 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedCLIPSeg: Probabilistic Vision-Language Adaptation for Data-Efficient and Generalizable Medical Image Segmentation
Feb 23, 2026Medical image segmentation remains challenging due to limited annotations for training, ambiguous anatomical features, and domain shifts. While vision-language models such as CLIP offer strong cross-modal representations, their potential for dense, text-guided medical image segmentation remains underexplored. We present MedCLIPSeg, a novel framework that adapts CLIP for robust, data-efficient, and uncertainty-aware medical image segmentation. Our approach leverages patch-level CLIP embeddings through probabilistic cross-modal attention, enabling bidirectional interaction between image and text tokens and explicit modeling of predictive uncertainty. Together with a soft patch-level contrastive loss that encourages more nuanced semantic learning across diverse textual prompts, MedCLIPSeg effectively improves data efficiency and domain generalizability. Extensive experiments across 16 datasets spanning five imaging modalities and six organs demonstrate that MedCLIPSeg outperforms prior methods in accuracy, efficiency, and robustness, while providing interpretable uncertainty maps that highlight local reliability of segmentation results. This work demonstrates the potential of probabilistic vision-language modeling for text-driven medical image segmentation.
Lightweight Physics-Informed Zero-Shot Ultrasound Plane Wave Denoising
Jun 26, 2025Ultrasound Coherent Plane Wave Compounding (CPWC) enhances image contrast by combining echoes from multiple steered transmissions. While increasing the number of angles generally improves image quality, it drastically reduces the frame rate and can introduce blurring artifacts in fast-moving targets. Moreover, compounded images remain susceptible to noise, particularly when acquired with a limited number of transmissions. We propose a zero-shot denoising framework tailored for low-angle CPWC acquisitions, which enhances contrast without relying on a separate training dataset. The method divides the available transmission angles into two disjoint subsets, each used to form compound images that include higher noise levels. The new compounded images are then used to train a deep model via a self-supervised residual learning scheme, enabling it to suppress incoherent noise while preserving anatomical structures. Because angle-dependent artifacts vary between the subsets while the underlying tissue response is similar, this physics-informed pairing allows the network to learn to disentangle the inconsistent artifacts from the consistent tissue signal. Unlike supervised methods, our model requires no domain-specific fine-tuning or paired data, making it adaptable across anatomical regions and acquisition setups. The entire pipeline supports efficient training with low computational cost due to the use of a lightweight architecture, which comprises only two convolutional layers. Evaluations on simulation, phantom, and in vivo data demonstrate superior contrast enhancement and structure preservation compared to both classical and deep learning-based denoising methods.
Medical Image Classification with KAN-Integrated Transformers and Dilated Neighborhood Attention
Feb 19, 2025Convolutional networks, transformers, hybrid models, and Mamba-based architectures have demonstrated strong performance across various medical image classification tasks. However, these methods were primarily designed to classify clean images using labeled data. In contrast, real-world clinical data often involve image corruptions that are unique to multi-center studies and stem from variations in imaging equipment across manufacturers. In this paper, we introduce the Medical Vision Transformer (MedViTV2), a novel architecture incorporating Kolmogorov-Arnold Network (KAN) layers into the transformer architecture for the first time, aiming for generalized medical image classification. We have developed an efficient KAN block to reduce computational load while enhancing the accuracy of the original MedViT. Additionally, to counteract the fragility of our MedViT when scaled up, we propose an enhanced Dilated Neighborhood Attention (DiNA), an adaptation of the efficient fused dot-product attention kernel capable of capturing global context and expanding receptive fields to scale the model effectively and addressing feature collapse issues. Moreover, a hierarchical hybrid strategy is introduced to stack our Local Feature Perception and Global Feature Perception blocks in an efficient manner, which balances local and global feature perceptions to boost performance. Extensive experiments on 17 medical image classification datasets and 12 corrupted medical image datasets demonstrate that MedViTV2 achieved state-of-the-art results in 27 out of 29 experiments with reduced computational complexity. MedViTV2 is 44\% more computationally efficient than the previous version and significantly enhances accuracy, achieving improvements of 4.6\% on MedMNIST, 5.8\% on NonMNIST, and 13.4\% on the MedMNIST-C benchmark.
BiomedCoOp: Learning to Prompt for Biomedical Vision-Language Models
Nov 21, 2024



Recent advancements in vision-language models (VLMs), such as CLIP, have demonstrated substantial success in self-supervised representation learning for vision tasks. However, effectively adapting VLMs to downstream applications remains challenging, as their accuracy often depends on time-intensive and expertise-demanding prompt engineering, while full model fine-tuning is costly. This is particularly true for biomedical images, which, unlike natural images, typically suffer from limited annotated datasets, unintuitive image contrasts, and nuanced visual features. Recent prompt learning techniques, such as Context Optimization (CoOp) intend to tackle these issues, but still fall short in generalizability. Meanwhile, explorations in prompt learning for biomedical image analysis are still highly limited. In this work, we propose BiomedCoOp, a novel prompt learning framework that enables efficient adaptation of BiomedCLIP for accurate and highly generalizable few-shot biomedical image classification. Our approach achieves effective prompt context learning by leveraging semantic consistency with average prompt ensembles from Large Language Models (LLMs) and knowledge distillation with a statistics-based prompt selection strategy. We conducted comprehensive validation of our proposed framework on 11 medical datasets across 9 modalities and 10 organs against existing state-of-the-art methods, demonstrating significant improvements in both accuracy and generalizability. The code will be publicly available at https://github.com/HealthX-Lab/BiomedCoOp.
MedCLIP-SAMv2: Towards Universal Text-Driven Medical Image Segmentation
Sep 28, 2024

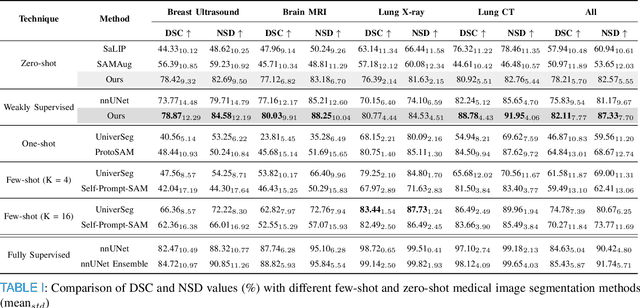

Segmentation of anatomical structures and pathological regions in medical images is essential for modern clinical diagnosis, disease research, and treatment planning. While significant advancements have been made in deep learning-based segmentation techniques, many of these methods still suffer from limitations in data efficiency, generalizability, and interactivity. As a result, developing precise segmentation methods that require fewer labeled datasets remains a critical challenge in medical image analysis. Recently, the introduction of foundation models like CLIP and Segment-Anything-Model (SAM), with robust cross-domain representations, has paved the way for interactive and universal image segmentation. However, further exploration of these models for data-efficient segmentation in medical imaging is still needed and highly relevant. In this paper, we introduce MedCLIP-SAMv2, a novel framework that integrates the CLIP and SAM models to perform segmentation on clinical scans using text prompts, in both zero-shot and weakly supervised settings. Our approach includes fine-tuning the BiomedCLIP model with a new Decoupled Hard Negative Noise Contrastive Estimation (DHN-NCE) loss, and leveraging the Multi-modal Information Bottleneck (M2IB) to create visual prompts for generating segmentation masks from SAM in the zero-shot setting. We also investigate using zero-shot segmentation labels within a weakly supervised paradigm to enhance segmentation quality further. Extensive testing across four diverse segmentation tasks and medical imaging modalities (breast tumor ultrasound, brain tumor MRI, lung X-ray, and lung CT) demonstrates the high accuracy of our proposed framework. Our code is available at https://github.com/HealthX-Lab/MedCLIP-SAMv2.
Denoising Plane Wave Ultrasound Images Using Diffusion Probabilistic Models
Aug 20, 2024



Ultrasound plane wave imaging is a cutting-edge technique that enables high frame-rate imaging. However, one challenge associated with high frame-rate ultrasound imaging is the high noise associated with them, hindering their wider adoption. Therefore, the development of a denoising method becomes imperative to augment the quality of plane wave images. Drawing inspiration from Denoising Diffusion Probabilistic Models (DDPMs), our proposed solution aims to enhance plane wave image quality. Specifically, the method considers the distinction between low-angle and high-angle compounding plane waves as noise and effectively eliminates it by adapting a DDPM to beamformed radiofrequency (RF) data. The method underwent training using only 400 simulated images. In addition, our approach employs natural image segmentation masks as intensity maps for the generated images, resulting in accurate denoising for various anatomy shapes. The proposed method was assessed across simulation, phantom, and in vivo images. The results of the evaluations indicate that our approach not only enhances image quality on simulated data but also demonstrates effectiveness on phantom and in vivo data in terms of image quality. Comparative analysis with other methods underscores the superiority of our proposed method across various evaluation metrics. The source code and trained model will be released along with the dataset at: http://code.sonography.ai
MedCLIP-SAM: Bridging Text and Image Towards Universal Medical Image Segmentation
Mar 29, 2024Medical image segmentation of anatomical structures and pathology is crucial in modern clinical diagnosis, disease study, and treatment planning. To date, great progress has been made in deep learning-based segmentation techniques, but most methods still lack data efficiency, generalizability, and interactability. Consequently, the development of new, precise segmentation methods that demand fewer labeled datasets is of utmost importance in medical image analysis. Recently, the emergence of foundation models, such as CLIP and Segment-Anything-Model (SAM), with comprehensive cross-domain representation opened the door for interactive and universal image segmentation. However, exploration of these models for data-efficient medical image segmentation is still limited, but is highly necessary. In this paper, we propose a novel framework, called MedCLIP-SAM that combines CLIP and SAM models to generate segmentation of clinical scans using text prompts in both zero-shot and weakly supervised settings. To achieve this, we employed a new Decoupled Hard Negative Noise Contrastive Estimation (DHN-NCE) loss to fine-tune the BiomedCLIP model and the recent gScoreCAM to generate prompts to obtain segmentation masks from SAM in a zero-shot setting. Additionally, we explored the use of zero-shot segmentation labels in a weakly supervised paradigm to improve the segmentation quality further. By extensively testing three diverse segmentation tasks and medical image modalities (breast tumor ultrasound, brain tumor MRI, and lung X-ray), our proposed framework has demonstrated excellent accuracy.
Deep Ultrasound Denoising Using Diffusion Probabilistic Models
Jun 12, 2023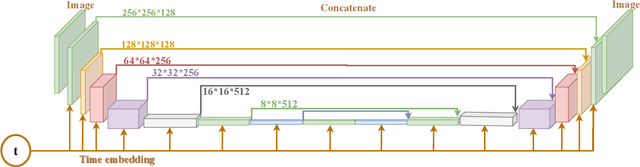
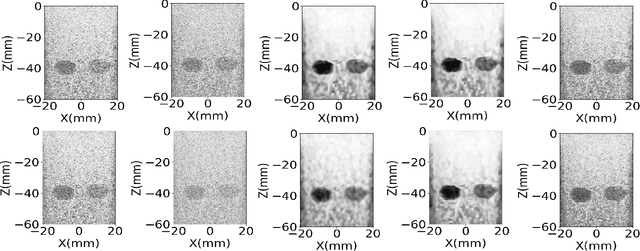


Ultrasound images are widespread in medical diagnosis for musculoskeletal, cardiac, and obstetrical imaging due to the efficiency and non-invasiveness of the acquisition methodology. However, the acquired images are degraded by acoustic (e.g. reverberation and clutter) and electronic sources of noise. To improve the Peak Signal to Noise Ratio (PSNR) of the images, previous denoising methods often remove the speckles, which could be informative for radiologists and also for quantitative ultrasound. Herein, a method based on the recent Denoising Diffusion Probabilistic Models (DDPM) is proposed. It iteratively enhances the image quality by eliminating the noise while preserving the speckle texture. It is worth noting that the proposed method is trained in a completely unsupervised manner, and no annotated data is required. The experimental blind test results show that our method outperforms the previous nonlocal means denoising methods in terms of PSNR and Generalized Contrast to Noise Ratio (GCNR) while preserving speckles.