 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid Transformer for Traffic Sign Detection
Paper and Code
Jul 22, 2022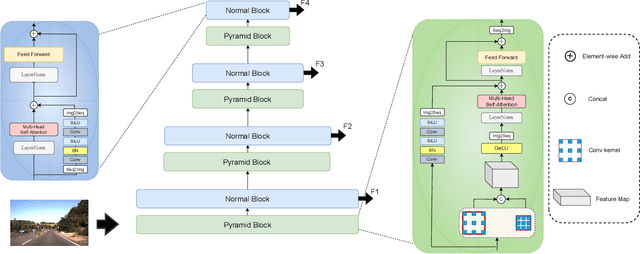
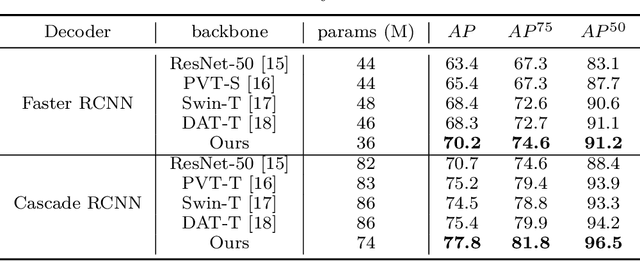
Traffic sign detection is a vital task in the visual system of self-driving cars and the automated driving system. Recently, novel Transformer-based models have achieved encouraging results for various computer vision tasks. We still observed that vanilla ViT could not yield satisfactory results in traffic sign detection because the overall size of the datasets is very small and the class distribution of traffic signs is extremely unbalanced. To overcome this problem, a novel Pyramid Transformer with locality mechanisms is proposed in this paper. Specifically, Pyramid Transformer has several spatial pyramid reduction layers to shrink and embed the input image into tokens with rich multi-scale context by using atrous convolutions. Moreover, it inherits an intrinsic scale invariance inductive bias and is able to learn local feature representation for objects at various scales, thereby enhancing the network robustness against the size discrepancy of traffic signs. The experiments are conducted on the German Traffic Sign Detection Benchmark (GTSDB). The results demonstrate the superiority of the proposed model in the traffic sign detection tasks. More specifically, Pyramid Transformer achieves 77.8% mAP on GTSDB when applied to the Cascade RCNN as the backbone, which surpasses most well-known and widely-used state-of-the-art models.