 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Spectral LoRA: Routed Experts for Medical VLMs
Apr 01, 2026Large vision-language models (VLMs) excel on general benchmarks but often lack robustness in medical imaging, where heterogeneous supervision induces cross-dataset interference and sensitivity to data regime (i.e., how the supervisory signals are mixed). In realistic clinical workflows, data and tasks arrive sequentially, so naive continual training further leads to catastrophic forgetting. To address these challenges, we propose MedQwen, a parameter-efficient medical VLM that couples a spectrally routed Mixture-of-Experts (MoE) with a theoretically grounded scaling rule that aligns low-rank updates with a full-rank, fully fine-tuned MoE, without changing the base architecture. Concretely, we initialize each expert from non-overlapping singular value decomposition (SVD) segments of the pretrained weight and introduce a residual compensation and scaling scheme to enable stable expert specialization and consistent routing under distribution shift. Across 23 medical datasets covering visual question answering, report generation, radiology classification, and hallucination mitigation, MedQwen achieves strong, reliable performance: it approaches full fine-tuning on zero-shot classification with 339$\times$ fewer trainable parameters, and reduces sequential forgetting to $\sim$5\% where strong baselines degrade by $>$20-50\%.
MedCLIPSeg: Probabilistic Vision-Language Adaptation for Data-Efficient and Generalizable Medical Image Segmentation
Feb 23, 2026Medical image segmentation remains challenging due to limited annotations for training, ambiguous anatomical features, and domain shifts. While vision-language models such as CLIP offer strong cross-modal representations, their potential for dense, text-guided medical image segmentation remains underexplored. We present MedCLIPSeg, a novel framework that adapts CLIP for robust, data-efficient, and uncertainty-aware medical image segmentation. Our approach leverages patch-level CLIP embeddings through probabilistic cross-modal attention, enabling bidirectional interaction between image and text tokens and explicit modeling of predictive uncertainty. Together with a soft patch-level contrastive loss that encourages more nuanced semantic learning across diverse textual prompts, MedCLIPSeg effectively improves data efficiency and domain generalizability. Extensive experiments across 16 datasets spanning five imaging modalities and six organs demonstrate that MedCLIPSeg outperforms prior methods in accuracy, efficiency, and robustness, while providing interpretable uncertainty maps that highlight local reliability of segmentation results. This work demonstrates the potential of probabilistic vision-language modeling for text-driven medical image segmentation.
Enhancing Vehicle Make and Model Recognition with 3D Attention Modules
Feb 21, 2025Vehicle make and model recognition (VMMR) is a crucial component of the Intelligent Transport System, garnering significant attention in recent years. VMMR has been widely utilized for detecting suspicious vehicles, monitoring urban traffic, and autonomous driving systems. The complexity of VMMR arises from the subtle visual distinctions among vehicle models and the wide variety of classes produced by manufacturers. Convolutional Neural Networks (CNNs), a prominent type of deep learning model, have been extensively employed in various computer vision tasks, including VMMR, yielding remarkable results. As VMMR is a fine-grained classification problem, it primarily faces inter-class similarity and intra-class variation challenges. In this study, we implement an attention module to address these challenges and enhance the model's focus on critical areas containing distinguishing features. This module, which does not increase the parameters of the original model, generates three-dimensional (3-D) attention weights to refine the feature map. Our proposed model integrates the attention module into two different locations within the middle section of a convolutional model, where the feature maps from these sections offer sufficient information about the input frames without being overly detailed or overly coarse. The performance of our proposed model, along with state-of-the-art (SOTA) convolutional and transformer-based models, was evaluated using the Stanford Cars dataset. Our proposed model achieved the highest accuracy, 90.69\%, among the compared models.
Medical Image Classification with KAN-Integrated Transformers and Dilated Neighborhood Attention
Feb 19, 2025Convolutional networks, transformers, hybrid models, and Mamba-based architectures have demonstrated strong performance across various medical image classification tasks. However, these methods were primarily designed to classify clean images using labeled data. In contrast, real-world clinical data often involve image corruptions that are unique to multi-center studies and stem from variations in imaging equipment across manufacturers. In this paper, we introduce the Medical Vision Transformer (MedViTV2), a novel architecture incorporating Kolmogorov-Arnold Network (KAN) layers into the transformer architecture for the first time, aiming for generalized medical image classification. We have developed an efficient KAN block to reduce computational load while enhancing the accuracy of the original MedViT. Additionally, to counteract the fragility of our MedViT when scaled up, we propose an enhanced Dilated Neighborhood Attention (DiNA), an adaptation of the efficient fused dot-product attention kernel capable of capturing global context and expanding receptive fields to scale the model effectively and addressing feature collapse issues. Moreover, a hierarchical hybrid strategy is introduced to stack our Local Feature Perception and Global Feature Perception blocks in an efficient manner, which balances local and global feature perceptions to boost performance. Extensive experiments on 17 medical image classification datasets and 12 corrupted medical image datasets demonstrate that MedViTV2 achieved state-of-the-art results in 27 out of 29 experiments with reduced computational complexity. MedViTV2 is 44\% more computationally efficient than the previous version and significantly enhances accuracy, achieving improvements of 4.6\% on MedMNIST, 5.8\% on NonMNIST, and 13.4\% on the MedMNIST-C benchmark.
BEFUnet: A Hybrid CNN-Transformer Architecture for Precise Medical Image Segmentation
Feb 13, 2024The accurate segmentation of medical images is critical for various healthcare applications. Convolutional neural networks (CNNs), especially Fully Convolutional Networks (FCNs) like U-Net, have shown remarkable success in medical image segmentation tasks. However, they have limitations in capturing global context and long-range relations, especially for objects with significant variations in shape, scale, and texture. While transformers have achieved state-of-the-art results in natural language processing and image recognition, they face challenges in medical image segmentation due to image locality and translational invariance issues. To address these challenges, this paper proposes an innovative U-shaped network called BEFUnet, which enhances the fusion of body and edge information for precise medical image segmentation. The BEFUnet comprises three main modules, including a novel Local Cross-Attention Feature (LCAF) fusion module, a novel Double-Level Fusion (DLF) module, and dual-branch encoder. The dual-branch encoder consists of an edge encoder and a body encoder. The edge encoder employs PDC blocks for effective edge information extraction, while the body encoder uses the Swin Transformer to capture semantic information with global attention. The LCAF module efficiently fuses edge and body features by selectively performing local cross-attention on features that are spatially close between the two modalities. This local approach significantly reduces computational complexity compared to global cross-attention while ensuring accurate feature matching. BEFUnet demonstrates superior performance over existing methods across various evaluation metrics on medical image segmentation datasets.
Traffic Sign Recognition Using Local Vision Transformer
Nov 11, 2023Recognition of traffic signs is a crucial aspect of self-driving cars and driver assistance systems, and machine vision tasks such as traffic sign recognition have gained significant attention. CNNs have been frequently used in machine vision, but introducing vision transformers has provided an alternative approach to global feature learning. This paper proposes a new novel model that blends the advantages of both convolutional and transformer-based networks for traffic sign recognition. The proposed model includes convolutional blocks for capturing local correlations and transformer-based blocks for learning global dependencies. Additionally, a locality module is incorporated to enhance local perception. The performance of the suggested model is evaluated on the Persian Traffic Sign Dataset and German Traffic Sign Recognition Benchmark and compared with SOTA convolutional and transformer-based models. The experimental evaluations demonstrate that the hybrid network with the locality module outperforms pure transformer-based models and some of the best convolutional networks in accuracy. Specifically, our proposed final model reached 99.66% accuracy in the German traffic sign recognition benchmark and 99.8% in the Persian traffic sign dataset, higher than the best convolutional models. Moreover, it outperforms existing CNNs and ViTs while maintaining fast inference speed. Consequently, the proposed model proves to be significantly faster and more suitable for real-world applications.
Distilling Knowledge from CNN-Transformer Models for Enhanced Human Action Recognition
Nov 02, 2023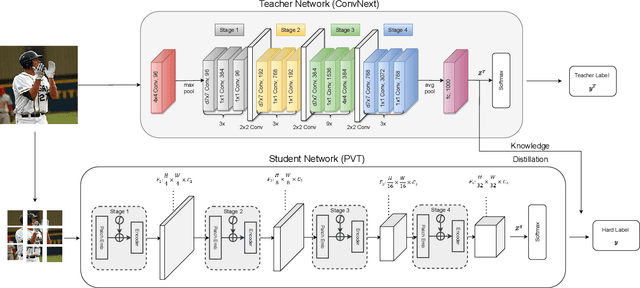
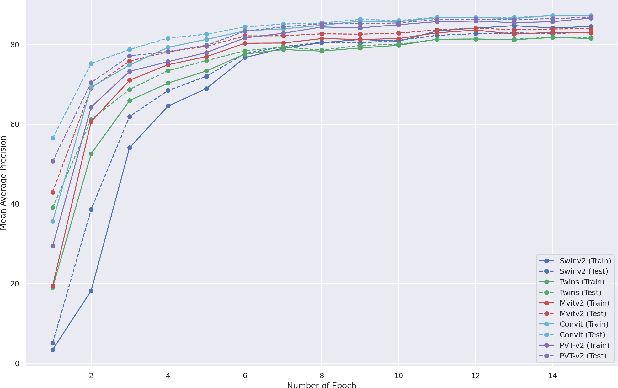
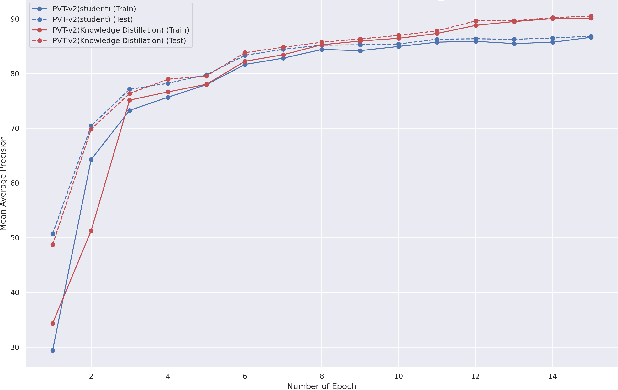
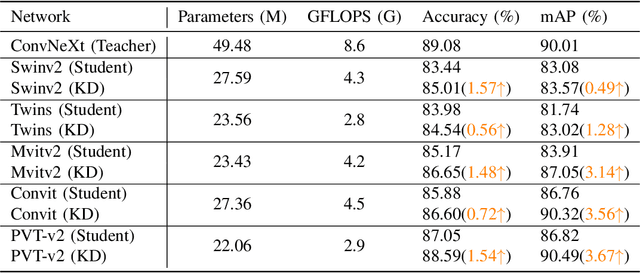
This paper presents a study on improving human action recognition through the utilization of knowledge distillation, and the combination of CNN and ViT models. The research aims to enhance the performance and efficiency of smaller student models by transferring knowledge from larger teacher models. The proposed method employs a Transformer vision network as the student model, while a convolutional network serves as the teacher model. The teacher model extracts local image features, whereas the student model focuses on global features using an attention mechanism. The Vision Transformer (ViT) architecture is introduced as a robust framework for capturing global dependencies in images. Additionally, advanced variants of ViT, namely PVT, Convit, MVIT, Swin Transformer, and Twins, are discussed, highlighting their contributions to computer vision tasks. The ConvNeXt model is introduced as a teacher model, known for its efficiency and effectiveness in computer vision. The paper presents performance results for human action recognition on the Stanford 40 dataset, comparing the accuracy and mAP of student models trained with and without knowledge distillation. The findings illustrate that the suggested approach significantly improves the accuracy and mAP when compared to training networks under regular settings. These findings emphasize the potential of combining local and global features in action recognition tasks.
Dilated-UNet: A Fast and Accurate Medical Image Segmentation Approach using a Dilated Transformer and U-Net Architecture
Apr 22, 2023Medical image segmentation is crucial for the development of computer-aided diagnostic and therapeutic systems, but still faces numerous difficulties. In recent years, the commonly used encoder-decoder architecture based on CNNs has been applied effectively in medical image segmentation, but has limitations in terms of learning global context and spatial relationships. Some researchers have attempted to incorporate transformers into both the decoder and encoder components, with promising results, but this approach still requires further improvement due to its high computational complexity. This paper introduces Dilated-UNet, which combines a Dilated Transformer block with the U-Net architecture for accurate and fast medical image segmentation. Image patches are transformed into tokens and fed into the U-shaped encoder-decoder architecture, with skip-connections for local-global semantic feature learning. The encoder uses a hierarchical Dilated Transformer with a combination of Neighborhood Attention and Dilated Neighborhood Attention Transformer to extract local and sparse global attention. The results of our experiments show that Dilated-UNet outperforms other models on several challenging medical image segmentation datasets, such as ISIC and Synapse.
MedViT: A Robust Vision Transformer for Generalized Medical Image Classification
Feb 19, 2023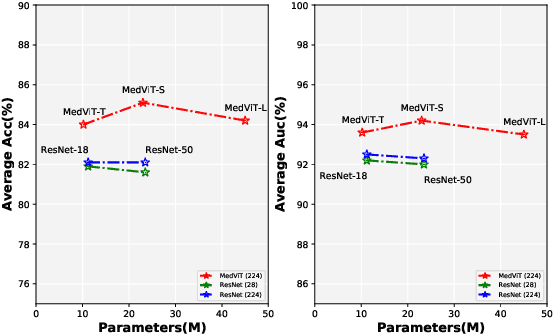
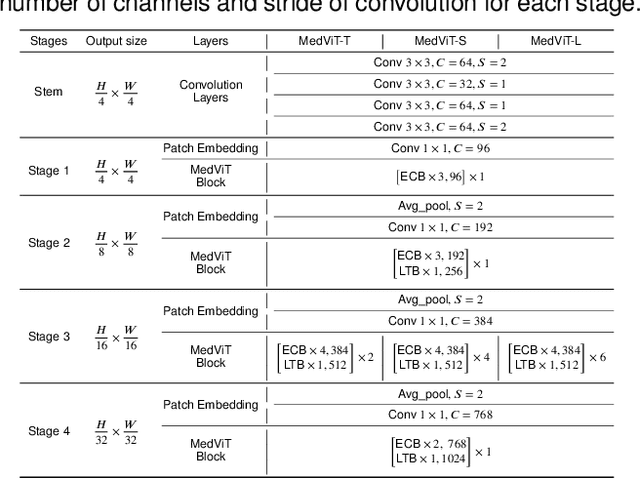
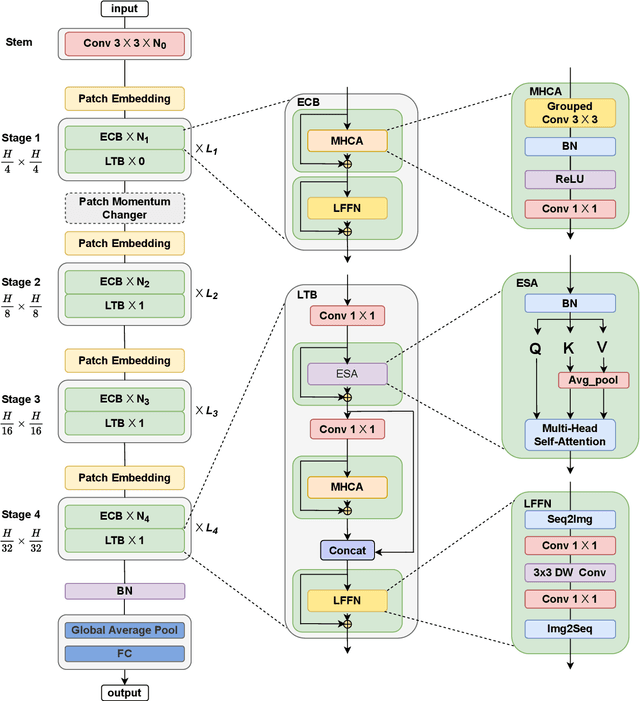
Convolutional Neural Networks (CNNs) have advanced existing medical systems for automatic disease diagnosis. However, there are still concerns about the reliability of deep medical diagnosis systems against the potential threats of adversarial attacks since inaccurate diagnosis could lead to disastrous consequences in the safety realm. In this study, we propose a highly robust yet efficient CNN-Transformer hybrid model which is equipped with the locality of CNNs as well as the global connectivity of vision Transformers. To mitigate the high quadratic complexity of the self-attention mechanism while jointly attending to information in various representation subspaces, we construct our attention mechanism by means of an efficient convolution operation. Moreover, to alleviate the fragility of our Transformer model against adversarial attacks, we attempt to learn smoother decision boundaries. To this end, we augment the shape information of an image in the high-level feature space by permuting the feature mean and variance within mini-batches. With less computational complexity, our proposed hybrid model demonstrates its high robustness and generalization ability compared to the state-of-the-art studies on a large-scale collection of standardized MedMNIST-2D datasets.
Robust Transformer with Locality Inductive Bias and Feature Normalization
Jan 27, 2023Vision transformers have been demonstrated to yield state-of-the-art results on a variety of computer vision tasks using attention-based networks. However, research works in transformers mostly do not investigate robustness/accuracy trade-off, and they still struggle to handle adversarial perturbations. In this paper, we explore the robustness of vision transformers against adversarial perturbations and try to enhance their robustness/accuracy trade-off in white box attack settings. To this end, we propose Locality iN Locality (LNL) transformer model. We prove that the locality introduction to LNL contributes to the robustness performance since it aggregates local information such as lines, edges, shapes, and even objects. In addition, to further improve the robustness performance, we encourage LNL to extract training signal from the moments (a.k.a., mean and standard deviation) and the normalized features. We validate the effectiveness and generality of LNL by achieving state-of-the-art results in terms of accuracy and robustness metrics on German Traffic Sign Recognition Benchmark (GTSRB) and Canadian Institute for Advanced Research (CIFAR-10). More specifically, for traffic sign classification, the proposed LNL yields gains of 1.1% and ~35% in terms of clean and robustness accuracy compared to the state-of-the-art studies.
* 9 pages, 3 Figures, 6 Tables