 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuffle PatchMix Augmentation with Confidence-Margin Weighted Pseudo-Labels for Enhanced Source-Free Domain Adaptation
May 30, 2025This work investigates Source-Free Domain Adaptation (SFDA), where a model adapts to a target domain without access to source data. A new augmentation technique, Shuffle PatchMix (SPM), and a novel reweighting strategy are introduced to enhance performance. SPM shuffles and blends image patches to generate diverse and challenging augmentations, while the reweighting strategy prioritizes reliable pseudo-labels to mitigate label noise. These techniques are particularly effective on smaller datasets like PACS, where overfitting and pseudo-label noise pose greater risks. State-of-the-art results are achieved on three major benchmarks: PACS, VisDA-C, and DomainNet-126. Notably, on PACS, improvements of 7.3% (79.4% to 86.7%) and 7.2% are observed in single-target and multi-target settings, respectively, while gains of 2.8% and 0.7% are attained on DomainNet-126 and VisDA-C. This combination of advanced augmentation and robust pseudo-label reweighting establishes a new benchmark for SFDA. The code is available at: https://github.com/PrasannaPulakurthi/SPM
SHARDeg: A Benchmark for Skeletal Human Action Recognition in Degraded Scenarios
May 23, 2025Computer vision (CV) models for detection, prediction or classification tasks operate on video data-streams that are often degraded in the real world, due to deployment in real-time or on resource-constrained hardware. It is therefore critical that these models are robust to degraded data, but state of the art (SoTA) models are often insufficiently assessed with these real-world constraints in mind. This is exemplified by Skeletal Human Action Recognition (SHAR), which is critical in many CV pipelines operating in real-time and at the edge, but robustness to degraded data has previously only been shallowly and inconsistently assessed. Here we address this issue for SHAR by providing an important first data degradation benchmark on the most detailed and largest 3D open dataset, NTU-RGB+D-120, and assess the robustness of five leading SHAR models to three forms of degradation that represent real-world issues. We demonstrate the need for this benchmark by showing that the form of degradation, which has not previously been considered, has a large impact on model accuracy; at the same effective frame rate, model accuracy can vary by >40% depending on degradation type. We also identify that temporal regularity of frames in degraded SHAR data is likely a major driver of differences in model performance, and harness this to improve performance of existing models by up to >40%, through employing a simple mitigation approach based on interpolation. Finally, we highlight how our benchmark has helped identify an important degradation-resistant SHAR model based in Rough Path Theory; the LogSigRNN SHAR model outperforms the SoTA DeGCN model in five out of six cases at low frame rates by an average accuracy of 6%, despite trailing the SoTA model by 11-12% on un-degraded data at high frame rates (30 FPS).
FDCT: Frequency-Aware Decomposition and Cross-Modal Token-Alignment for Multi-Sensor Target Classification
Mar 12, 2025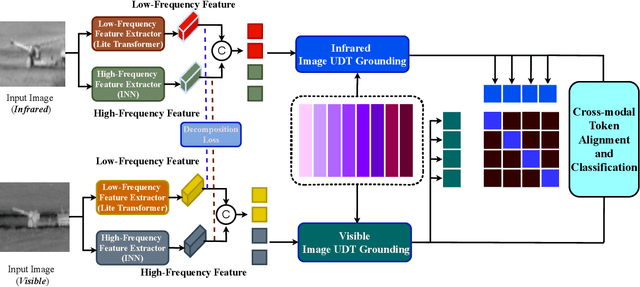
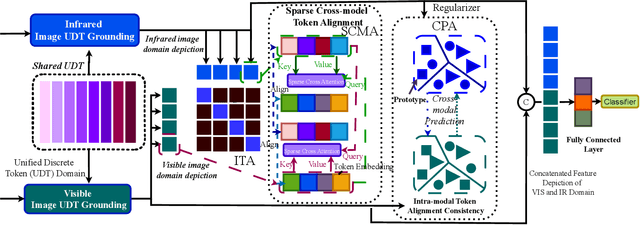
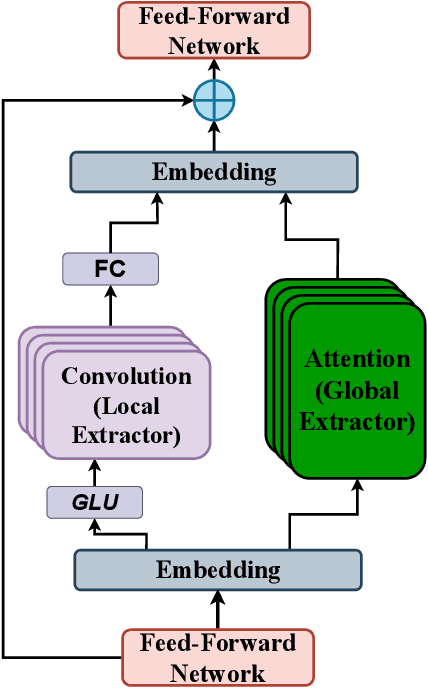
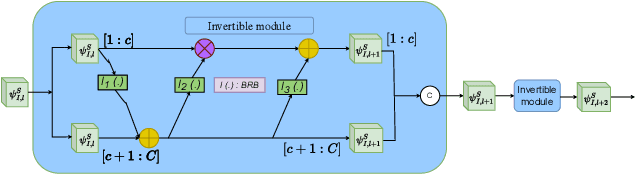
In automatic target recognition (ATR) systems, sensors may fail to capture discriminative, fine-grained detail features due to environmental conditions, noise created by CMOS chips, occlusion, parallaxes, and sensor misalignment. Therefore, multi-sensor image fusion is an effective choice to overcome these constraints. However, multi-modal image sensors are heterogeneous and have domain and granularity gaps. In addition, the multi-sensor images can be misaligned due to intricate background clutters, fluctuating illumination conditions, and uncontrolled sensor settings. In this paper, to overcome these issues, we decompose, align, and fuse multiple image sensor data for target classification. We extract the domain-specific and domain-invariant features from each sensor data. We propose to develop a shared unified discrete token (UDT) space between sensors to reduce the domain and granularity gaps. Additionally, we develop an alignment module to overcome the misalignment between multi-sensors and emphasize the discriminative representation of the UDT space. In the alignment module, we introduce sparsity constraints to provide a better cross-modal representation of the UDT space and robustness against various sensor settings. We achieve superior classification performance compared to single-modality classifiers and several state-of-the-art multi-modal fusion algorithms on four multi-sensor ATR datasets.
Improving Object Detection by Modifying Synthetic Data with Explainable AI
Dec 02, 2024



In many computer vision domains the collection of sufficient real-world data is challenging and can severely impact model performance, particularly when running inference on samples that are unseen or underrepresented in training. Synthetically generated images provide a promising solution, but it remains unclear how to design synthetic data to optimally improve model performance, for example whether to introduce more realism or more abstraction in such datasets. Here we propose a novel conceptual approach to improve the performance of computer vision models trained on synthetic images, by using robust Explainable AI (XAI) techniques to guide the modification of 3D models used to generate these images. Importantly, this framework allows both modifications that increase and decrease realism in synthetic data, which can both improve model performance. We illustrate this concept using a real-world example where data are sparse; the detection of vehicles in infrared imagery. We fine-tune an initial YOLOv8 model on the ATR DSIAC infrared dataset and synthetic images generated from 3D mesh models in the Unity gaming engine, and then use XAI saliency maps to guide modification of our Unity models. We show that synthetic data can improve detection of vehicles in orientations unseen in training by 4.6\% (to mAP50 scores of 94.6\%). We further improve performance by an additional 1.5\% (to 96.1\%) through our new XAI-guided approach, which reduces misclassifications through both increasing and decreasing the realism of different parts of the synthetic data. These proof-of-concept results pave the way for fine, XAI-controlled curation of synthetic datasets through detailed feature modifications, tailored to improve object detection performance.
Text Is MASS: Modeling as Stochastic Embedding for Text-Video Retrieval
Mar 26, 2024The increasing prevalence of video clips has sparked growing interest in text-video retrieval. Recent advances focus on establishing a joint embedding space for text and video, relying on consistent embedding representations to compute similarity. However, the text content in existing datasets is generally short and concise, making it hard to fully describe the redundant semantics of a video. Correspondingly, a single text embedding may be less expressive to capture the video embedding and empower the retrieval. In this study, we propose a new stochastic text modeling method T-MASS, i.e., text is modeled as a stochastic embedding, to enrich text embedding with a flexible and resilient semantic range, yielding a text mass. To be specific, we introduce a similarity-aware radius module to adapt the scale of the text mass upon the given text-video pairs. Plus, we design and develop a support text regularization to further control the text mass during the training. The inference pipeline is also tailored to fully exploit the text mass for accurate retrieval. Empirical evidence suggests that T-MASS not only effectively attracts relevant text-video pairs while distancing irrelevant ones, but also enables the determination of precise text embeddings for relevant pairs. Our experimental results show a substantial improvement of T-MASS over baseline (3% to 6.3% by R@1). Also, T-MASS achieves state-of-the-art performance on five benchmark datasets, including MSRVTT, LSMDC, DiDeMo, VATEX, and Charades.
Image Translation as Diffusion Visual Programmers
Jan 30, 2024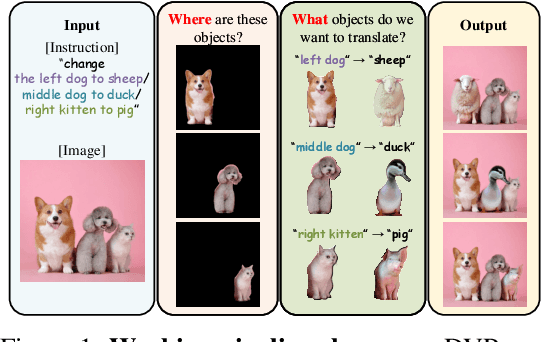



We introduce the novel Diffusion Visual Programmer (DVP), a neuro-symbolic image translation framework. Our proposed DVP seamlessly embeds a condition-flexible diffusion model within the GPT architecture, orchestrating a coherent sequence of visual programs (i.e., computer vision models) for various pro-symbolic steps, which span RoI identification, style transfer, and position manipulation, facilitating transparent and controllable image translation processes. Extensive experiments demonstrate DVP's remarkable performance, surpassing concurrent arts. This success can be attributed to several key features of DVP: First, DVP achieves condition-flexible translation via instance normalization, enabling the model to eliminate sensitivity caused by the manual guidance and optimally focus on textual descriptions for high-quality content generation. Second, the framework enhances in-context reasoning by deciphering intricate high-dimensional concepts in feature spaces into more accessible low-dimensional symbols (e.g., [Prompt], [RoI object]), allowing for localized, context-free editing while maintaining overall coherence. Last but not least, DVP improves systemic controllability and explainability by offering explicit symbolic representations at each programming stage, empowering users to intuitively interpret and modify results. Our research marks a substantial step towards harmonizing artificial image translation processes with cognitive intelligence, promising broader applications.
Contrastive Learning and Cycle Consistency-based Transductive Transfer Learning for Target Annotation
Jan 22, 2024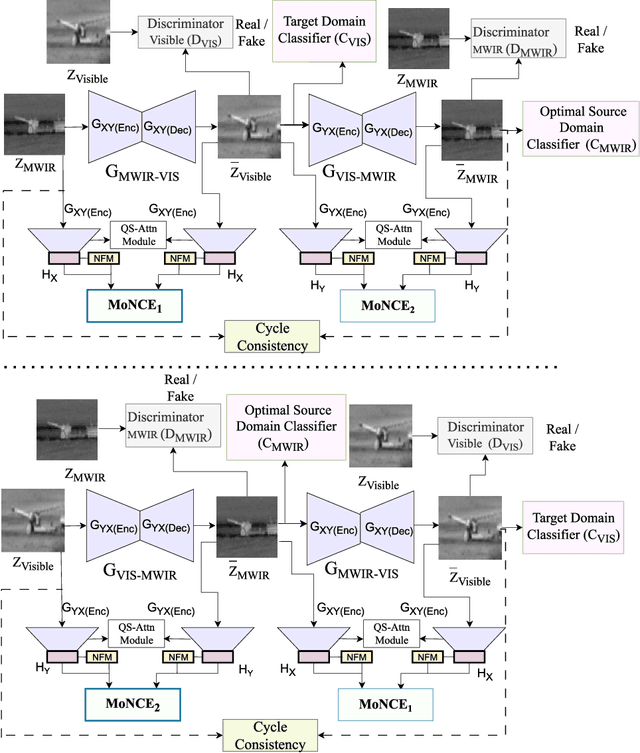
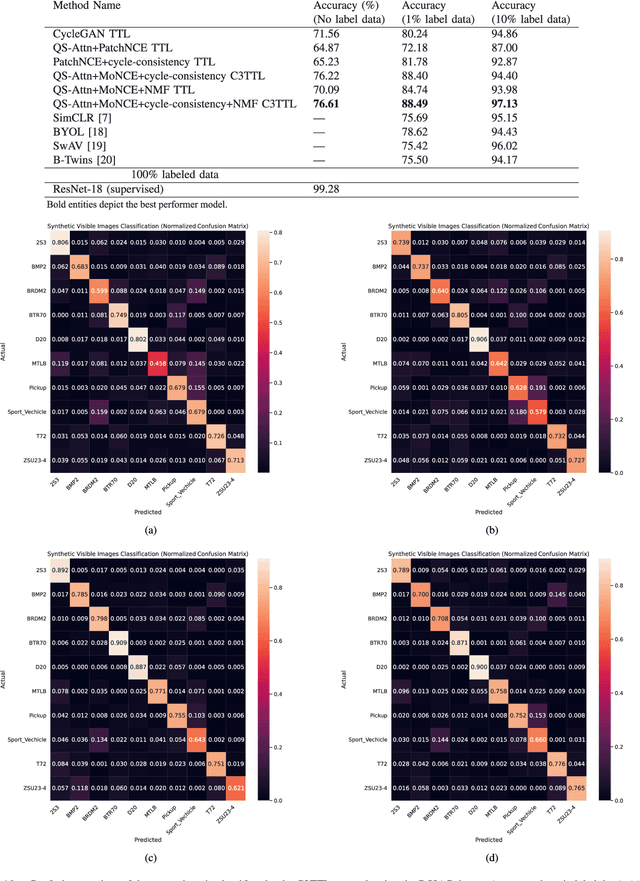
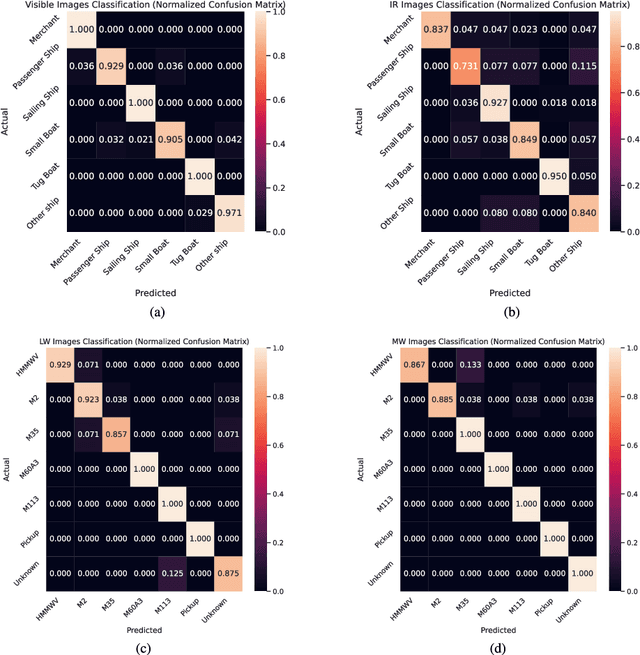
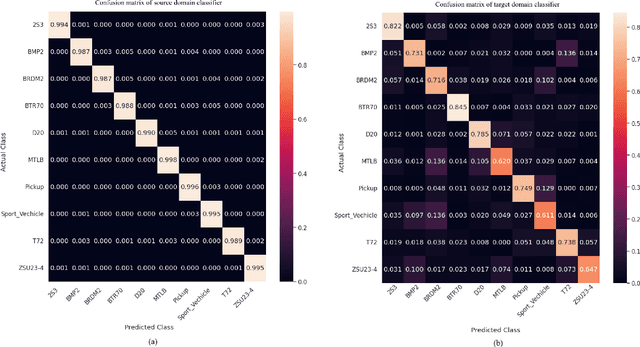
Annotating automatic target recognition (ATR) is a highly challenging task, primarily due to the unavailability of labeled data in the target domain. Hence, it is essential to construct an optimal target domain classifier by utilizing the labeled information of the source domain images. The transductive transfer learning (TTL) method that incorporates a CycleGAN-based unpaired domain translation network has been previously proposed in the literature for effective ATR annotation. Although this method demonstrates great potential for ATR, it severely suffers from lower annotation performance, higher Fr\'echet Inception Distance (FID) score, and the presence of visual artifacts in the synthetic images. To address these issues, we propose a hybrid contrastive learning base unpaired domain translation (H-CUT) network that achieves a significantly lower FID score. It incorporates both attention and entropy to emphasize the domain-specific region, a noisy feature mixup module to generate high variational synthetic negative patches, and a modulated noise contrastive estimation (MoNCE) loss to reweight all negative patches using optimal transport for better performance. Our proposed contrastive learning and cycle-consistency-based TTL (C3TTL) framework consists of two H-CUT networks and two classifiers. It simultaneously optimizes cycle-consistency, MoNCE, and identity losses. In C3TTL, two H-CUT networks have been employed through a bijection mapping to feed the reconstructed source domain images into a pretrained classifier to guide the optimal target domain classifier. Extensive experimental analysis conducted on three ATR datasets demonstrates that the proposed C3TTL method is effective in annotating civilian and military vehicles, as well as ship targets.
TokenMotion: Motion-Guided Vision Transformer for Video Camouflaged Object Detection Via Learnable Token Selection
Nov 05, 2023



The area of Video Camouflaged Object Detection (VCOD) presents unique challenges in the field of computer vision due to texture similarities between target objects and their surroundings, as well as irregular motion patterns caused by both objects and camera movement. In this paper, we introduce TokenMotion (TMNet), which employs a transformer-based model to enhance VCOD by extracting motion-guided features using a learnable token selection. Evaluated on the challenging MoCA-Mask dataset, TMNet achieves state-of-the-art performance in VCOD. It outperforms the existing state-of-the-art method by a 12.8% improvement in weighted F-measure, an 8.4% enhancement in S-measure, and a 10.7% boost in mean IoU. The results demonstrate the benefits of utilizing motion-guided features via learnable token selection within a transformer-based framework to tackle the intricate task of VCOD.
Deep Transductive Transfer Learning for Automatic Target Recognition
May 23, 2023One of the major obstacles in designing an automatic target recognition (ATR) algorithm, is that there are often labeled images in one domain (i.e., infrared source domain) but no annotated images in the other target domains (i.e., visible, SAR, LIDAR). Therefore, automatically annotating these images is essential to build a robust classifier in the target domain based on the labeled images of the source domain. Transductive transfer learning is an effective way to adapt a network to a new target domain by utilizing a pretrained ATR network in the source domain. We propose an unpaired transductive transfer learning framework where a CycleGAN model and a well-trained ATR classifier in the source domain are used to construct an ATR classifier in the target domain without having any labeled data in the target domain. We employ a CycleGAN model to transfer the mid-wave infrared (MWIR) images to visible (VIS) domain images (or visible to MWIR domain). To train the transductive CycleGAN, we optimize a cost function consisting of the adversarial, identity, cycle-consistency, and categorical cross-entropy loss for both the source and target classifiers. In this paper, we perform a detailed experimental analysis on the challenging DSIAC ATR dataset. The dataset consists of ten classes of vehicles at different poses and distances ranging from 1-5 kilometers on both the MWIR and VIS domains. In our experiment, we assume that the images in the VIS domain are the unlabeled target dataset. We first detect and crop the vehicles from the raw images and then project them into a common distance of 2 kilometers. Our proposed transductive CycleGAN achieves 71.56% accuracy in classifying the visible domain vehicles in the DSIAC ATR dataset.
* 10 pages, 5 figures
Enhanced Low-resolution LiDAR-Camera Calibration Via Depth Interpolation and Supervised Contrastive Learning
Nov 08, 2022



Motivated by the increasing application of low-resolution LiDAR recently, we target the problem of low-resolution LiDAR-camera calibration in this work. The main challenges are two-fold: sparsity and noise in point clouds. To address the problem, we propose to apply depth interpolation to increase the point density and supervised contrastive learning to learn noise-resistant features. The experiments on RELLIS-3D demonstrate that our approach achieves an average mean absolute rotation/translation errors of 0.15cm/0.33\textdegree on 32-channel LiDAR point cloud data, which significantly outperforms all reference methods.