 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Annotation Barriers: Generalized Video Quality Assessment via Ranking-based Self-Supervision
May 07, 2025Video quality assessment (VQA) is essential for quantifying perceptual quality in various video processing workflows, spanning from camera capture systems to over-the-top streaming platforms. While recent supervised VQA models have made substantial progress, the reliance on manually annotated datasets -- a process that is labor-intensive, costly, and difficult to scale up -- has hindered further optimization of their generalization to unseen video content and distortions. To bridge this gap, we introduce a self-supervised learning framework for VQA to learn quality assessment capabilities from large-scale, unlabeled web videos. Our approach leverages a \textbf{learning-to-rank} paradigm to train a large multimodal model (LMM) on video pairs automatically labeled via two manners, including quality pseudo-labeling by existing VQA models and relative quality ranking based on synthetic distortion simulations. Furthermore, we introduce a novel \textbf{iterative self-improvement training strategy}, where the trained model acts an improved annotator to iteratively refine the annotation quality of training data. By training on a dataset $10\times$ larger than the existing VQA benchmarks, our model: (1) achieves zero-shot performance on in-domain VQA benchmarks that matches or surpasses supervised models; (2) demonstrates superior out-of-distribution (OOD) generalization across diverse video content and distortions; and (3) sets a new state-of-the-art when fine-tuned on human-labeled datasets. Extensive experimental results validate the effectiveness of our self-supervised approach in training generalized VQA models. The datasets and code will be publicly released to facilitate future research.
Quality-guided Skin Tone Enhancement for Portrait Photography
Jun 22, 2024In recent years, learning-based color and tone enhancement methods for photos have become increasingly popular. However, most learning-based image enhancement methods just learn a mapping from one distribution to another based on one dataset, lacking the ability to adjust images continuously and controllably. It is important to enable the learning-based enhancement models to adjust an image continuously, since in many cases we may want to get a slighter or stronger enhancement effect rather than one fixed adjusted result. In this paper, we propose a quality-guided image enhancement paradigm that enables image enhancement models to learn the distribution of images with various quality ratings. By learning this distribution, image enhancement models can associate image features with their corresponding perceptual qualities, which can be used to adjust images continuously according to different quality scores. To validate the effectiveness of our proposed method, a subjective quality assessment experiment is first conducted, focusing on skin tone adjustment in portrait photography. Guided by the subjective quality ratings obtained from this experiment, our method can adjust the skin tone corresponding to different quality requirements. Furthermore, an experiment conducted on 10 natural raw images corroborates the effectiveness of our model in situations with fewer subjects and fewer shots, and also demonstrates its general applicability to natural images. Our project page is https://github.com/IntMeGroup/quality-guided-enhancement .
Resolution-Agnostic Neural Compression for High-Fidelity Portrait Video Conferencing via Implicit Radiance Fields
Feb 26, 2024Video conferencing has caught much more attention recently. High fidelity and low bandwidth are two major objectives of video compression for video conferencing applications. Most pioneering methods rely on classic video compression codec without high-level feature embedding and thus can not reach the extremely low bandwidth. Recent works instead employ model-based neural compression to acquire ultra-low bitrates using sparse representations of each frame such as facial landmark information, while these approaches can not maintain high fidelity due to 2D image-based warping. In this paper, we propose a novel low bandwidth neural compression approach for high-fidelity portrait video conferencing using implicit radiance fields to achieve both major objectives. We leverage dynamic neural radiance fields to reconstruct high-fidelity talking head with expression features, which are represented as frame substitution for transmission. The overall system employs deep model to encode expression features at the sender and reconstruct portrait at the receiver with volume rendering as decoder for ultra-low bandwidth. In particular, with the characteristic of neural radiance fields based model, our compression approach is resolution-agnostic, which means that the low bandwidth achieved by our approach is independent of video resolution, while maintaining fidelity for higher resolution reconstruction. Experimental results demonstrate that our novel framework can (1) construct ultra-low bandwidth video conferencing, (2) maintain high fidelity portrait and (3) have better performance on high-resolution video compression than previous works.
AttentionLut: Attention Fusion-based Canonical Polyadic LUT for Real-time Image Enhancement
Jan 03, 2024Recently, many algorithms have employed image-adaptive lookup tables (LUTs) to achieve real-time image enhancement. Nonetheless, a prevailing trend among existing methods has been the employment of linear combinations of basic LUTs to formulate image-adaptive LUTs, which limits the generalization ability of these methods. To address this limitation, we propose a novel framework named AttentionLut for real-time image enhancement, which utilizes the attention mechanism to generate image-adaptive LUTs. Our proposed framework consists of three lightweight modules. We begin by employing the global image context feature module to extract image-adaptive features. Subsequently, the attention fusion module integrates the image feature with the priori attention feature obtained during training to generate image-adaptive canonical polyadic tensors. Finally, the canonical polyadic reconstruction module is deployed to reconstruct image-adaptive residual 3DLUT, which is subsequently utilized for enhancing input images. Experiments on the benchmark MIT-Adobe FiveK dataset demonstrate that the proposed method achieves better enhancement performance quantitatively and qualitatively than the state-of-the-art methods.
RAWIW: RAW Image Watermarking Robust to ISP Pipeline
Jul 28, 2023Invisible image watermarking is essential for image copyright protection. Compared to RGB images, RAW format images use a higher dynamic range to capture the radiometric characteristics of the camera sensor, providing greater flexibility in post-processing and retouching. Similar to the master recording in the music industry, RAW images are considered the original format for distribution and image production, thus requiring copyright protection. Existing watermarking methods typically target RGB images, leaving a gap for RAW images. To address this issue, we propose the first deep learning-based RAW Image Watermarking (RAWIW) framework for copyright protection. Unlike RGB image watermarking, our method achieves cross-domain copyright protection. We directly embed copyright information into RAW images, which can be later extracted from the corresponding RGB images generated by different post-processing methods. To achieve end-to-end training of the framework, we integrate a neural network that simulates the ISP pipeline to handle the RAW-to-RGB conversion process. To further validate the generalization of our framework to traditional ISP pipelines and its robustness to transmission distortion, we adopt a distortion network. This network simulates various types of noises introduced during the traditional ISP pipeline and transmission. Furthermore, we employ a three-stage training strategy to strike a balance between robustness and concealment of watermarking. Our extensive experiments demonstrate that RAWIW successfully achieves cross-domain copyright protection for RAW images while maintaining their visual quality and robustness to ISP pipeline distortions.
MoNet3D: Towards Accurate Monocular 3D Object Localization in Real Time
Jun 29, 2020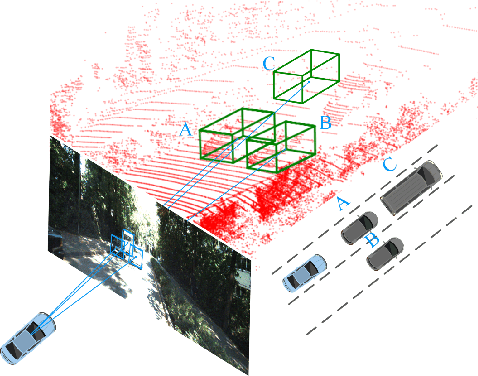
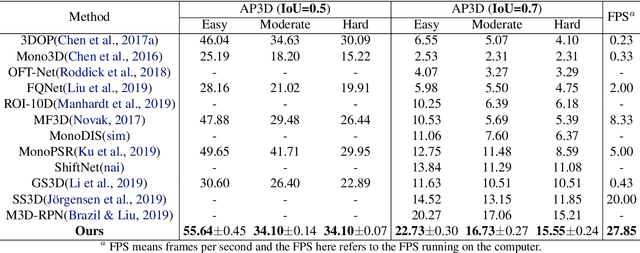
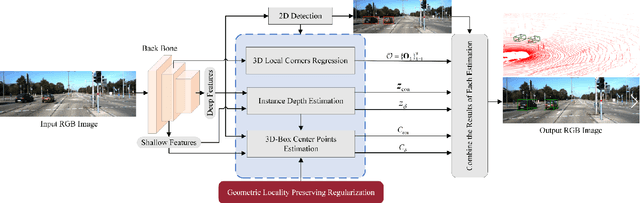
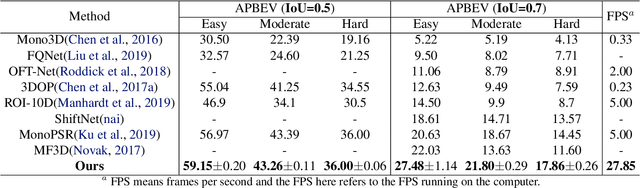
Monocular multi-object detection and localization in 3D space has been proven to be a challenging task. The MoNet3D algorithm is a novel and effective framework that can predict the 3D position of each object in a monocular image and draw a 3D bounding box for each object. The MoNet3D method incorporates prior knowledge of the spatial geometric correlation of neighbouring objects into the deep neural network training process to improve the accuracy of 3D object localization. Experiments on the KITTI dataset show that the accuracy for predicting the depth and horizontal coordinates of objects in 3D space can reach 96.25\% and 94.74\%, respectively. Moreover, the method can realize the real-time image processing at 27.85 FPS, showing promising potential for embedded advanced driving-assistance system applications. Our code is publicly available at https://github.com/CQUlearningsystemgroup/YicongPeng.