 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Face Recognition from Caption Supervision with Multi-Granular Contextual Feature Aggregation
Paper and Code
Aug 13, 2023
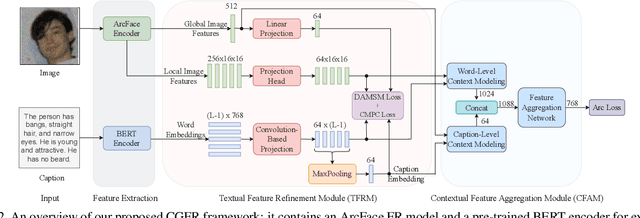

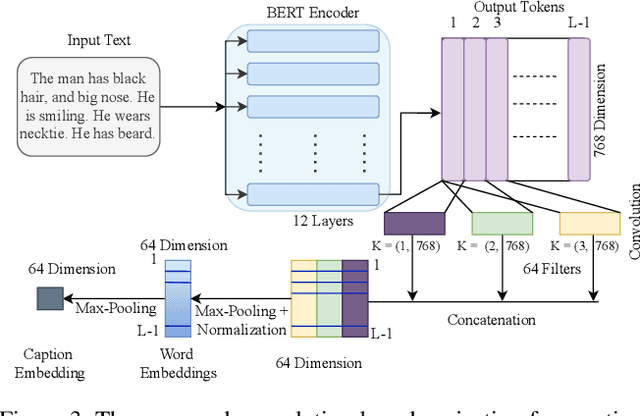
We introduce caption-guided face recognition (CGFR) as a new framework to improve the performance of commercial-off-the-shelf (COTS) face recognition (FR) systems. In contrast to combining soft biometrics (eg., facial marks, gender, and age) with face images, in this work, we use facial descriptions provided by face examiners as a piece of auxiliary information. However, due to the heterogeneity of the modalities, improving the performance by directly fusing the textual and facial features is very challenging, as both lie in different embedding spaces. In this paper, we propose a contextual feature aggregation module (CFAM) that addresses this issue by effectively exploiting the fine-grained word-region interaction and global image-caption association. Specifically, CFAM adopts a self-attention and a cross-attention scheme for improving the intra-modality and inter-modality relationship between the image and textual features, respectively. Additionally, we design a textual feature refinement module (TFRM) that refines the textual features of the pre-trained BERT encoder by updating the contextual embeddings. This module enhances the discriminative power of textual features with a cross-modal projection loss and realigns the word and caption embeddings with visual features by incorporating a visual-semantic alignment loss. We implemented the proposed CGFR framework on two face recognition models (ArcFace and AdaFace) and evaluated its performance on the Multi-Modal CelebA-HQ dataset. Our framework significantly improves the performance of ArcFace in both 1:1 verification and 1:N identification protocol.