 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Attention-based Deep Network via Multi-Scale Feature Fusion for Multi-View Facial Expression Recognition
Mar 21, 2024Convolutional neural networks (CNNs) and their variations have shown effectiveness in facial expression recognition (FER). However, they face challenges when dealing with high computational complexity and multi-view head poses in real-world scenarios. We introduce a lightweight attentional network incorporating multi-scale feature fusion (LANMSFF) to tackle these issues. For the first challenge, we have carefully designed a lightweight fully convolutional network (FCN). We address the second challenge by presenting two novel components, namely mass attention (MassAtt) and point wise feature selection (PWFS) blocks. The MassAtt block simultaneously generates channel and spatial attention maps to recalibrate feature maps by emphasizing important features while suppressing irrelevant ones. On the other hand, the PWFS block employs a feature selection mechanism that discards less meaningful features prior to the fusion process. This mechanism distinguishes it from previous methods that directly fuse multi-scale features. Our proposed approach achieved results comparable to state-of-the-art methods in terms of parameter counts and robustness to pose variation, with accuracy rates of 90.77% on KDEF, 70.44% on FER-2013, and 86.96% on FERPlus datasets. The code for LANMSFF is available at https://github.com/AE-1129/LANMSFF.
Distilling Knowledge from CNN-Transformer Models for Enhanced Human Action Recognition
Nov 02, 2023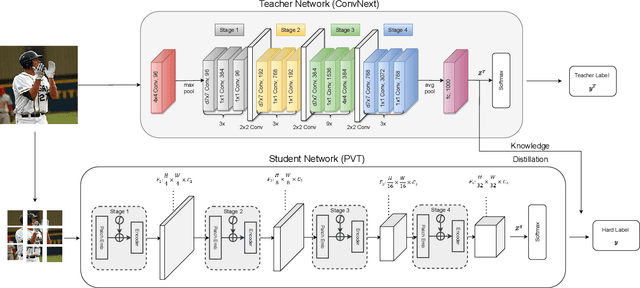
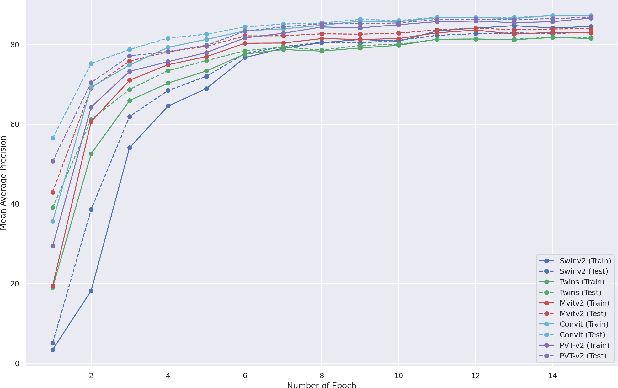
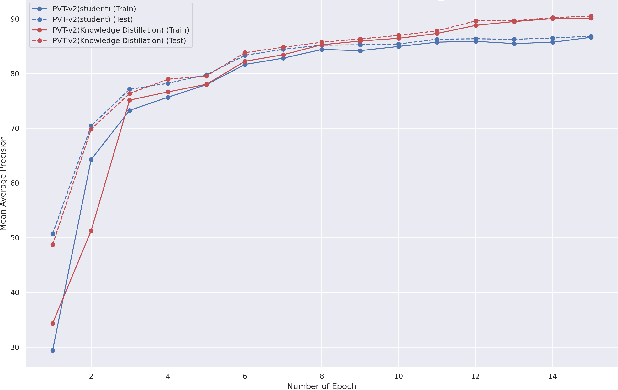
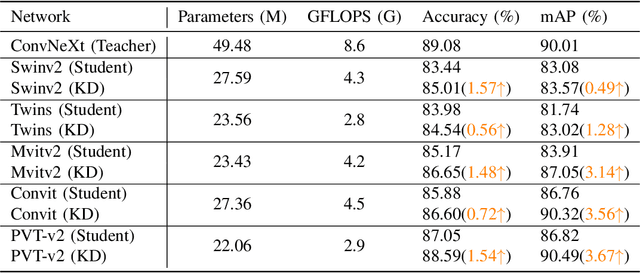
This paper presents a study on improving human action recognition through the utilization of knowledge distillation, and the combination of CNN and ViT models. The research aims to enhance the performance and efficiency of smaller student models by transferring knowledge from larger teacher models. The proposed method employs a Transformer vision network as the student model, while a convolutional network serves as the teacher model. The teacher model extracts local image features, whereas the student model focuses on global features using an attention mechanism. The Vision Transformer (ViT) architecture is introduced as a robust framework for capturing global dependencies in images. Additionally, advanced variants of ViT, namely PVT, Convit, MVIT, Swin Transformer, and Twins, are discussed, highlighting their contributions to computer vision tasks. The ConvNeXt model is introduced as a teacher model, known for its efficiency and effectiveness in computer vision. The paper presents performance results for human action recognition on the Stanford 40 dataset, comparing the accuracy and mAP of student models trained with and without knowledge distillation. The findings illustrate that the suggested approach significantly improves the accuracy and mAP when compared to training networks under regular settings. These findings emphasize the potential of combining local and global features in action recognition tasks.
MedViT: A Robust Vision Transformer for Generalized Medical Image Classification
Feb 19, 2023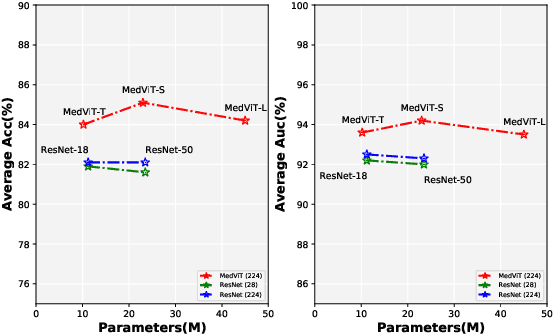
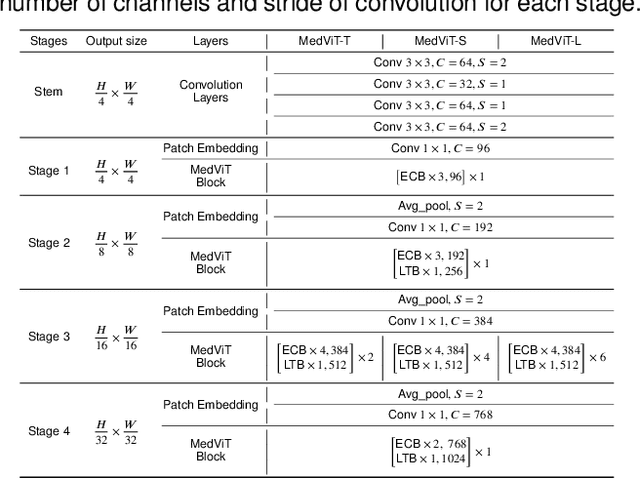
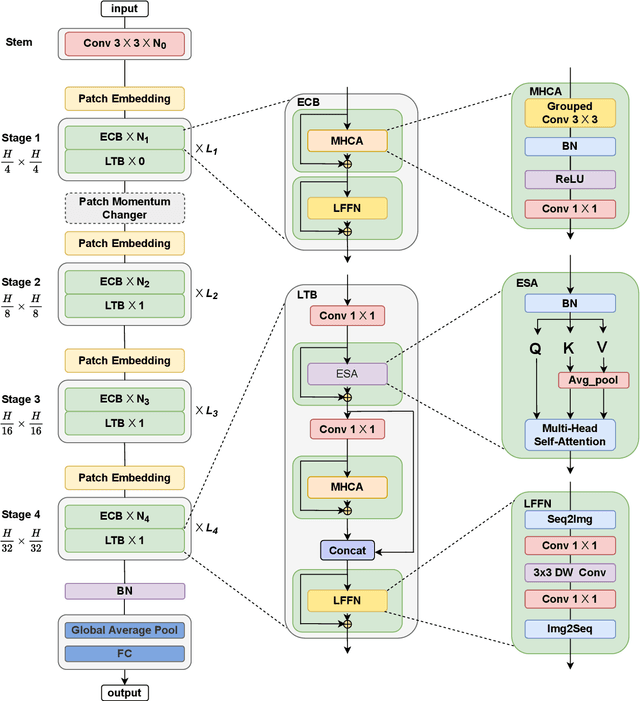
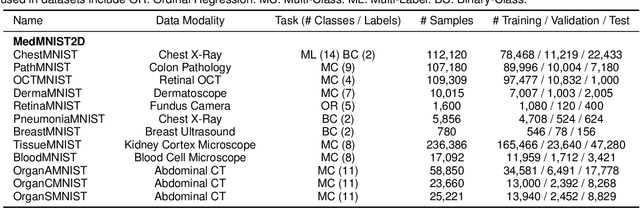
Convolutional Neural Networks (CNNs) have advanced existing medical systems for automatic disease diagnosis. However, there are still concerns about the reliability of deep medical diagnosis systems against the potential threats of adversarial attacks since inaccurate diagnosis could lead to disastrous consequences in the safety realm. In this study, we propose a highly robust yet efficient CNN-Transformer hybrid model which is equipped with the locality of CNNs as well as the global connectivity of vision Transformers. To mitigate the high quadratic complexity of the self-attention mechanism while jointly attending to information in various representation subspaces, we construct our attention mechanism by means of an efficient convolution operation. Moreover, to alleviate the fragility of our Transformer model against adversarial attacks, we attempt to learn smoother decision boundaries. To this end, we augment the shape information of an image in the high-level feature space by permuting the feature mean and variance within mini-batches. With less computational complexity, our proposed hybrid model demonstrates its high robustness and generalization ability compared to the state-of-the-art studies on a large-scale collection of standardized MedMNIST-2D datasets.
HeartSiam: A Domain Invariant Model for Heart Sound Classification
Oct 28, 2022Cardiovascular disease is one of the leading causes of death according to WHO. Phonocardiography (PCG) is a costeffective, non-invasive method suitable for heart monitoring. The main aim of this work is to classify heart sounds into normal/abnormal categories. Heart sounds are recorded using different stethoscopes, thus varying in the domain. Based on recent studies, this variability can affect heart sound classification. This work presents a Siamese network architecture for learning the similarity between normal vs. normal or abnormal vs. abnormal signals and the difference between normal vs. abnormal signals. By applying this similarity and difference learning across all domains, the task of domain invariant heart sound classification can be well achieved. We have used the multi-domain 2016 Physionet/CinC challenge dataset for the evaluation method. Results: On the evaluation set provided by the challenge, we have achieved a sensitivity of 82.8%, specificity of 75.3%, and mean accuracy of 79.1%. While overcoming the multi-domain problem, the proposed method has surpassed the first-place method of the Physionet challenge in terms of specificity up to 10.9% and mean accuracy up to 5.6%. Also, compared with similar state-of-the-art domain invariant methods, our model converges faster and performs better in specificity (4.1%) and mean accuracy (1.5%) with an equal number of epochs learned.
Multi-Expert Human Action Recognition with Hierarchical Super-Class Learning
Dec 13, 2021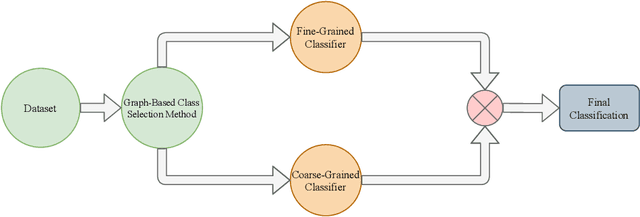



In still image human action recognition, existing studies have mainly leveraged extra bounding box information along with class labels to mitigate the lack of temporal information in still images; however, preparing extra data with manual annotation is time-consuming and also prone to human errors. Moreover, the existing studies have not addressed action recognition with long-tailed distribution. In this paper, we propose a two-phase multi-expert classification method for human action recognition to cope with long-tailed distribution by means of super-class learning and without any extra information. To choose the best configuration for each super-class and characterize inter-class dependency between different action classes, we propose a novel Graph-Based Class Selection (GCS) algorithm. In the proposed approach, a coarse-grained phase selects the most relevant fine-grained experts. Then, the fine-grained experts encode the intricate details within each super-class so that the inter-class variation increases. Extensive experimental evaluations are conducted on various public human action recognition datasets, including Stanford40, Pascal VOC 2012 Action, BU101+, and IHAR datasets. The experimental results demonstrate that the proposed method yields promising improvements. To be more specific, in IHAR, Sanford40, Pascal VOC 2012 Action, and BU101+ benchmarks, the proposed approach outperforms the state-of-the-art studies by 8.92%, 0.41%, 0.66%, and 2.11 % with much less computational cost and without any auxiliary annotation information. Besides, it is proven that in addressing action recognition with long-tailed distribution, the proposed method outperforms its counterparts by a significant margin.
Online Visual Tracking with One-Shot Context-Aware Domain Adaptation
Aug 22, 2020
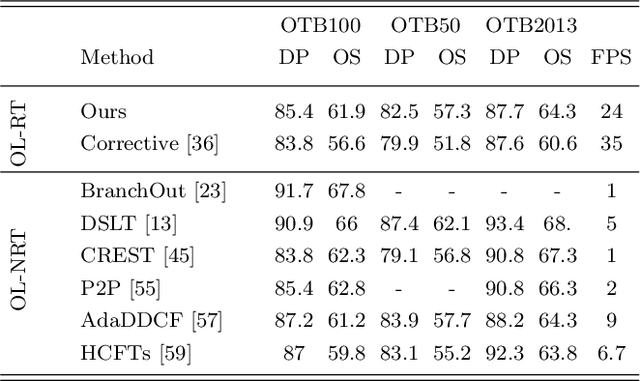

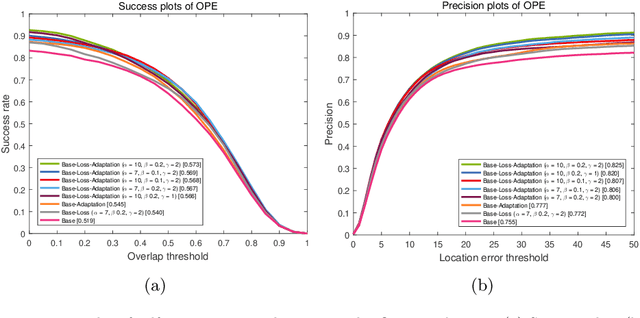
Online learning policy makes visual trackers more robust against different distortions through learning domain-specific cues. However, the trackers adopting this policy fail to fully leverage the discriminative context of the background areas. Moreover, owing to the lack of sufficient data at each time step, the online learning approach can also make the trackers prone to over-fitting to the background regions. In this paper, we propose a domain adaptation approach to strengthen the contributions of the semantic background context. The domain adaptation approach is backboned with only an off-the-shelf deep model. The strength of the proposed approach comes from its discriminative ability to handle severe occlusion and background clutter challenges. We further introduce a cost-sensitive loss alleviating the dominance of non-semantic background candidates over the semantic candidates, thereby dealing with the data imbalance issue. Experimental results demonstrate that our tracker achieves competitive results at real-time speed compared to the state-of-the-art trackers.
Lumen boundary detection using neutrosophic c-means in IVOCT images
Feb 16, 2019
In this paper, a novel method for lumen boundary identification is proposed using Neutrosophic c_means. This method clusters pixels of the intravascular optical coherence tomography image into several clusters using indeterminacy and Neutrosophic theory, which aims to detect the boundaries. Intravascular optical coherence tomography images are cross-sectional and high-resolution images which are taken from the coronary arterial wall. Coronary Artery Disease cause a lot of death each year. The first step for diagnosing this kind of diseases is to detect lumen boundary. Employing this approach, we obtained 0.972, 0.019, 0.076 mm2, 0.32 mm, and 0.985 as mean value for Jaccard measure (JACC), the percentage of area difference (PAD), average distance (AD), Hausdorff distance (HD), and dice index (DI), respectively. Based on our results, this method enjoys high accuracy performance.