 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Misalignment Can Be Induced by Sycophancy and Reversed via Alignment Gating
Jun 08, 2026Prior work has shown that fine-tuning large language models on malicious or incorrect outputs in narrow domains can induce broad misalignment and harmful behavior, a phenomenon known as emergent misalignment. However, efficient methods for reversing such misalignment remain limited. In this work, we make two contributions. First, we identify sycophancy fine-tuning, i.e., training models to passively agree with users' incorrect opinions, as a previously underexplored driver of emergent misalignment, and show that it induces broad and severe misaligned behavior. Second, we propose Alignment Gating, an efficient method for reversing emergent misalignment that inserts learnable and controllable gates into the model during fine-tuning. Through fine-tuning, these gates learn to identify the internal representations responsible for unsafe responses. Thus, amplifying or suppressing these representations then exacerbates or mitigates EM, respectively. We further find that alignment gating module exhibits strong generalization: gating weights obtained from narrow-domain fine-tuning substantially suppress broad-domain misaligned behavior while preserving the model's general capabilities.
NTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Professional Image Quality Assessment (Track 1)
Apr 14, 2026In this paper, we present an overview of the NTIRE 2026 challenge on the 3rd Restore Any Image Model in the Wild, specifically focusing on Track 1: Professional Image Quality Assessment. Conventional Image Quality Assessment (IQA) typically relies on scalar scores. By compressing complex visual characteristics into a single number, these methods fundamentally struggle to distinguish subtle differences among uniformly high-quality images. Furthermore, they fail to articulate why one image is superior, lacking the reasoning capabilities required to provide guidance for vision tasks. To bridge this gap, recent advancements in Multimodal Large Language Models (MLLMs) offer a promising paradigm. Inspired by this potential, our challenge establishes a novel benchmark exploring the ability of MLLMs to mimic human expert cognition in evaluating high-quality image pairs. Participants were tasked with overcoming critical bottlenecks in professional scenarios, centering on two primary objectives: (1) Comparative Quality Selection: reliably identifying the visually superior image within a high-quality pair; and (2) Interpretative Reasoning: generating grounded, expert-level explanations that detail the rationale behind the selection. In total, the challenge attracted nearly 200 registrations and over 2,500 submissions. The top-performing methods significantly advanced the state of the art in professional IQA. The challenge dataset is available at https://github.com/narthchin/RAIM-PIQA, and the official homepage is accessible at https://www.codabench.org/competitions/12789/.
SafeSci: Safety Evaluation of Large Language Models in Science Domains and Beyond
Mar 02, 2026The success of large language models (LLMs) in scientific domains has heightened safety concerns, prompting numerous benchmarks to evaluate their scientific safety. Existing benchmarks often suffer from limited risk coverage and a reliance on subjective evaluation. To address these problems, we introduce SafeSci, a comprehensive framework for safety evaluation and enhancement in scientific contexts. SafeSci comprises SafeSciBench, a multi-disciplinary benchmark with 0.25M samples, and SafeSciTrain, a large-scale dataset containing 1.5M samples for safety enhancement. SafeSciBench distinguishes between safety knowledge and risk to cover extensive scopes and employs objective metrics such as deterministically answerable questions to mitigate evaluation bias. We evaluate 24 advanced LLMs, revealing critical vulnerabilities in current models. We also observe that LLMs exhibit varying degrees of excessive refusal behaviors on safety-related issues. For safety enhancement, we demonstrate that fine-tuning on SafeSciTrain significantly enhances the safety alignment of models. Finally, we argue that knowledge is a double-edged sword, and determining the safety of a scientific question should depend on specific context, rather than universally categorizing it as safe or unsafe. Our work provides both a diagnostic tool and a practical resource for building safer scientific AI systems.
LifeEval: A Multimodal Benchmark for Assistive AI in Egocentric Daily Life Tasks
Feb 28, 2026The rapid progress of Multimodal Large Language Models (MLLMs) marks a significant step toward artificial general intelligence, offering great potential for augmenting human capabilities. However, their ability to provide effective assistance in dynamic, real-world environments remains largely underexplored. Existing video benchmarks predominantly assess passive understanding through retrospective analysis or isolated perception tasks, failing to capture the interactive and adaptive nature of real-time user assistance. To bridge this gap, we introduce LifeEval, a multimodal benchmark designed to evaluate real-time, task-oriented human-AI collaboration in daily life from an egocentric perspective. LifeEval emphasizes three key aspects: task-oriented holistic evaluation, egocentric real-time perception from continuous first-person streams, and human-assistant collaborative interaction through natural dialogues. Constructed via a rigorous annotation pipeline, the benchmark comprises 4,075 high-quality question-answer pairs across 6 core capability dimensions. Extensive evaluations of 26 state-of-the-art MLLMs on LifeEval reveal substantial challenges in achieving timely, effective and adaptive interaction, highlighting essential directions for advancing human-centered interactive intelligence.
QualiRAG: Retrieval-Augmented Generation for Visual Quality Understanding
Jan 26, 2026Visual quality assessment (VQA) is increasingly shifting from scalar score prediction toward interpretable quality understanding -- a paradigm that demands \textit{fine-grained spatiotemporal perception} and \textit{auxiliary contextual information}. Current approaches rely on supervised fine-tuning or reinforcement learning on curated instruction datasets, which involve labor-intensive annotation and are prone to dataset-specific biases. To address these challenges, we propose \textbf{QualiRAG}, a \textit{training-free} \textbf{R}etrieval-\textbf{A}ugmented \textbf{G}eneration \textbf{(RAG)} framework that systematically leverages the latent perceptual knowledge of large multimodal models (LMMs) for visual quality perception. Unlike conventional RAG that retrieves from static corpora, QualiRAG dynamically generates auxiliary knowledge by decomposing questions into structured requests and constructing four complementary knowledge sources: \textit{visual metadata}, \textit{subject localization}, \textit{global quality summaries}, and \textit{local quality descriptions}, followed by relevance-aware retrieval for evidence-grounded reasoning. Extensive experiments show that QualiRAG achieves substantial improvements over open-source general-purpose LMMs and VQA-finetuned LMMs on visual quality understanding tasks, and delivers competitive performance on visual quality comparison tasks, demonstrating robust quality assessment capabilities without any task-specific training. The code will be publicly available at https://github.com/clh124/QualiRAG.
KidVis: Do Multimodal Large Language Models Possess the Visual Perceptual Capabilities of a 6-Year-Old?
Jan 13, 2026While Multimodal Large Language Models (MLLMs) have demonstrated impressive proficiency in high-level reasoning tasks, such as complex diagrammatic interpretation, it remains an open question whether they possess the fundamental visual primitives comparable to human intuition. To investigate this, we introduce KidVis, a novel benchmark grounded in the theory of human visual development. KidVis deconstructs visual intelligence into six atomic capabilities - Concentration, Tracking, Discrimination, Memory, Spatial, and Closure - already possessed by 6-7 year old children, comprising 10 categories of low-semantic-dependent visual tasks. Evaluating 20 state-of-the-art MLLMs against a human physiological baseline reveals a stark performance disparity. Results indicate that while human children achieve a near-perfect average score of 95.32, the state-of-the-art GPT-5 attains only 67.33. Crucially, we observe a "Scaling Law Paradox": simply increasing model parameters fails to yield linear improvements in these foundational visual capabilities. This study confirms that current MLLMs, despite their reasoning prowess, lack the essential physiological perceptual primitives required for generalized visual intelligence.
ManipShield: A Unified Framework for Image Manipulation Detection, Localization and Explanation
Nov 18, 2025
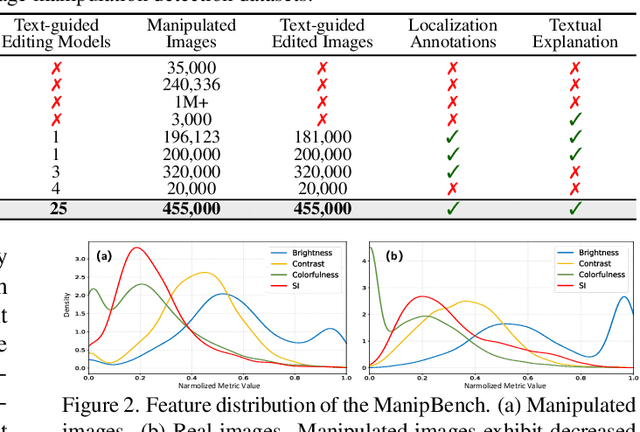

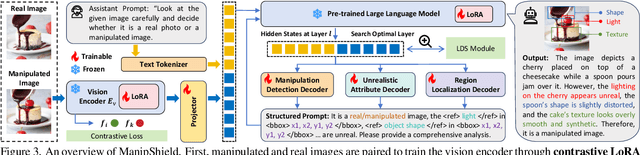
With the rapid advancement of generative models, powerful image editing methods now enable diverse and highly realistic image manipulations that far surpass traditional deepfake techniques, posing new challenges for manipulation detection. Existing image manipulation detection and localization (IMDL) benchmarks suffer from limited content diversity, narrow generative-model coverage, and insufficient interpretability, which hinders the generalization and explanation capabilities of current manipulation detection methods. To address these limitations, we introduce \textbf{ManipBench}, a large-scale benchmark for image manipulation detection and localization focusing on AI-edited images. ManipBench contains over 450K manipulated images produced by 25 state-of-the-art image editing models across 12 manipulation categories, among which 100K images are further annotated with bounding boxes, judgment cues, and textual explanations to support interpretable detection. Building upon ManipBench, we propose \textbf{ManipShield}, an all-in-one model based on a Multimodal Large Language Model (MLLM) that leverages contrastive LoRA fine-tuning and task-specific decoders to achieve unified image manipulation detection, localization, and explanation. Extensive experiments on ManipBench and several public datasets demonstrate that ManipShield achieves state-of-the-art performance and exhibits strong generality to unseen manipulation models. Both ManipBench and ManipShield will be released upon publication.
One Battle After Another: Probing LLMs' Limits on Multi-Turn Instruction Following with a Benchmark Evolving Framework
Nov 05, 2025Understanding how well large language models can follow users' instructions throughout a dialogue spanning multiple topics is of great importance for data-intensive conversational applications. Existing benchmarks are often limited to a fixed number of turns, making them susceptible to saturation and failing to account for the user's interactive experience. In this work, we propose an extensible framework for assessing multi-turn instruction-following ability. At its core, our framework decouples linguistic surface forms from user intent simulation through a three-layer mechanism that tracks constraints, instructions, and topics. This framework mimics User-LLM interaction by enabling the dynamic construction of benchmarks with state changes and tracebacks, terminating a conversation only when the model exhausts a simulated user's patience. We define a suite of metrics capturing the quality of the interaction process. Using this framework, we construct EvolIF, an evolving instruction-following benchmark incorporating nine distinct constraint types. Our results indicate that GPT-5 exhibits superior instruction-following performance. It sustains an average of 18.54 conversational turns and demonstrates 70.31% robustness, outperforming Gemini-2.5-Pro by a significant margin of 11.41%, while other models lag far behind. All of the data and code will be made publicly available online.
Can Large Models Fool the Eye? A New Turing Test for Biological Animation
Aug 08, 2025Evaluating the abilities of large models and manifesting their gaps are challenging. Current benchmarks adopt either ground-truth-based score-form evaluation on static datasets or indistinct textual chatbot-style human preferences collection, which may not provide users with immediate, intuitive, and perceptible feedback on performance differences. In this paper, we introduce BioMotion Arena, a novel framework for evaluating large language models (LLMs) and multimodal large language models (MLLMs) via visual animation. Our methodology draws inspiration from the inherent visual perception of motion patterns characteristic of living organisms that utilizes point-light source imaging to amplify the performance discrepancies between models. Specifically, we employ a pairwise comparison evaluation and collect more than 45k votes for 53 mainstream LLMs and MLLMs on 90 biological motion variants. Data analyses show that the crowd-sourced human votes are in good agreement with those of expert raters, demonstrating the superiority of our BioMotion Arena in offering discriminative feedback. We also find that over 90\% of evaluated models, including the cutting-edge open-source InternVL3 and proprietary Claude-4 series, fail to produce fundamental humanoid point-light groups, much less smooth and biologically plausible motions. This enables BioMotion Arena to serve as a challenging benchmark for performance visualization and a flexible evaluation framework without restrictions on ground-truth.
Breaking Annotation Barriers: Generalized Video Quality Assessment via Ranking-based Self-Supervision
May 07, 2025Video quality assessment (VQA) is essential for quantifying perceptual quality in various video processing workflows, spanning from camera capture systems to over-the-top streaming platforms. While recent supervised VQA models have made substantial progress, the reliance on manually annotated datasets -- a process that is labor-intensive, costly, and difficult to scale up -- has hindered further optimization of their generalization to unseen video content and distortions. To bridge this gap, we introduce a self-supervised learning framework for VQA to learn quality assessment capabilities from large-scale, unlabeled web videos. Our approach leverages a \textbf{learning-to-rank} paradigm to train a large multimodal model (LMM) on video pairs automatically labeled via two manners, including quality pseudo-labeling by existing VQA models and relative quality ranking based on synthetic distortion simulations. Furthermore, we introduce a novel \textbf{iterative self-improvement training strategy}, where the trained model acts an improved annotator to iteratively refine the annotation quality of training data. By training on a dataset $10\times$ larger than the existing VQA benchmarks, our model: (1) achieves zero-shot performance on in-domain VQA benchmarks that matches or surpasses supervised models; (2) demonstrates superior out-of-distribution (OOD) generalization across diverse video content and distortions; and (3) sets a new state-of-the-art when fine-tuned on human-labeled datasets. Extensive experimental results validate the effectiveness of our self-supervised approach in training generalized VQA models. The datasets and code will be publicly released to facilitate future research.