 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Knowledge from CNN-Transformer Models for Enhanced Human Action Recognition
Nov 02, 2023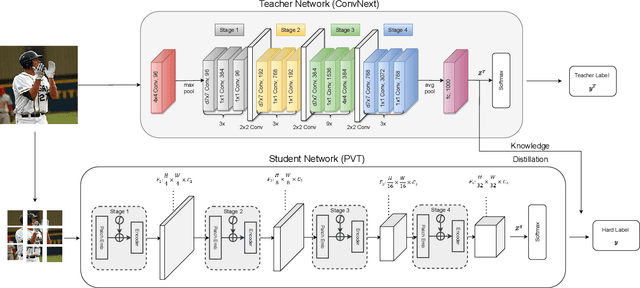
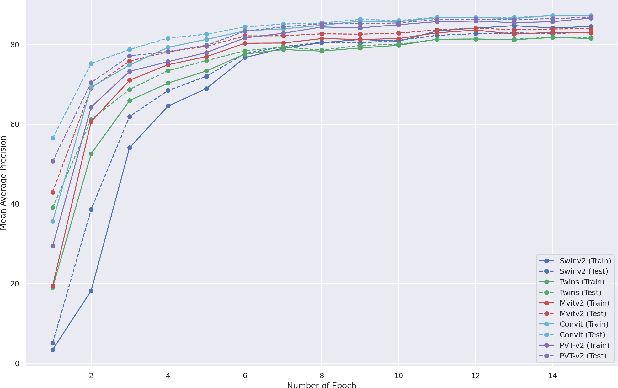
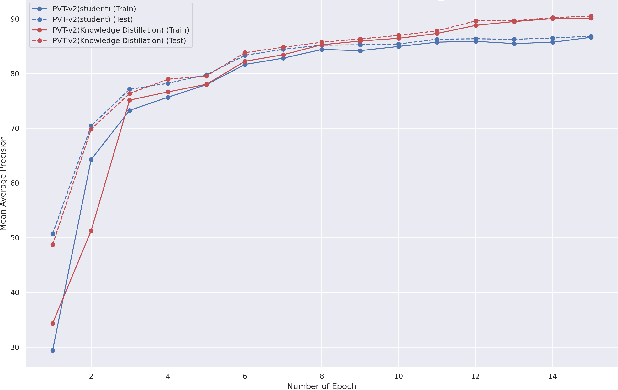
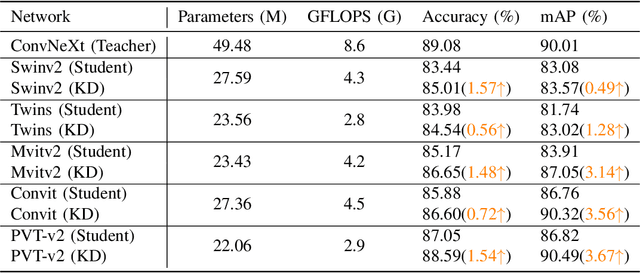
This paper presents a study on improving human action recognition through the utilization of knowledge distillation, and the combination of CNN and ViT models. The research aims to enhance the performance and efficiency of smaller student models by transferring knowledge from larger teacher models. The proposed method employs a Transformer vision network as the student model, while a convolutional network serves as the teacher model. The teacher model extracts local image features, whereas the student model focuses on global features using an attention mechanism. The Vision Transformer (ViT) architecture is introduced as a robust framework for capturing global dependencies in images. Additionally, advanced variants of ViT, namely PVT, Convit, MVIT, Swin Transformer, and Twins, are discussed, highlighting their contributions to computer vision tasks. The ConvNeXt model is introduced as a teacher model, known for its efficiency and effectiveness in computer vision. The paper presents performance results for human action recognition on the Stanford 40 dataset, comparing the accuracy and mAP of student models trained with and without knowledge distillation. The findings illustrate that the suggested approach significantly improves the accuracy and mAP when compared to training networks under regular settings. These findings emphasize the potential of combining local and global features in action recognition tasks.
MedViT: A Robust Vision Transformer for Generalized Medical Image Classification
Feb 19, 2023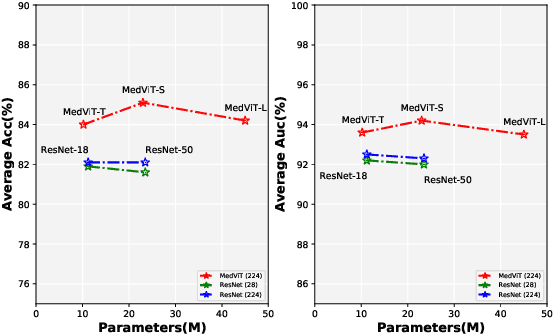
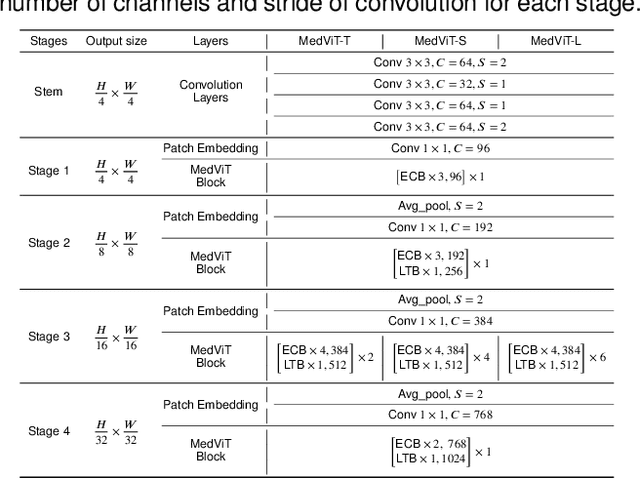
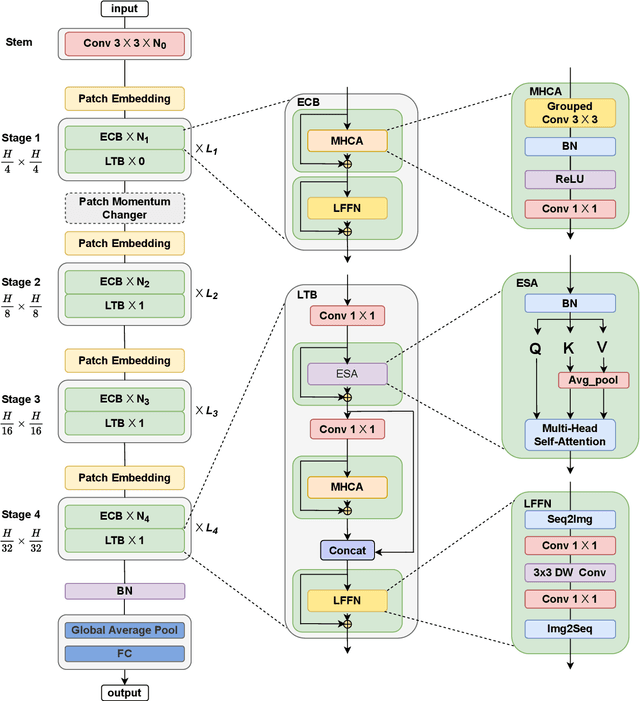
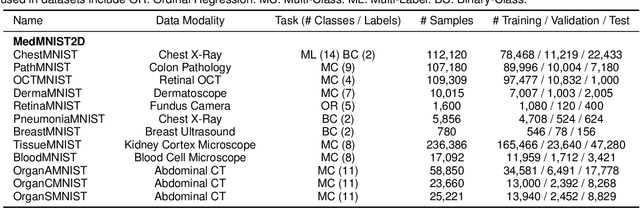
Convolutional Neural Networks (CNNs) have advanced existing medical systems for automatic disease diagnosis. However, there are still concerns about the reliability of deep medical diagnosis systems against the potential threats of adversarial attacks since inaccurate diagnosis could lead to disastrous consequences in the safety realm. In this study, we propose a highly robust yet efficient CNN-Transformer hybrid model which is equipped with the locality of CNNs as well as the global connectivity of vision Transformers. To mitigate the high quadratic complexity of the self-attention mechanism while jointly attending to information in various representation subspaces, we construct our attention mechanism by means of an efficient convolution operation. Moreover, to alleviate the fragility of our Transformer model against adversarial attacks, we attempt to learn smoother decision boundaries. To this end, we augment the shape information of an image in the high-level feature space by permuting the feature mean and variance within mini-batches. With less computational complexity, our proposed hybrid model demonstrates its high robustness and generalization ability compared to the state-of-the-art studies on a large-scale collection of standardized MedMNIST-2D datasets.