 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Transformer with Locality Inductive Bias and Feature Normalization
Jan 27, 2023Vision transformers have been demonstrated to yield state-of-the-art results on a variety of computer vision tasks using attention-based networks. However, research works in transformers mostly do not investigate robustness/accuracy trade-off, and they still struggle to handle adversarial perturbations. In this paper, we explore the robustness of vision transformers against adversarial perturbations and try to enhance their robustness/accuracy trade-off in white box attack settings. To this end, we propose Locality iN Locality (LNL) transformer model. We prove that the locality introduction to LNL contributes to the robustness performance since it aggregates local information such as lines, edges, shapes, and even objects. In addition, to further improve the robustness performance, we encourage LNL to extract training signal from the moments (a.k.a., mean and standard deviation) and the normalized features. We validate the effectiveness and generality of LNL by achieving state-of-the-art results in terms of accuracy and robustness metrics on German Traffic Sign Recognition Benchmark (GTSRB) and Canadian Institute for Advanced Research (CIFAR-10). More specifically, for traffic sign classification, the proposed LNL yields gains of 1.1% and ~35% in terms of clean and robustness accuracy compared to the state-of-the-art studies.
* 9 pages, 3 Figures, 6 Tables
Multi-Expert Human Action Recognition with Hierarchical Super-Class Learning
Dec 13, 2021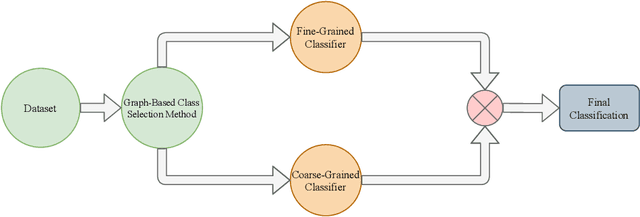



In still image human action recognition, existing studies have mainly leveraged extra bounding box information along with class labels to mitigate the lack of temporal information in still images; however, preparing extra data with manual annotation is time-consuming and also prone to human errors. Moreover, the existing studies have not addressed action recognition with long-tailed distribution. In this paper, we propose a two-phase multi-expert classification method for human action recognition to cope with long-tailed distribution by means of super-class learning and without any extra information. To choose the best configuration for each super-class and characterize inter-class dependency between different action classes, we propose a novel Graph-Based Class Selection (GCS) algorithm. In the proposed approach, a coarse-grained phase selects the most relevant fine-grained experts. Then, the fine-grained experts encode the intricate details within each super-class so that the inter-class variation increases. Extensive experimental evaluations are conducted on various public human action recognition datasets, including Stanford40, Pascal VOC 2012 Action, BU101+, and IHAR datasets. The experimental results demonstrate that the proposed method yields promising improvements. To be more specific, in IHAR, Sanford40, Pascal VOC 2012 Action, and BU101+ benchmarks, the proposed approach outperforms the state-of-the-art studies by 8.92%, 0.41%, 0.66%, and 2.11 % with much less computational cost and without any auxiliary annotation information. Besides, it is proven that in addressing action recognition with long-tailed distribution, the proposed method outperforms its counterparts by a significant margin.