 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDCT: Frequency-Aware Decomposition and Cross-Modal Token-Alignment for Multi-Sensor Target Classification
Mar 12, 2025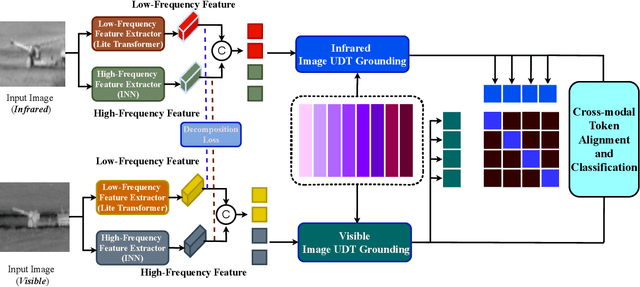
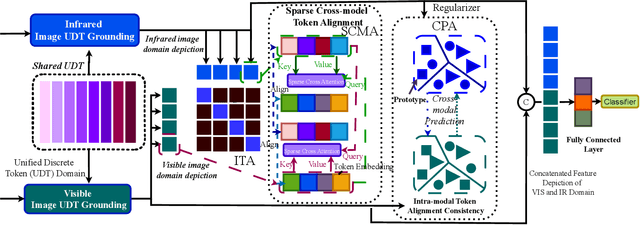
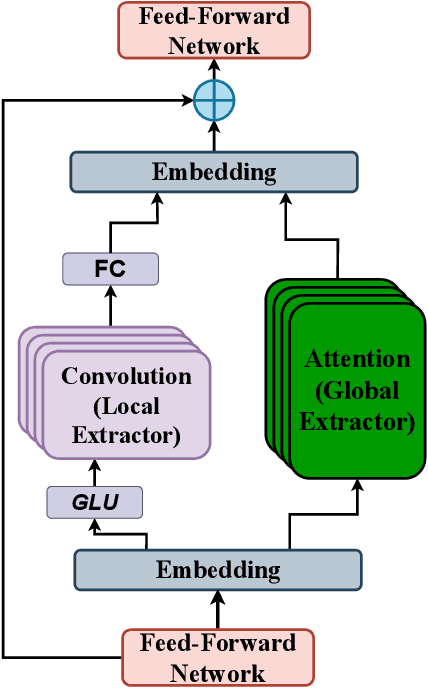
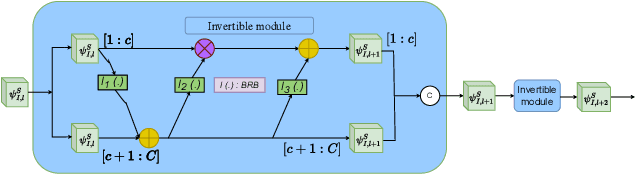
In automatic target recognition (ATR) systems, sensors may fail to capture discriminative, fine-grained detail features due to environmental conditions, noise created by CMOS chips, occlusion, parallaxes, and sensor misalignment. Therefore, multi-sensor image fusion is an effective choice to overcome these constraints. However, multi-modal image sensors are heterogeneous and have domain and granularity gaps. In addition, the multi-sensor images can be misaligned due to intricate background clutters, fluctuating illumination conditions, and uncontrolled sensor settings. In this paper, to overcome these issues, we decompose, align, and fuse multiple image sensor data for target classification. We extract the domain-specific and domain-invariant features from each sensor data. We propose to develop a shared unified discrete token (UDT) space between sensors to reduce the domain and granularity gaps. Additionally, we develop an alignment module to overcome the misalignment between multi-sensors and emphasize the discriminative representation of the UDT space. In the alignment module, we introduce sparsity constraints to provide a better cross-modal representation of the UDT space and robustness against various sensor settings. We achieve superior classification performance compared to single-modality classifiers and several state-of-the-art multi-modal fusion algorithms on four multi-sensor ATR datasets.
CLFace: A Scalable and Resource-Efficient Continual Learning Framework for Lifelong Face Recognition
Nov 21, 2024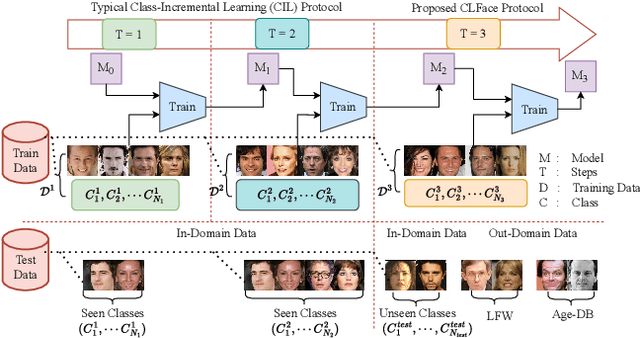

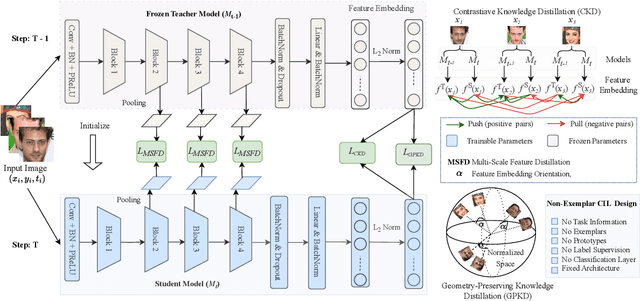
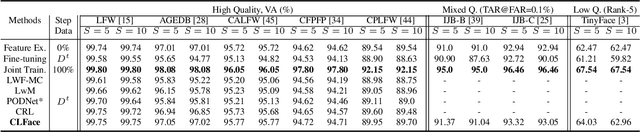
An important aspect of deploying face recognition (FR) algorithms in real-world applications is their ability to learn new face identities from a continuous data stream. However, the online training of existing deep neural network-based FR algorithms, which are pre-trained offline on large-scale stationary datasets, encounter two major challenges: (I) catastrophic forgetting of previously learned identities, and (II) the need to store past data for complete retraining from scratch, leading to significant storage constraints and privacy concerns. In this paper, we introduce CLFace, a continual learning framework designed to preserve and incrementally extend the learned knowledge. CLFace eliminates the classification layer, resulting in a resource-efficient FR model that remains fixed throughout lifelong learning and provides label-free supervision to a student model, making it suitable for open-set face recognition during incremental steps. We introduce an objective function that employs feature-level distillation to reduce drift between feature maps of the student and teacher models across multiple stages. Additionally, it incorporates a geometry-preserving distillation scheme to maintain the orientation of the teacher model's feature embedding. Furthermore, a contrastive knowledge distillation is incorporated to continually enhance the discriminative power of the feature representation by matching similarities between new identities. Experiments on several benchmark FR datasets demonstrate that CLFace outperforms baseline approaches and state-of-the-art methods on unseen identities using both in-domain and out-of-domain datasets.
HF-Diff: High-Frequency Perceptual Loss and Distribution Matching for One-Step Diffusion-Based Image Super-Resolution
Nov 20, 2024Although recent diffusion-based single-step super-resolution methods achieve better performance as compared to SinSR, they are computationally complex. To improve the performance of SinSR, we investigate preserving the high-frequency detail features during super-resolution (SR) because the downgraded images lack detailed information. For this purpose, we introduce a high-frequency perceptual loss by utilizing an invertible neural network (INN) pretrained on the ImageNet dataset. Different feature maps of pretrained INN produce different high-frequency aspects of an image. During the training phase, we impose to preserve the high-frequency features of super-resolved and ground truth (GT) images that improve the SR image quality during inference. Furthermore, we also utilize the Jenson-Shannon divergence between GT and SR images in the pretrained DINO-v2 embedding space to match their distribution. By introducing the $\textbf{h}igh$- $\textbf{f}requency$ preserving loss and distribution matching constraint in the single-step $\textbf{diff}usion-based$ SR ($\textbf{HF-Diff}$), we achieve a state-of-the-art CLIPIQA score in the benchmark RealSR, RealSet65, DIV2K-Val, and ImageNet datasets. Furthermore, the experimental results in several datasets demonstrate that our high-frequency perceptual loss yields better SR image quality than LPIPS and VGG-based perceptual losses. Our code will be released at https://github.com/shoaib-sami/HF-Diff.
Contrastive Learning and Cycle Consistency-based Transductive Transfer Learning for Target Annotation
Jan 22, 2024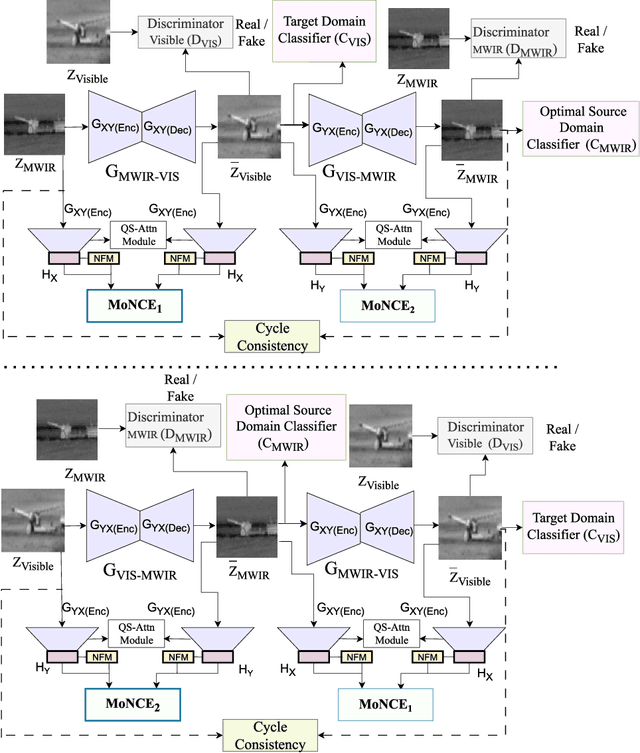
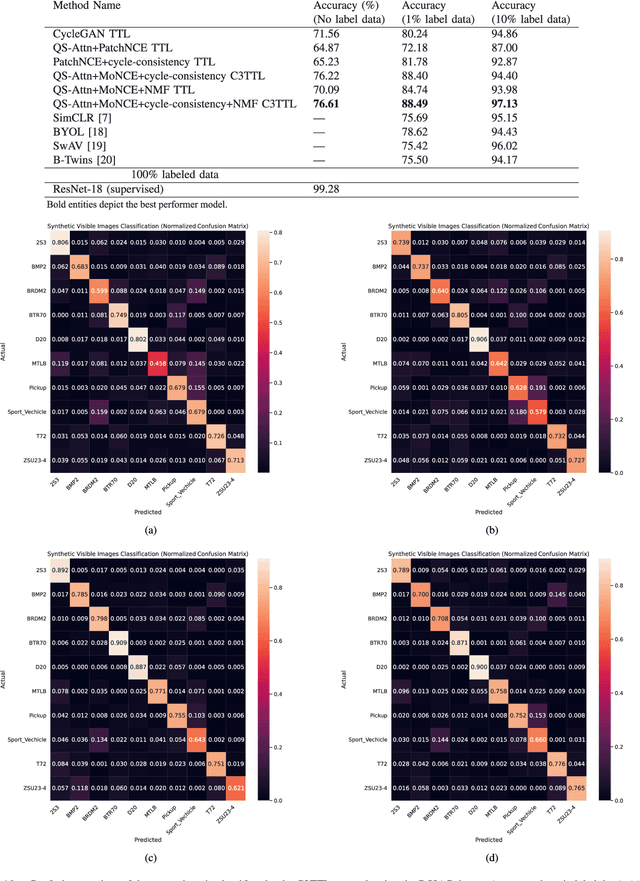
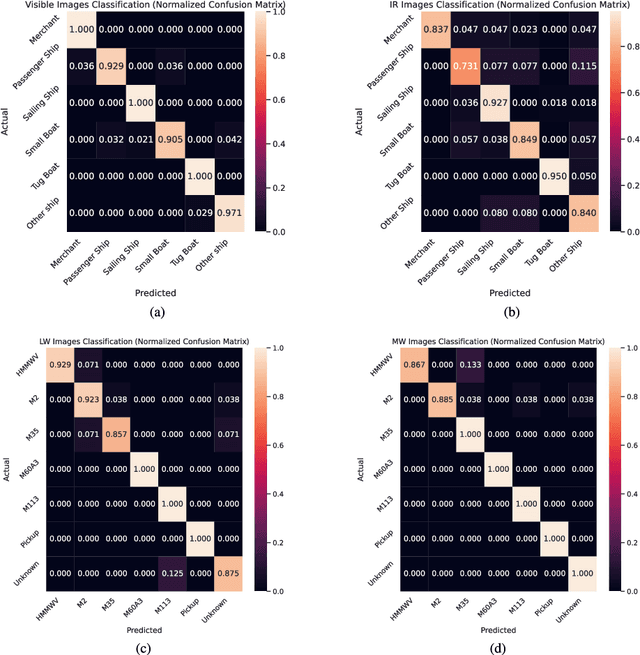
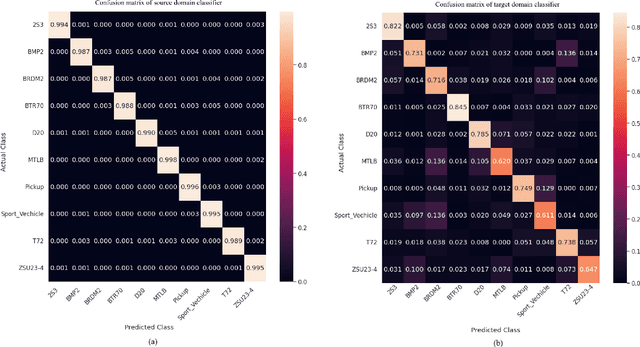
Annotating automatic target recognition (ATR) is a highly challenging task, primarily due to the unavailability of labeled data in the target domain. Hence, it is essential to construct an optimal target domain classifier by utilizing the labeled information of the source domain images. The transductive transfer learning (TTL) method that incorporates a CycleGAN-based unpaired domain translation network has been previously proposed in the literature for effective ATR annotation. Although this method demonstrates great potential for ATR, it severely suffers from lower annotation performance, higher Fr\'echet Inception Distance (FID) score, and the presence of visual artifacts in the synthetic images. To address these issues, we propose a hybrid contrastive learning base unpaired domain translation (H-CUT) network that achieves a significantly lower FID score. It incorporates both attention and entropy to emphasize the domain-specific region, a noisy feature mixup module to generate high variational synthetic negative patches, and a modulated noise contrastive estimation (MoNCE) loss to reweight all negative patches using optimal transport for better performance. Our proposed contrastive learning and cycle-consistency-based TTL (C3TTL) framework consists of two H-CUT networks and two classifiers. It simultaneously optimizes cycle-consistency, MoNCE, and identity losses. In C3TTL, two H-CUT networks have been employed through a bijection mapping to feed the reconstructed source domain images into a pretrained classifier to guide the optimal target domain classifier. Extensive experimental analysis conducted on three ATR datasets demonstrates that the proposed C3TTL method is effective in annotating civilian and military vehicles, as well as ship targets.
Text-Guided Face Recognition using Multi-Granularity Cross-Modal Contrastive Learning
Dec 14, 2023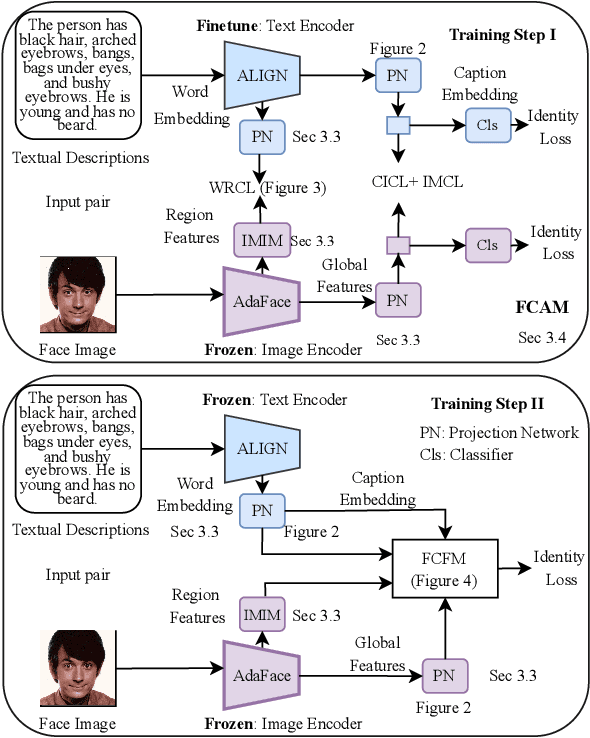
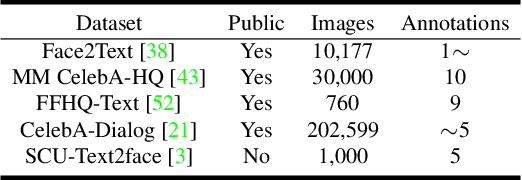
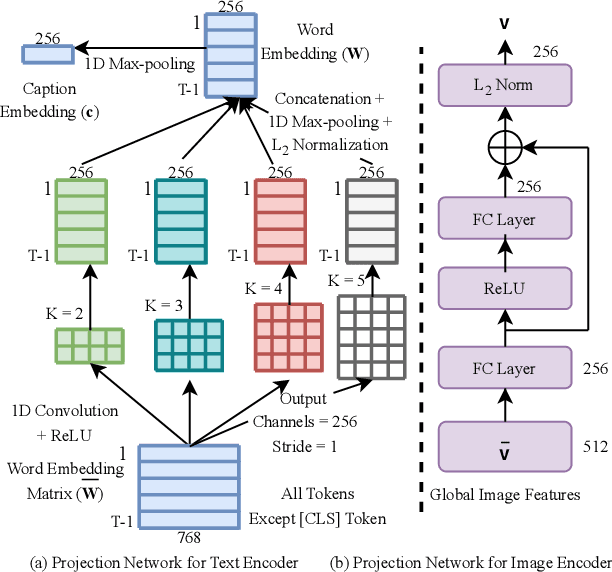
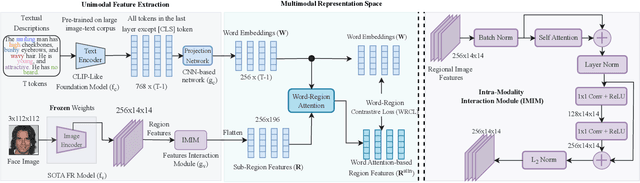
State-of-the-art face recognition (FR) models often experience a significant performance drop when dealing with facial images in surveillance scenarios where images are in low quality and often corrupted with noise. Leveraging facial characteristics, such as freckles, scars, gender, and ethnicity, becomes highly beneficial in improving FR performance in such scenarios. In this paper, we introduce text-guided face recognition (TGFR) to analyze the impact of integrating facial attributes in the form of natural language descriptions. We hypothesize that adding semantic information into the loop can significantly improve the image understanding capability of an FR algorithm compared to other soft biometrics. However, learning a discriminative joint embedding within the multimodal space poses a considerable challenge due to the semantic gap in the unaligned image-text representations, along with the complexities arising from ambiguous and incoherent textual descriptions of the face. To address these challenges, we introduce a face-caption alignment module (FCAM), which incorporates cross-modal contrastive losses across multiple granularities to maximize the mutual information between local and global features of the face-caption pair. Within FCAM, we refine both facial and textual features for learning aligned and discriminative features. We also design a face-caption fusion module (FCFM) that applies fine-grained interactions and coarse-grained associations among cross-modal features. Through extensive experiments conducted on three face-caption datasets, proposed TGFR demonstrates remarkable improvements, particularly on low-quality images, over existing FR models and outperforms other related methods and benchmarks.
Improving Face Recognition from Caption Supervision with Multi-Granular Contextual Feature Aggregation
Aug 13, 2023
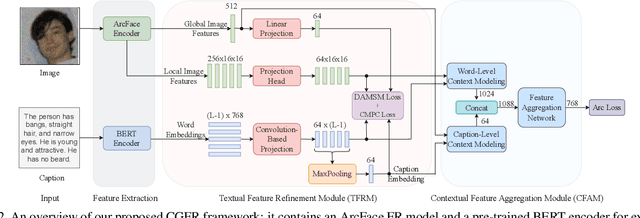

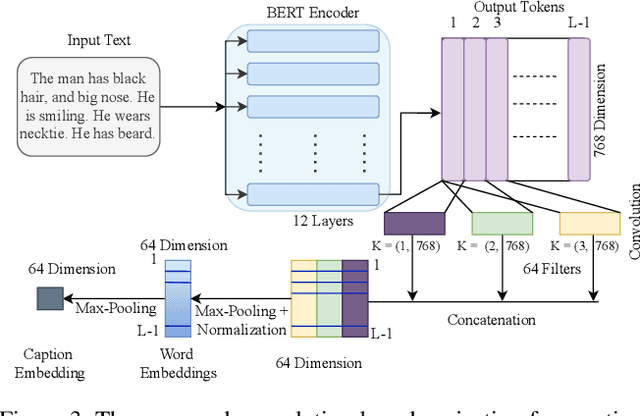
We introduce caption-guided face recognition (CGFR) as a new framework to improve the performance of commercial-off-the-shelf (COTS) face recognition (FR) systems. In contrast to combining soft biometrics (eg., facial marks, gender, and age) with face images, in this work, we use facial descriptions provided by face examiners as a piece of auxiliary information. However, due to the heterogeneity of the modalities, improving the performance by directly fusing the textual and facial features is very challenging, as both lie in different embedding spaces. In this paper, we propose a contextual feature aggregation module (CFAM) that addresses this issue by effectively exploiting the fine-grained word-region interaction and global image-caption association. Specifically, CFAM adopts a self-attention and a cross-attention scheme for improving the intra-modality and inter-modality relationship between the image and textual features, respectively. Additionally, we design a textual feature refinement module (TFRM) that refines the textual features of the pre-trained BERT encoder by updating the contextual embeddings. This module enhances the discriminative power of textual features with a cross-modal projection loss and realigns the word and caption embeddings with visual features by incorporating a visual-semantic alignment loss. We implemented the proposed CGFR framework on two face recognition models (ArcFace and AdaFace) and evaluated its performance on the Multi-Modal CelebA-HQ dataset. Our framework significantly improves the performance of ArcFace in both 1:1 verification and 1:N identification protocol.
Multi-View Bangla Sign Language Dataset and Continuous BSL Recognition
Feb 22, 2023Being able to express our thoughts, feelings, and ideas to one another is essential for human survival and development. A considerable portion of the population encounters communication obstacles in environments where hearing is the primary means of communication, leading to unfavorable effects on daily activities. An autonomous sign language recognition system that works effectively can significantly reduce this barrier. To address the issue, we proposed a large scale dataset namely Multi-View Bangla Sign Language dataset (MV- BSL) which consist of 115 glosses and 350 isolated words in 15 different categories. Furthermore, We have built a recurrent neural network (RNN) with attention based bidirectional gated recurrent units (Bi-GRU) architecture that models the temporal dynamics of the pose information of an individual communicating through sign language. Human pose information, which has proven effective in analyzing sign pattern as it ignores people's body appearance and environmental information while capturing the true movement information makes the proposed model simpler and faster with state-of-the-art accuracy.
Deep Learning based Early Detection and Grading of Diabetic Retinopathy Using Retinal Fundus Images
Dec 27, 2018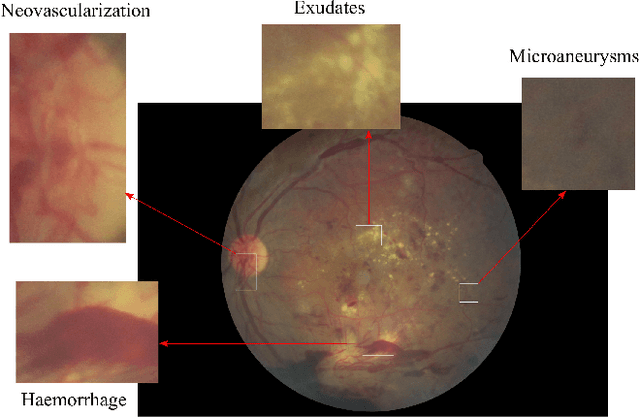
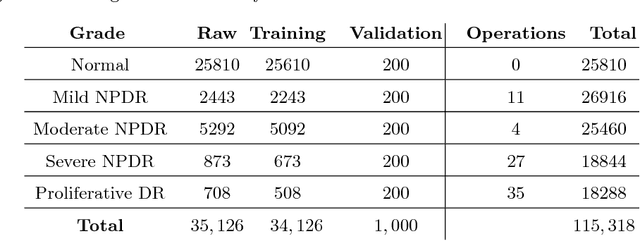
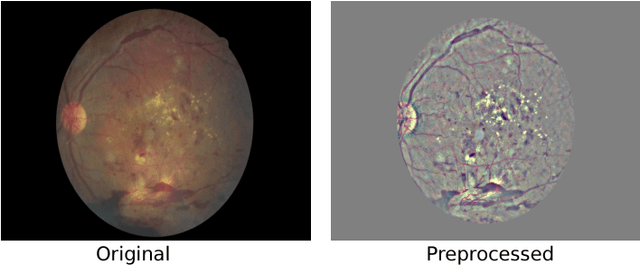
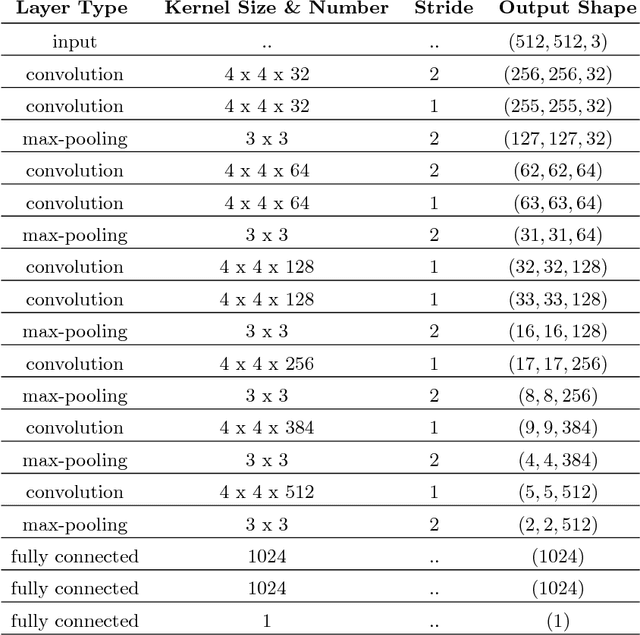
Diabetic Retinopathy (DR) is a constantly deteriorating disease, being one of the leading causes of vision impairment and blindness. Subtle distinction among different grades and existence of many significant small features make the task of recognition very challenging. In addition, the present approach of retinopathy detection is a very laborious and time-intensive task, which heavily relies on the skill of a physician. Automated detection of diabetic retinopathy is essential to tackle these problems. Early-stage detection of diabetic retinopathy is also very important for diagnosis, which can prevent blindness with proper treatment. In this paper, we developed a novel deep convolutional neural network, which performs the early-stage detection by identifying all microaneurysms (MAs), the first signs of DR, along with correctly assigning labels to retinal fundus images which are graded into five categories. We have tested our network on the largest publicly available Kaggle diabetic retinopathy dataset, and achieved 0.851 quadratic weighted kappa score and 0.844 AUC score, which achieves the state-of-the-art performance on severity grading. In the early-stage detection, we have achieved a sensitivity of 98% and specificity of above 94%, which demonstrates the effectiveness of our proposed method. Our proposed architecture is at the same time very simple and efficient with respect to computational time and space are concerned.
DEEPGONET: Multi-label Prediction of GO Annotation for Protein from Sequence Using Cascaded Convolutional and Recurrent Network
Oct 31, 2018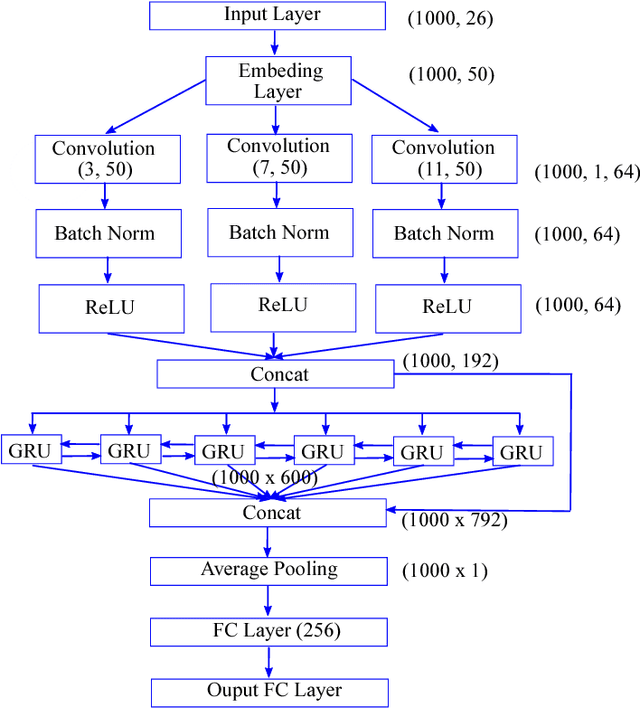
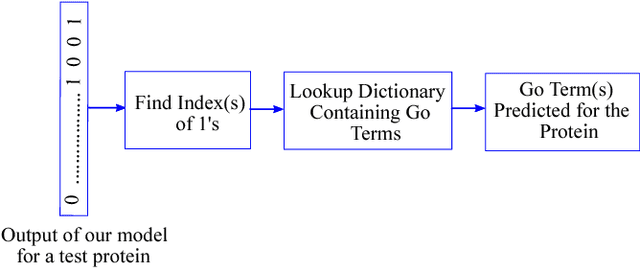
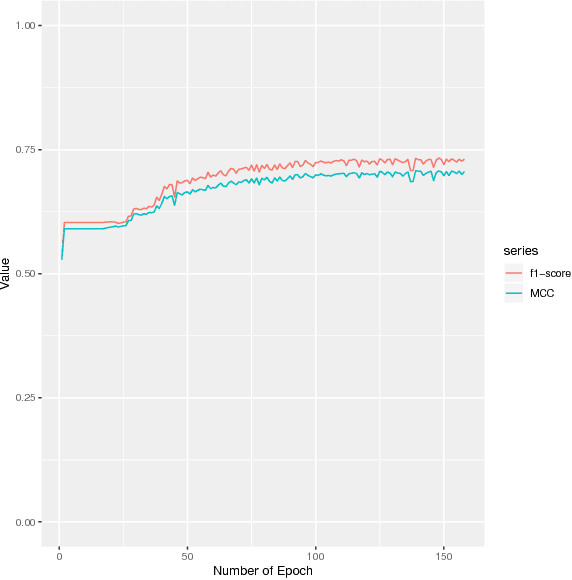
The present gap between the amount of available protein sequence due to the development of next generation sequencing technology (NGS) and slow and expensive experimental extraction of useful information like annotation of protein sequence in different functional aspects, is ever widening, which can be reduced by employing automatic function prediction (AFP) approaches. Gene Ontology (GO), comprising of more than 40, 000 classes, defines three aspects of protein function names Biological Process (BP), Cellular Component (CC), Molecular Function (MF). Multiple functions of a single protein, has made automatic function prediction a large-scale, multi-class, multi-label task. In this paper, we present DEEPGONET, a novel cascaded convolutional and recurrent neural network, to predict the top-level hierarchy of GO ontology. The network takes the primary sequence of protein as input which makes it more useful than other prevailing state-of-the-art deep learning based methods with multi-modal input, making them less applicable for proteins where only primary sequence is available. All predictions of different protein functions of our network are performed by the same architecture, a proof of better generalization as demonstrated by promising performance on a variety of organisms while trained on Homo sapiens only, which is made possible by efficient exploration of vast output space by leveraging hierarchical relationship among GO classes. The promising performance of our model makes it a potential avenue for directing experimental protein functions exploration efficiently by vastly eliminating possible routes which is done by the exploring only the suggested routes from our model. Our proposed model is also very simple and efficient in terms of computational time and space compared to other architectures in literature.