 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualiRAG: Retrieval-Augmented Generation for Visual Quality Understanding
Jan 26, 2026Visual quality assessment (VQA) is increasingly shifting from scalar score prediction toward interpretable quality understanding -- a paradigm that demands \textit{fine-grained spatiotemporal perception} and \textit{auxiliary contextual information}. Current approaches rely on supervised fine-tuning or reinforcement learning on curated instruction datasets, which involve labor-intensive annotation and are prone to dataset-specific biases. To address these challenges, we propose \textbf{QualiRAG}, a \textit{training-free} \textbf{R}etrieval-\textbf{A}ugmented \textbf{G}eneration \textbf{(RAG)} framework that systematically leverages the latent perceptual knowledge of large multimodal models (LMMs) for visual quality perception. Unlike conventional RAG that retrieves from static corpora, QualiRAG dynamically generates auxiliary knowledge by decomposing questions into structured requests and constructing four complementary knowledge sources: \textit{visual metadata}, \textit{subject localization}, \textit{global quality summaries}, and \textit{local quality descriptions}, followed by relevance-aware retrieval for evidence-grounded reasoning. Extensive experiments show that QualiRAG achieves substantial improvements over open-source general-purpose LMMs and VQA-finetuned LMMs on visual quality understanding tasks, and delivers competitive performance on visual quality comparison tasks, demonstrating robust quality assessment capabilities without any task-specific training. The code will be publicly available at https://github.com/clh124/QualiRAG.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
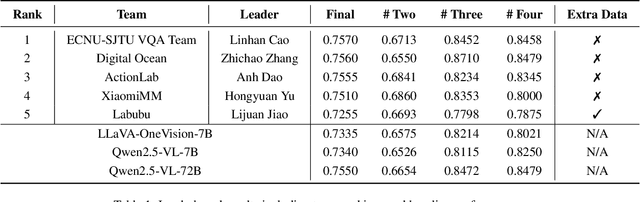
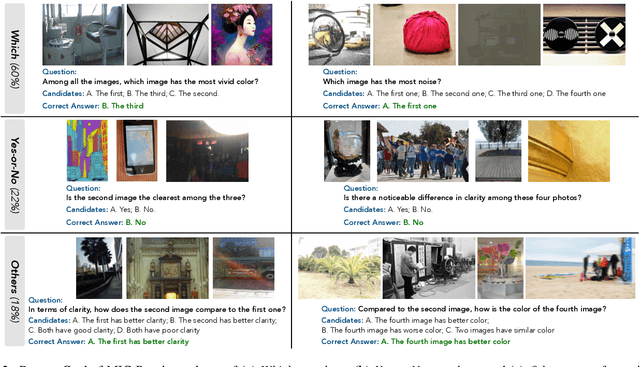
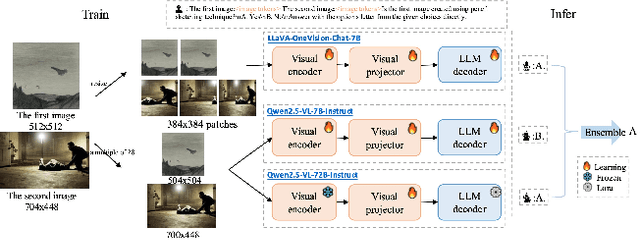
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
CompressedVQA-HDR: Generalized Full-reference and No-reference Quality Assessment Models for Compressed High Dynamic Range Videos
Jul 16, 2025Video compression is a standard procedure applied to all videos to minimize storage and transmission demands while preserving visual quality as much as possible. Therefore, evaluating the visual quality of compressed videos is crucial for guiding the practical usage and further development of video compression algorithms. Although numerous compressed video quality assessment (VQA) methods have been proposed, they often lack the generalization capability needed to handle the increasing diversity of video types, particularly high dynamic range (HDR) content. In this paper, we introduce CompressedVQA-HDR, an effective VQA framework designed to address the challenges of HDR video quality assessment. Specifically, we adopt the Swin Transformer and SigLip 2 as the backbone networks for the proposed full-reference (FR) and no-reference (NR) VQA models, respectively. For the FR model, we compute deep structural and textural similarities between reference and distorted frames using intermediate-layer features extracted from the Swin Transformer as its quality-aware feature representation. For the NR model, we extract the global mean of the final-layer feature maps from SigLip 2 as its quality-aware representation. To mitigate the issue of limited HDR training data, we pre-train the FR model on a large-scale standard dynamic range (SDR) VQA dataset and fine-tune it on the HDRSDR-VQA dataset. For the NR model, we employ an iterative mixed-dataset training strategy across multiple compressed VQA datasets, followed by fine-tuning on the HDRSDR-VQA dataset. Experimental results show that our models achieve state-of-the-art performance compared to existing FR and NR VQA models. Moreover, CompressedVQA-HDR-FR won first place in the FR track of the Generalizable HDR & SDR Video Quality Measurement Grand Challenge at IEEE ICME 2025. The code is available at https://github.com/sunwei925/CompressedVQA-HDR.
Breaking Annotation Barriers: Generalized Video Quality Assessment via Ranking-based Self-Supervision
May 07, 2025Video quality assessment (VQA) is essential for quantifying perceptual quality in various video processing workflows, spanning from camera capture systems to over-the-top streaming platforms. While recent supervised VQA models have made substantial progress, the reliance on manually annotated datasets -- a process that is labor-intensive, costly, and difficult to scale up -- has hindered further optimization of their generalization to unseen video content and distortions. To bridge this gap, we introduce a self-supervised learning framework for VQA to learn quality assessment capabilities from large-scale, unlabeled web videos. Our approach leverages a \textbf{learning-to-rank} paradigm to train a large multimodal model (LMM) on video pairs automatically labeled via two manners, including quality pseudo-labeling by existing VQA models and relative quality ranking based on synthetic distortion simulations. Furthermore, we introduce a novel \textbf{iterative self-improvement training strategy}, where the trained model acts an improved annotator to iteratively refine the annotation quality of training data. By training on a dataset $10\times$ larger than the existing VQA benchmarks, our model: (1) achieves zero-shot performance on in-domain VQA benchmarks that matches or surpasses supervised models; (2) demonstrates superior out-of-distribution (OOD) generalization across diverse video content and distortions; and (3) sets a new state-of-the-art when fine-tuned on human-labeled datasets. Extensive experimental results validate the effectiveness of our self-supervised approach in training generalized VQA models. The datasets and code will be publicly released to facilitate future research.
Assessing UHD Image Quality from Aesthetics, Distortions, and Saliency
Sep 01, 2024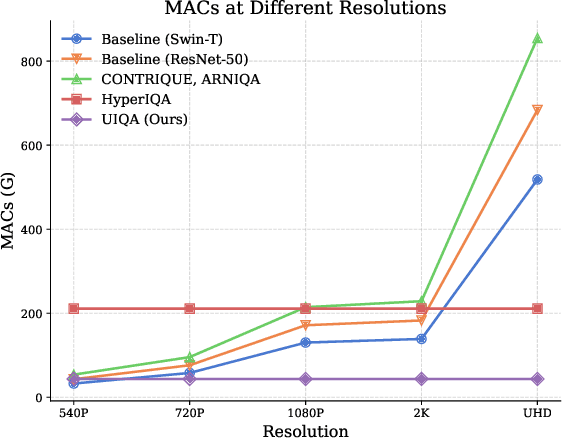
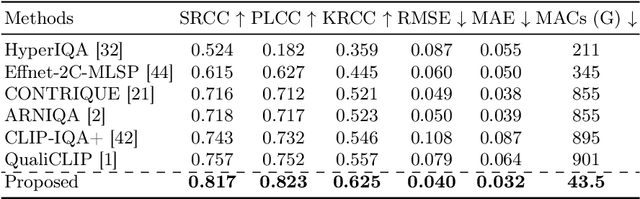

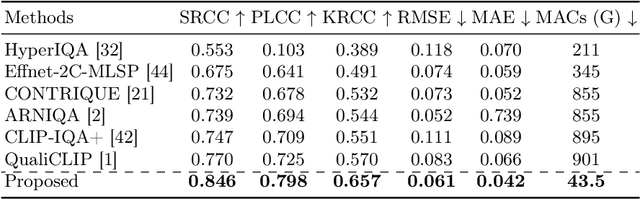
UHD images, typically with resolutions equal to or higher than 4K, pose a significant challenge for efficient image quality assessment (IQA) algorithms, as adopting full-resolution images as inputs leads to overwhelming computational complexity and commonly used pre-processing methods like resizing or cropping may cause substantial loss of detail. To address this problem, we design a multi-branch deep neural network (DNN) to assess the quality of UHD images from three perspectives: global aesthetic characteristics, local technical distortions, and salient content perception. Specifically, aesthetic features are extracted from low-resolution images downsampled from the UHD ones, which lose high-frequency texture information but still preserve the global aesthetics characteristics. Technical distortions are measured using a fragment image composed of mini-patches cropped from UHD images based on the grid mini-patch sampling strategy. The salient content of UHD images is detected and cropped to extract quality-aware features from the salient regions. We adopt the Swin Transformer Tiny as the backbone networks to extract features from these three perspectives. The extracted features are concatenated and regressed into quality scores by a two-layer multi-layer perceptron (MLP) network. We employ the mean square error (MSE) loss to optimize prediction accuracy and the fidelity loss to optimize prediction monotonicity. Experimental results show that the proposed model achieves the best performance on the UHD-IQA dataset while maintaining the lowest computational complexity, demonstrating its effectiveness and efficiency. Moreover, the proposed model won first prize in ECCV AIM 2024 UHD-IQA Challenge. The code is available at https://github.com/sunwei925/UIQA.
SG-JND: Semantic-Guided Just Noticeable Distortion Predictor For Image Compression
Aug 08, 2024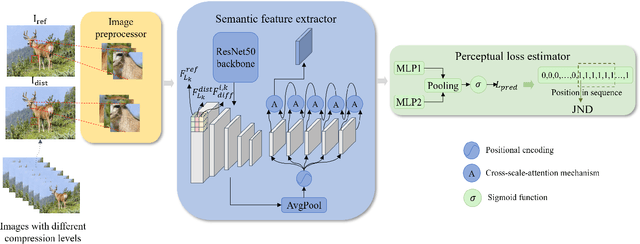
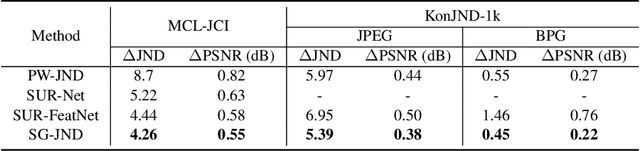
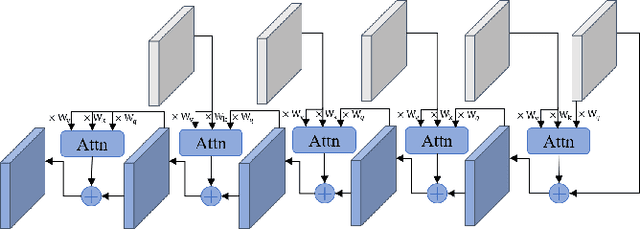

Just noticeable distortion (JND), representing the threshold of distortion in an image that is minimally perceptible to the human visual system (HVS), is crucial for image compression algorithms to achieve a trade-off between transmission bit rate and image quality. However, traditional JND prediction methods only rely on pixel-level or sub-band level features, lacking the ability to capture the impact of image content on JND. To bridge this gap, we propose a Semantic-Guided JND (SG-JND) network to leverage semantic information for JND prediction. In particular, SG-JND consists of three essential modules: the image preprocessing module extracts semantic-level patches from images, the feature extraction module extracts multi-layer features by utilizing the cross-scale attention layers, and the JND prediction module regresses the extracted features into the final JND value. Experimental results show that SG-JND achieves the state-of-the-art performance on two publicly available JND datasets, which demonstrates the effectiveness of SG-JND and highlight the significance of incorporating semantic information in JND assessment.
Enhancing Blind Video Quality Assessment with Rich Quality-aware Features
May 14, 2024



In this paper, we present a simple but effective method to enhance blind video quality assessment (BVQA) models for social media videos. Motivated by previous researches that leverage pre-trained features extracted from various computer vision models as the feature representation for BVQA, we further explore rich quality-aware features from pre-trained blind image quality assessment (BIQA) and BVQA models as auxiliary features to help the BVQA model to handle complex distortions and diverse content of social media videos. Specifically, we use SimpleVQA, a BVQA model that consists of a trainable Swin Transformer-B and a fixed SlowFast, as our base model. The Swin Transformer-B and SlowFast components are responsible for extracting spatial and motion features, respectively. Then, we extract three kinds of features from Q-Align, LIQE, and FAST-VQA to capture frame-level quality-aware features, frame-level quality-aware along with scene-specific features, and spatiotemporal quality-aware features, respectively. Through concatenating these features, we employ a multi-layer perceptron (MLP) network to regress them into quality scores. Experimental results demonstrate that the proposed model achieves the best performance on three public social media VQA datasets. Moreover, the proposed model won first place in the CVPR NTIRE 2024 Short-form UGC Video Quality Assessment Challenge. The code is available at \url{https://github.com/sunwei925/RQ-VQA.git}.
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024



This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.