform has the remarkable ability to efficiently capture both local and global information from the input image, leading to a more decorrelated latent representation. In addition, we introduce a novel entropy model that incorporates two different hyperpriors to model cross-channel and spatial dependencies of the latent representation. To further improve the entropy model, we add a global context that leverages distant relationships to predict the current latent more accurately. This global context employs a causal attention mechanism to extract long-range information in a content-dependent manner. Our experiments show that our proposed framework performs better than the state-of-the-art methods in terms of rate-distortion performance.
Towards Generalizable Morph Attack Detection with Consistency Regularization
Aug 20, 2023



Though recent studies have made significant progress in morph attack detection by virtue of deep neural networks, they often fail to generalize well to unseen morph attacks. With numerous morph attacks emerging frequently, generalizable morph attack detection has gained significant attention. This paper focuses on enhancing the generalization capability of morph attack detection from the perspective of consistency regularization. Consistency regularization operates under the premise that generalizable morph attack detection should output consistent predictions irrespective of the possible variations that may occur in the input space. In this work, to reach this objective, two simple yet effective morph-wise augmentations are proposed to explore a wide space of realistic morph transformations in our consistency regularization. Then, the model is regularized to learn consistently at the logit as well as embedding levels across a wide range of morph-wise augmented images. The proposed consistency regularization aligns the abstraction in the hidden layers of our model across the morph attack images which are generated from diverse domains in the wild. Experimental results demonstrate the superior generalization and robustness performance of our proposed method compared to the state-of-the-art studies.
CCFace: Classification Consistency for Low-Resolution Face Recognition
Aug 18, 2023In recent years, deep face recognition methods have demonstrated impressive results on in-the-wild datasets. However, these methods have shown a significant decline in performance when applied to real-world low-resolution benchmarks like TinyFace or SCFace. To address this challenge, we propose a novel classification consistency knowledge distillation approach that transfers the learned classifier from a high-resolution model to a low-resolution network. This approach helps in finding discriminative representations for low-resolution instances. To further improve the performance, we designed a knowledge distillation loss using the adaptive angular penalty inspired by the success of the popular angular margin loss function. The adaptive penalty reduces overfitting on low-resolution samples and alleviates the convergence issue of the model integrated with data augmentation. Additionally, we utilize an asymmetric cross-resolution learning approach based on the state-of-the-art semi-supervised representation learning paradigm to improve discriminability on low-resolution instances and prevent them from forming a cluster. Our proposed method outperforms state-of-the-art approaches on low-resolution benchmarks, with a three percent improvement on TinyFace while maintaining performance on high-resolution benchmarks.
AAFACE: Attribute-aware Attentional Network for Face Recognition
Aug 14, 2023



In this paper, we present a new multi-branch neural network that simultaneously performs soft biometric (SB) prediction as an auxiliary modality and face recognition (FR) as the main task. Our proposed network named AAFace utilizes SB attributes to enhance the discriminative ability of FR representation. To achieve this goal, we propose an attribute-aware attentional integration (AAI) module to perform weighted integration of FR with SB feature maps. Our proposed AAI module is not only fully context-aware but also capable of learning complex relationships between input features by means of the sequential multi-scale channel and spatial sub-modules. Experimental results verify the superiority of our proposed network compared with the state-of-the-art (SoTA) SB prediction and FR methods.