 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Vehicle Make and Model Recognition with 3D Attention Modules
Feb 21, 2025Vehicle make and model recognition (VMMR) is a crucial component of the Intelligent Transport System, garnering significant attention in recent years. VMMR has been widely utilized for detecting suspicious vehicles, monitoring urban traffic, and autonomous driving systems. The complexity of VMMR arises from the subtle visual distinctions among vehicle models and the wide variety of classes produced by manufacturers. Convolutional Neural Networks (CNNs), a prominent type of deep learning model, have been extensively employed in various computer vision tasks, including VMMR, yielding remarkable results. As VMMR is a fine-grained classification problem, it primarily faces inter-class similarity and intra-class variation challenges. In this study, we implement an attention module to address these challenges and enhance the model's focus on critical areas containing distinguishing features. This module, which does not increase the parameters of the original model, generates three-dimensional (3-D) attention weights to refine the feature map. Our proposed model integrates the attention module into two different locations within the middle section of a convolutional model, where the feature maps from these sections offer sufficient information about the input frames without being overly detailed or overly coarse. The performance of our proposed model, along with state-of-the-art (SOTA) convolutional and transformer-based models, was evaluated using the Stanford Cars dataset. Our proposed model achieved the highest accuracy, 90.69\%, among the compared models.
CSFNet: A Cosine Similarity Fusion Network for Real-Time RGB-X Semantic Segmentation of Driving Scenes
Jul 01, 2024



Semantic segmentation, as a crucial component of complex visual interpretation, plays a fundamental role in autonomous vehicle vision systems. Recent studies have significantly improved the accuracy of semantic segmentation by exploiting complementary information and developing multimodal methods. Despite the gains in accuracy, multimodal semantic segmentation methods suffer from high computational complexity and low inference speed. Therefore, it is a challenging task to implement multimodal methods in driving applications. To address this problem, we propose the Cosine Similarity Fusion Network (CSFNet) as a real-time RGB-X semantic segmentation model. Specifically, we design a Cosine Similarity Attention Fusion Module (CS-AFM) that effectively rectifies and fuses features of two modalities. The CS-AFM module leverages cross-modal similarity to achieve high generalization ability. By enhancing the fusion of cross-modal features at lower levels, CS-AFM paves the way for the use of a single-branch network at higher levels. Therefore, we use dual and single-branch architectures in an encoder, along with an efficient context module and a lightweight decoder for fast and accurate predictions. To verify the effectiveness of CSFNet, we use the Cityscapes, MFNet, and ZJU datasets for the RGB-D/T/P semantic segmentation. According to the results, CSFNet has competitive accuracy with state-of-the-art methods while being state-of-the-art in terms of speed among multimodal semantic segmentation models. It also achieves high efficiency due to its low parameter count and computational complexity. The source code for CSFNet will be available at https://github.com/Danial-Qashqai/CSFNet.
Dilated-UNet: A Fast and Accurate Medical Image Segmentation Approach using a Dilated Transformer and U-Net Architecture
Apr 22, 2023Medical image segmentation is crucial for the development of computer-aided diagnostic and therapeutic systems, but still faces numerous difficulties. In recent years, the commonly used encoder-decoder architecture based on CNNs has been applied effectively in medical image segmentation, but has limitations in terms of learning global context and spatial relationships. Some researchers have attempted to incorporate transformers into both the decoder and encoder components, with promising results, but this approach still requires further improvement due to its high computational complexity. This paper introduces Dilated-UNet, which combines a Dilated Transformer block with the U-Net architecture for accurate and fast medical image segmentation. Image patches are transformed into tokens and fed into the U-shaped encoder-decoder architecture, with skip-connections for local-global semantic feature learning. The encoder uses a hierarchical Dilated Transformer with a combination of Neighborhood Attention and Dilated Neighborhood Attention Transformer to extract local and sparse global attention. The results of our experiments show that Dilated-UNet outperforms other models on several challenging medical image segmentation datasets, such as ISIC and Synapse.
Using Genetic Algorithm in the Evolutionary Design of Sequential Logic Circuits
Oct 05, 2011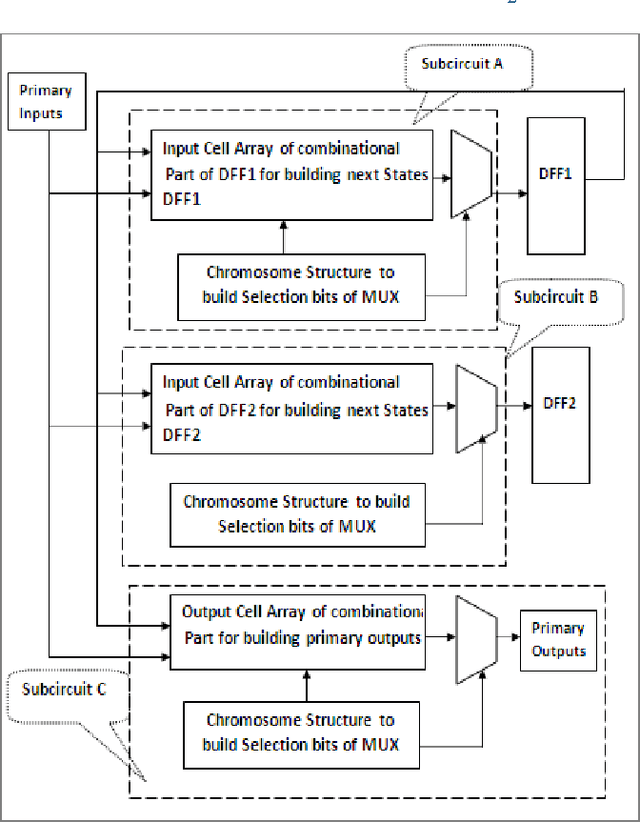
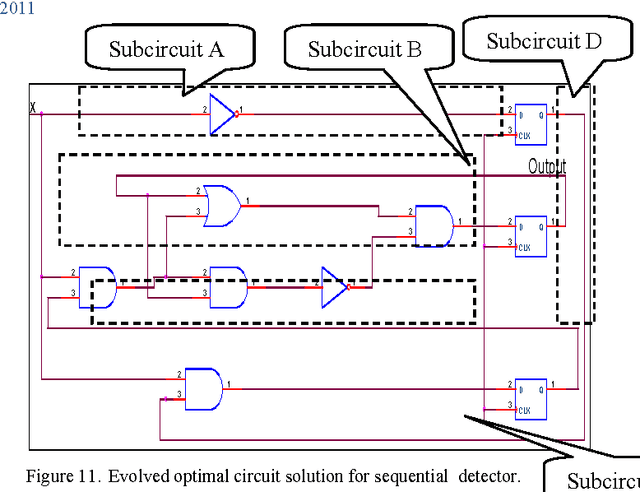
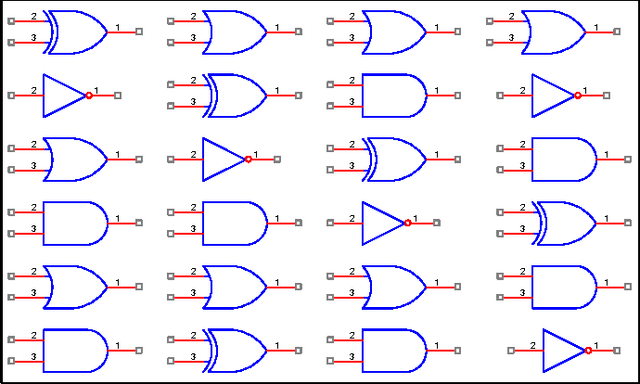
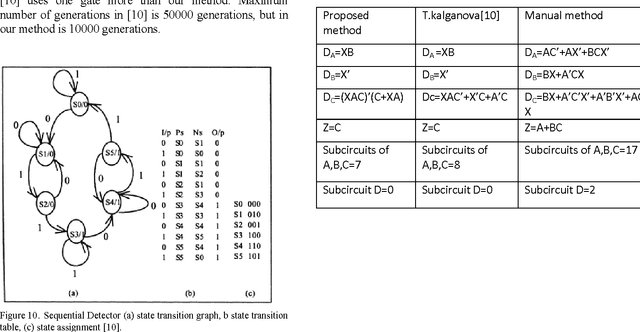
Evolvable hardware (EHW) is a set of techniques that are based on the idea of combining reconfiguration hardware systems with evolutionary algorithms. In other word, EHW has two sections; the reconfigurable hardware and evolutionary algorithm where the configurations are under the control of an evolutionary algorithm. This paper, suggests a method to design and optimize the synchronous sequential circuits. Genetic algorithm (GA) was applied as evolutionary algorithm. In this approach, for building input combinational logic circuit of each DFF, and also output combinational logic circuit, the cell arrays have been used. The obtained results show that our method can reduce the average number of generations by limitation the search space.