 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenMotion: Motion-Guided Vision Transformer for Video Camouflaged Object Detection Via Learnable Token Selection
Nov 05, 2023



The area of Video Camouflaged Object Detection (VCOD) presents unique challenges in the field of computer vision due to texture similarities between target objects and their surroundings, as well as irregular motion patterns caused by both objects and camera movement. In this paper, we introduce TokenMotion (TMNet), which employs a transformer-based model to enhance VCOD by extracting motion-guided features using a learnable token selection. Evaluated on the challenging MoCA-Mask dataset, TMNet achieves state-of-the-art performance in VCOD. It outperforms the existing state-of-the-art method by a 12.8% improvement in weighted F-measure, an 8.4% enhancement in S-measure, and a 10.7% boost in mean IoU. The results demonstrate the benefits of utilizing motion-guided features via learnable token selection within a transformer-based framework to tackle the intricate task of VCOD.
TransUPR: A Transformer-based Uncertain Point Refiner for LiDAR Point Cloud Semantic Segmentation
Feb 20, 2023



In this work, we target the problem of uncertain points refinement for image-based LiDAR point cloud semantic segmentation (LiDAR PCSS). This problem mainly results from the boundary-blurring problem of convolution neural networks (CNNs) and quantitation loss of spherical projection, which are often hard to avoid for common image-based LiDAR PCSS approaches. We propose a plug-and-play transformer-based uncertain point refiner (TransUPR) to address the problem. Through local feature aggregation, uncertain point localization, and self-attention-based transformer design, TransUPR, integrated into an existing range image-based LiDAR PCSS approach (e.g., CENet), achieves the state-of-the-art performance (68.2% mIoU) on Semantic-KITTI benchmark, which provides a performance improvement of 0.6% on the mIoU.
Frequency-domain Learning for Volumetric-based 3D Data Perception
Feb 20, 2023



Frequency-domain learning draws attention due to its superior tradeoff between inference accuracy and input data size. Frequency-domain learning in 2D computer vision tasks has shown that 2D convolutional neural networks (CNN) have a stationary spectral bias towards low-frequency channels so that high-frequency channels can be pruned with no or little accuracy degradation. However, frequency-domain learning has not been studied in the context of 3D CNNs with 3D volumetric data. In this paper, we study frequency-domain learning for volumetric-based 3D data perception to reveal the spectral bias and the accuracy-input-data-size tradeoff of 3D CNNs. Our study finds that 3D CNNs are sensitive to a limited number of critical frequency channels, especially low-frequency channels. Experiment results show that frequency-domain learning can significantly reduce the size of volumetric-based 3D inputs (based on spectral bias) while achieving comparable accuracy with conventional spatial-domain learning approaches. Specifically, frequency-domain learning is able to reduce the input data size by 98% in 3D shape classification while limiting the average accuracy drop within 2%, and by 98% in the 3D point cloud semantic segmentation with a 1.48% mean-class accuracy improvement while limiting the mean-class IoU loss within 1.55%. Moreover, by learning from higher-resolution 3D data (i.e., 2x of the original image in the spatial domain), frequency-domain learning improves the mean-class accuracy and mean-class IoU by 3.04% and 0.63%, respectively, while achieving an 87.5% input data size reduction in 3D point cloud semantic segmentation.
Enhanced Low-resolution LiDAR-Camera Calibration Via Depth Interpolation and Supervised Contrastive Learning
Nov 08, 2022



Motivated by the increasing application of low-resolution LiDAR recently, we target the problem of low-resolution LiDAR-camera calibration in this work. The main challenges are two-fold: sparsity and noise in point clouds. To address the problem, we propose to apply depth interpolation to increase the point density and supervised contrastive learning to learn noise-resistant features. The experiments on RELLIS-3D demonstrate that our approach achieves an average mean absolute rotation/translation errors of 0.15cm/0.33\textdegree on 32-channel LiDAR point cloud data, which significantly outperforms all reference methods.
Automatic Error Detection in Integrated Circuits Image Segmentation: A Data-driven Approach
Nov 08, 2022
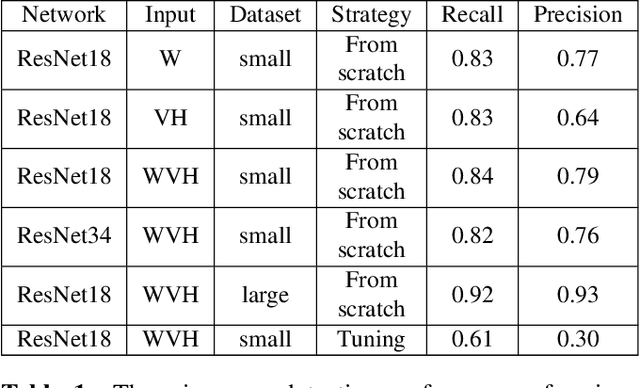
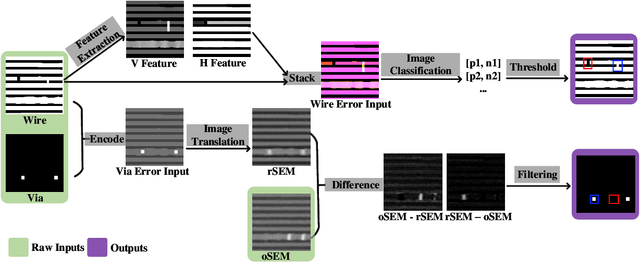

Due to the complicated nanoscale structures of current integrated circuits(IC) builds and low error tolerance of IC image segmentation tasks, most existing automated IC image segmentation approaches require human experts for visual inspection to ensure correctness, which is one of the major bottlenecks in large-scale industrial applications. In this paper, we present the first data-driven automatic error detection approach targeting two types of IC segmentation errors: wire errors and via errors. On an IC image dataset collected from real industry, we demonstrate that, by adapting existing CNN-based approaches of image classification and image translation with additional pre-processing and post-processing techniques, we are able to achieve recall/precision of 0.92/0.93 in wire error detection and 0.96/0.90 in via error detection, respectively.
OpenICS: Open Image Compressive Sensing Toolbox and Benchmark
Mar 04, 2021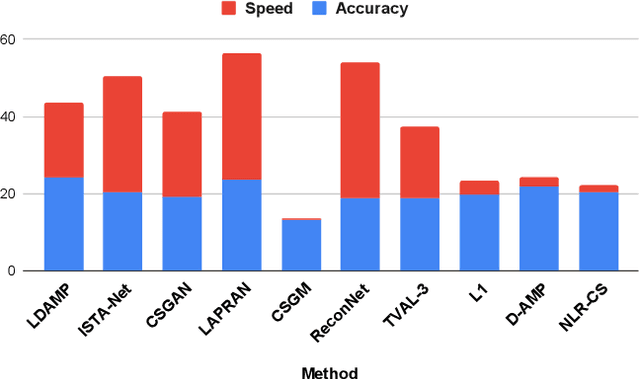


We present OpenICS, an image compressive sensing toolbox that includes multiple image compressive sensing and reconstruction algorithms proposed in the past decade. Due to the lack of standardization in the implementation and evaluation of the proposed algorithms, the application of image compressive sensing in the real-world is limited. We believe this toolbox is the first framework that provides a unified and standardized implementation of multiple image compressive sensing algorithms. In addition, we also conduct a benchmarking study on the methods included in this framework from two aspects: reconstruction accuracy and reconstruction efficiency. We wish this toolbox and benchmark can serve the growing research community of compressive sensing and the industry applying image compressive sensing to new problems as well as developing new methods more efficiently. Code and models are available at https://github.com/PSCLab-ASU/OpenICS. The project is still under maintenance, and we will keep this document updated.
Systolic-CNN: An OpenCL-defined Scalable Run-time-flexible FPGA Accelerator Architecture for Accelerating Convolutional Neural Network Inference in Cloud/Edge Computing
Dec 06, 2020This paper presents Systolic-CNN, an OpenCL-defined scalable, run-time-flexible FPGA accelerator architecture, optimized for accelerating the inference of various convolutional neural networks (CNNs) in multi-tenancy cloud/edge computing. The existing OpenCL-defined FPGA accelerators for CNN inference are insufficient due to limited flexibility for supporting multiple CNN models at run time and poor scalability resulting in underutilized FPGA resources and limited computational parallelism. Systolic-CNN adopts a highly pipelined and paralleled 1-D systolic array architecture, which efficiently explores both spatial and temporal parallelism for accelerating CNN inference on FPGAs. Systolic-CNN is highly scalable and parameterized, which can be easily adapted by users to achieve up to 100% utilization of the coarse-grained computation resources (i.e., DSP blocks) for a given FPGA. Systolic-CNN is also run-time-flexible in the context of multi-tenancy cloud/edge computing, which can be time-shared to accelerate a variety of CNN models at run time without the need of recompiling the FPGA kernel hardware nor reprogramming the FPGA. The experiment results based on an Intel Arria/Stratix 10 GX FPGA Development board show that the optimized single-precision implementation of Systolic-CNN can achieve an average inference latency of 7ms/2ms, 84ms/33ms, 202ms/73ms, 1615ms/873ms, and 900ms/498ms per image for accelerating AlexNet, ResNet-50, ResNet-152, RetinaNet, and Light-weight RetinaNet, respectively. Codes are available at https://github.com/PSCLab-ASU/Systolic-CNN.
HALO 1.0: A Hardware-agnostic Accelerator Orchestration Framework for Enabling Hardware-agnostic Programming with True Performance Portability for Heterogeneous HPC
Nov 22, 2020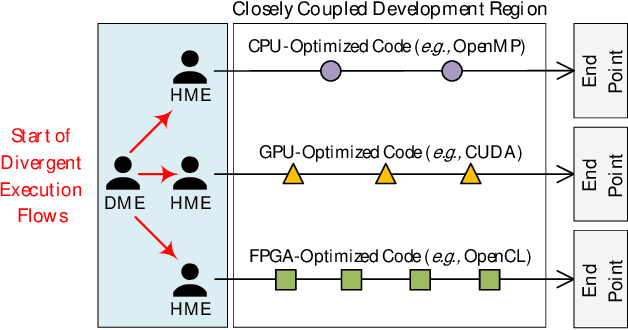
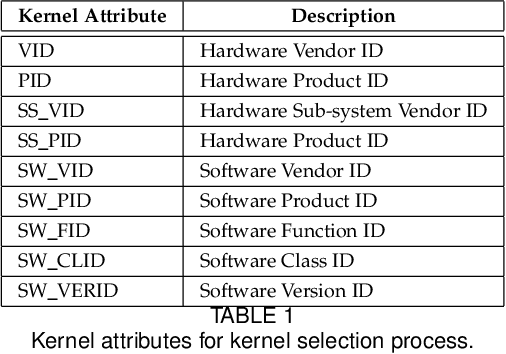
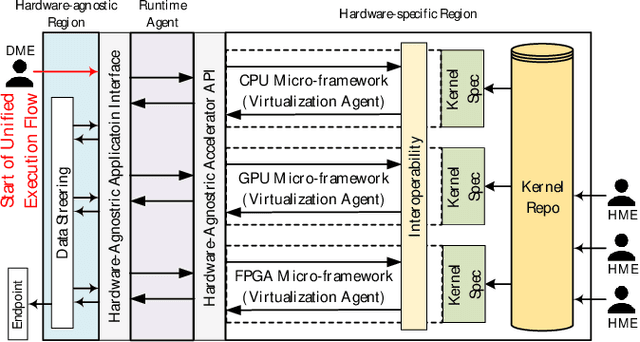
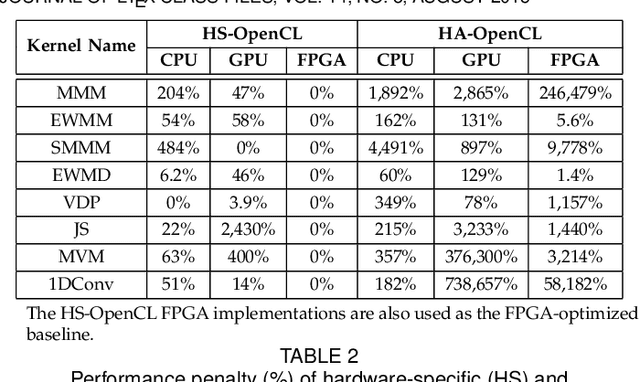
Hardware-agnostic programming with high performance portability will be the bedrock for realizing the ubiquitous adoption of emerging accelerator technologies in future heterogeneous high-performance computing (HPC) systems, which is the key to achieving the next level of HPC performance on an expanding accelerator landscape. In this paper, we present HALO 1.0, an open-ended extensible multi-agent software framework, that implements a set of proposed hardware-agnostic accelerator orchestration (HALO) principles and a novel compute-centric message passing interface (C^2MPI) specification for enabling the portable and performance-optimized execution of hardware-agnostic application codes across heterogeneous accelerator resources. The experiment results of evaluating eight widely used HPC subroutines based on Intel Xeon E5-2620 v4 CPUs, Intel Arria 10 GX FPGAs, and NVIDIA GeForce RTX 2080 Ti GPUs show that HALO 1.0 allows the same hardware-agnostic application codes of the HPC kernels, without any change, to run across all the computing devices with a consistently maximum performance portability score of 1.0, which is 2x-861,883x higher than the OpenCL-based solution that suffers from an unstably low performance portability score.
MoNet3D: Towards Accurate Monocular 3D Object Localization in Real Time
Jun 29, 2020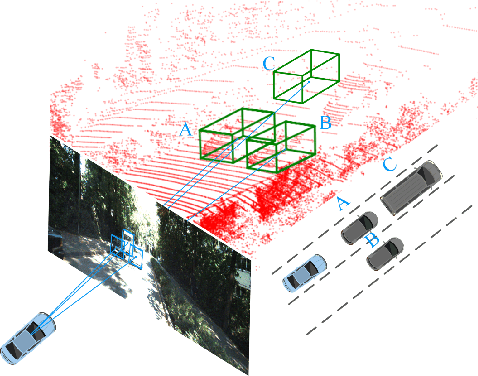
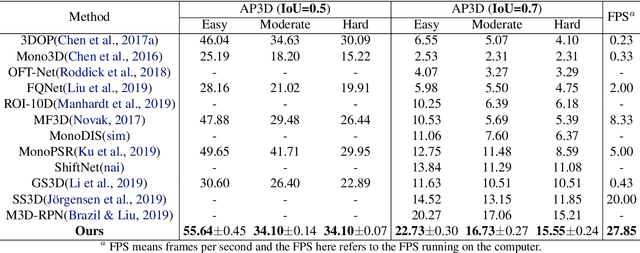
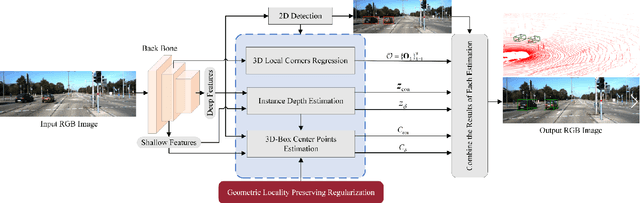
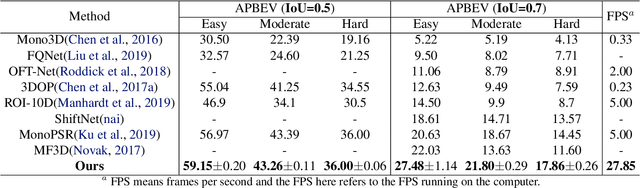
Monocular multi-object detection and localization in 3D space has been proven to be a challenging task. The MoNet3D algorithm is a novel and effective framework that can predict the 3D position of each object in a monocular image and draw a 3D bounding box for each object. The MoNet3D method incorporates prior knowledge of the spatial geometric correlation of neighbouring objects into the deep neural network training process to improve the accuracy of 3D object localization. Experiments on the KITTI dataset show that the accuracy for predicting the depth and horizontal coordinates of objects in 3D space can reach 96.25\% and 94.74\%, respectively. Moreover, the method can realize the real-time image processing at 27.85 FPS, showing promising potential for embedded advanced driving-assistance system applications. Our code is publicly available at https://github.com/CQUlearningsystemgroup/YicongPeng.
Learning in the Frequency Domain
Mar 12, 2020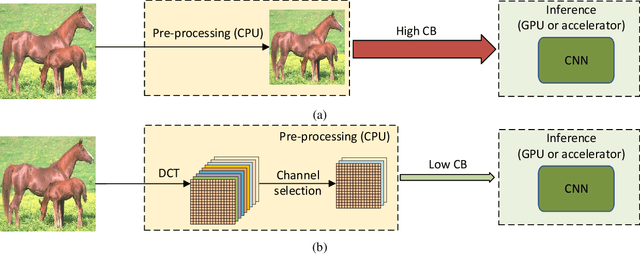
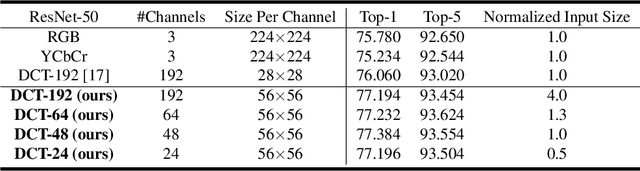
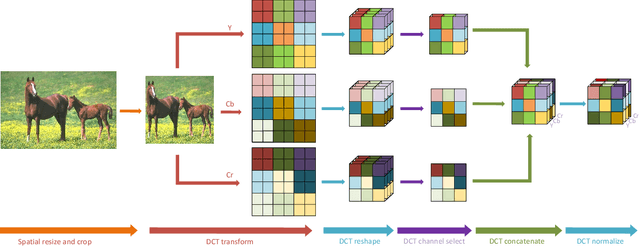
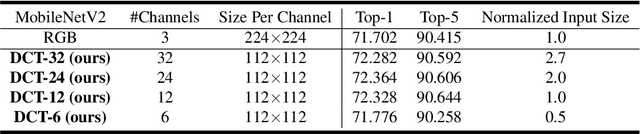
Deep neural networks have achieved remarkable success in computer vision tasks. Existing neural networks mainly operate in the spatial domain with fixed input sizes. For practical applications, images are usually large and have to be downsampled to the predetermined input size of neural networks. Even though the downsampling operations reduce computation and the required communication bandwidth, it removes both redundant and salient information obliviously, which results in accuracy degradation. Inspired by digital signal processing theories, we analyze the spectral bias from the frequency perspective and propose a learning-based frequency selection method to identify the trivial frequency components which can be removed without accuracy loss. The proposed method of learning in the frequency domain leverages identical structures of the well-known neural networks, such as ResNet-50, MobileNetV2, and Mask R-CNN, while accepting the frequency-domain information as the input. Experiment results show that learning in the frequency domain with static channel selection can achieve higher accuracy than the conventional spatial downsampling approach and meanwhile further reduce the input data size. Specifically for ImageNet classification with the same input size, the proposed method achieves 1.41% and 0.66% top-1 accuracy improvements on ResNet-50 and MobileNetV2, respectively. Even with half input size, the proposed method still improves the top-1 accuracy on ResNet-50 by 1%. In addition, we observe a 0.8% average precision improvement on Mask R-CNN for instance segmentation on the COCO dataset.