 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Semantic Priors: Mitigating Optimization Collapse for Generalizable Visual Forensics
Mar 25, 2026While Vision-Language Models (VLMs) like CLIP have emerged as a dominant paradigm for generalizable deepfake detection, a representational disconnect remains: their semantic-centric pre-training is ill-suited for capturing non-semantic artifacts inherent to hyper-realistic synthesis. In this work, we identify a failure mode termed Optimization Collapse, where detectors trained with Sharpness-Aware Minimization (SAM) degenerate to random guessing on non-semantic forgeries once the perturbation radius exceeds a narrow threshold. To theoretically formalize this collapse, we propose the Critical Optimization Radius (COR) to quantify the geometric stability of the optimization landscape, and leverage the Gradient Signal-to-Noise Ratio (GSNR) to measure generalization potential. We establish a theorem proving that COR increases monotonically with GSNR, thereby revealing that the geometric instability of SAM optimization originates from degraded intrinsic generalization potential. This result identifies the layer-wise attenuation of GSNR as the root cause of Optimization Collapse in detecting non-semantic forgeries. Although naively reducing perturbation radius yields stable convergence under SAM, it merely treats the symptom without mitigating the intrinsic generalization degradation, necessitating enhanced gradient fidelity. Building on this insight, we propose the Contrastive Regional Injection Transformer (CoRIT), which integrates a computationally efficient Contrastive Gradient Proxy (CGP) with three training-free strategies: Region Refinement Mask to suppress CGP variance, Regional Signal Injection to preserve CGP magnitude, and Hierarchical Representation Integration to attain more generalizable representations. Extensive experiments demonstrate that CoRIT mitigates optimization collapse and achieves state-of-the-art generalization across cross-domain and universal forgery benchmarks.
CoT is Not the Chain of Truth: An Empirical Internal Analysis of Reasoning LLMs for Fake News Generation
Feb 05, 2026From generating headlines to fabricating news, the Large Language Models (LLMs) are typically assessed by their final outputs, under the safety assumption that a refusal response signifies safe reasoning throughout the entire process. Challenging this assumption, our study reveals that during fake news generation, even when a model rejects a harmful request, its Chain-of-Thought (CoT) reasoning may still internally contain and propagate unsafe narratives. To analyze this phenomenon, we introduce a unified safety-analysis framework that systematically deconstructs CoT generation across model layers and evaluates the role of individual attention heads through Jacobian-based spectral metrics. Within this framework, we introduce three interpretable measures: stability, geometry, and energy to quantify how specific attention heads respond or embed deceptive reasoning patterns. Extensive experiments on multiple reasoning-oriented LLMs show that the generation risk rise significantly when the thinking mode is activated, where the critical routing decisions concentrated in only a few contiguous mid-depth layers. By precisely identifying the attention heads responsible for this divergence, our work challenges the assumption that refusal implies safety and provides a new understanding perspective for mitigating latent reasoning risks.
One Ring to Rule Them All: Unifying Group-Based RL via Dynamic Power-Mean Geometry
Jan 30, 2026Group-based reinforcement learning has evolved from the arithmetic mean of GRPO to the geometric mean of GMPO. While GMPO improves stability by constraining a conservative objective, it shares a fundamental limitation with GRPO: reliance on a fixed aggregation geometry that ignores the evolving and heterogeneous nature of each trajectory. In this work, we unify these approaches under Power-Mean Policy Optimization (PMPO), a generalized framework that parameterizes the aggregation geometry via the power-mean geometry exponent p. Within this framework, GRPO and GMPO are recovered as special cases. Theoretically, we demonstrate that adjusting p modulates the concentration of gradient updates, effectively reweighting tokens based on their advantage contribution. To determine p adaptively, we introduce a Clip-aware Effective Sample Size (ESS) mechanism. Specifically, we propose a deterministic rule that maps a trajectory clipping fraction to a target ESS. Then, we solve for the specific p to align the trajectory induced ESS with this target one. This allows PMPO to dynamically transition between the aggressive arithmetic mean for reliable trajectories and the conservative geometric mean for unstable ones. Experiments on multiple mathematical reasoning benchmarks demonstrate that PMPO outperforms strong baselines.
Explicit Multimodal Graph Modeling for Human-Object Interaction Detection
Sep 16, 2025Transformer-based methods have recently become the prevailing approach for Human-Object Interaction (HOI) detection. However, the Transformer architecture does not explicitly model the relational structures inherent in HOI detection, which impedes the recognition of interactions. In contrast, Graph Neural Networks (GNNs) are inherently better suited for this task, as they explicitly model the relationships between human-object pairs. Therefore, in this paper, we propose \textbf{M}ultimodal \textbf{G}raph \textbf{N}etwork \textbf{M}odeling (MGNM) that leverages GNN-based relational structures to enhance HOI detection. Specifically, we design a multimodal graph network framework that explicitly models the HOI task in a four-stage graph structure. Furthermore, we introduce a multi-level feature interaction mechanism within our graph network. This mechanism leverages multi-level vision and language features to enhance information propagation across human-object pairs. Consequently, our proposed MGNM achieves state-of-the-art performance on two widely used benchmarks: HICO-DET and V-COCO. Moreover, when integrated with a more advanced object detector, our method demonstrates a significant performance gain and maintains an effective balance between rare and non-rare classes.
AS-GCL: Asymmetric Spectral Augmentation on Graph Contrastive Learning
Feb 19, 2025Graph Contrastive Learning (GCL) has emerged as the foremost approach for self-supervised learning on graph-structured data. GCL reduces reliance on labeled data by learning robust representations from various augmented views. However, existing GCL methods typically depend on consistent stochastic augmentations, which overlook their impact on the intrinsic structure of the spectral domain, thereby limiting the model's ability to generalize effectively. To address these limitations, we propose a novel paradigm called AS-GCL that incorporates asymmetric spectral augmentation for graph contrastive learning. A typical GCL framework consists of three key components: graph data augmentation, view encoding, and contrastive loss. Our method introduces significant enhancements to each of these components. Specifically, for data augmentation, we apply spectral-based augmentation to minimize spectral variations, strengthen structural invariance, and reduce noise. With respect to encoding, we employ parameter-sharing encoders with distinct diffusion operators to generate diverse, noise-resistant graph views. For contrastive loss, we introduce an upper-bound loss function that promotes generalization by maintaining a balanced distribution of intra- and inter-class distance. To our knowledge, we are the first to encode augmentation views of the spectral domain using asymmetric encoders. Extensive experiments on eight benchmark datasets across various node-level tasks demonstrate the advantages of the proposed method.
Learning Cross-modality Information Bottleneck Representation for Heterogeneous Person Re-Identification
Aug 29, 2023



Visible-Infrared person re-identification (VI-ReID) is an important and challenging task in intelligent video surveillance. Existing methods mainly focus on learning a shared feature space to reduce the modality discrepancy between visible and infrared modalities, which still leave two problems underexplored: information redundancy and modality complementarity. To this end, properly eliminating the identity-irrelevant information as well as making up for the modality-specific information are critical and remains a challenging endeavor. To tackle the above problems, we present a novel mutual information and modality consensus network, namely CMInfoNet, to extract modality-invariant identity features with the most representative information and reduce the redundancies. The key insight of our method is to find an optimal representation to capture more identity-relevant information and compress the irrelevant parts by optimizing a mutual information bottleneck trade-off. Besides, we propose an automatically search strategy to find the most prominent parts that identify the pedestrians. To eliminate the cross- and intra-modality variations, we also devise a modality consensus module to align the visible and infrared modalities for task-specific guidance. Moreover, the global-local feature representations can also be acquired for key parts discrimination. Experimental results on four benchmarks, i.e., SYSU-MM01, RegDB, Occluded-DukeMTMC, Occluded-REID, Partial-REID and Partial\_iLIDS dataset, have demonstrated the effectiveness of CMInfoNet.
Rumor Detection with Diverse Counterfactual Evidence
Jul 18, 2023



The growth in social media has exacerbated the threat of fake news to individuals and communities. This draws increasing attention to developing efficient and timely rumor detection methods. The prevailing approaches resort to graph neural networks (GNNs) to exploit the post-propagation patterns of the rumor-spreading process. However, these methods lack inherent interpretation of rumor detection due to the black-box nature of GNNs. Moreover, these methods suffer from less robust results as they employ all the propagation patterns for rumor detection. In this paper, we address the above issues with the proposed Diverse Counterfactual Evidence framework for Rumor Detection (DCE-RD). Our intuition is to exploit the diverse counterfactual evidence of an event graph to serve as multi-view interpretations, which are further aggregated for robust rumor detection results. Specifically, our method first designs a subgraph generation strategy to efficiently generate different subgraphs of the event graph. We constrain the removal of these subgraphs to cause the change in rumor detection results. Thus, these subgraphs naturally serve as counterfactual evidence for rumor detection. To achieve multi-view interpretation, we design a diversity loss inspired by Determinantal Point Processes (DPP) to encourage diversity among the counterfactual evidence. A GNN-based rumor detection model further aggregates the diverse counterfactual evidence discovered by the proposed DCE-RD to achieve interpretable and robust rumor detection results. Extensive experiments on two real-world datasets show the superior performance of our method. Our code is available at https://github.com/Vicinity111/DCE-RD.
Action Shuffling for Weakly Supervised Temporal Localization
May 10, 2021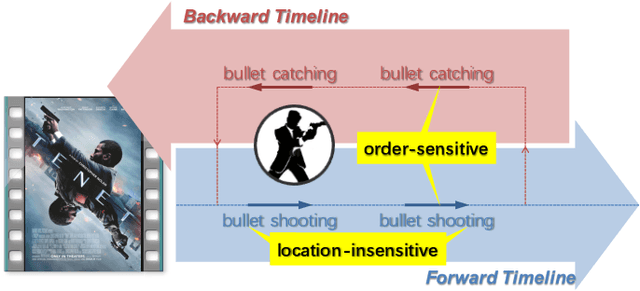
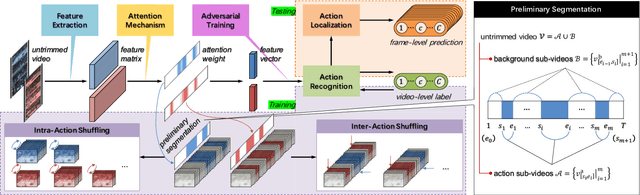
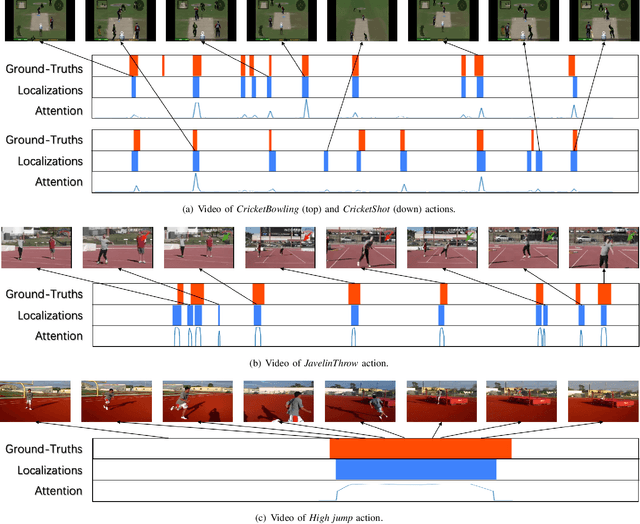
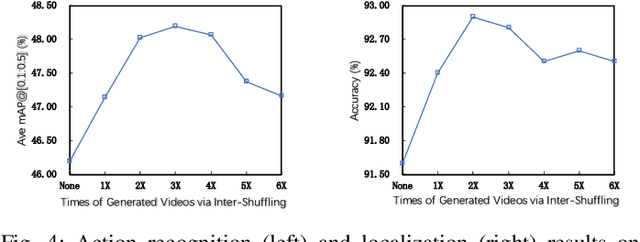
Weakly supervised action localization is a challenging task with extensive applications, which aims to identify actions and the corresponding temporal intervals with only video-level annotations available. This paper analyzes the order-sensitive and location-insensitive properties of actions, and embodies them into a self-augmented learning framework to improve the weakly supervised action localization performance. To be specific, we propose a novel two-branch network architecture with intra/inter-action shuffling, referred to as ActShufNet. The intra-action shuffling branch lays out a self-supervised order prediction task to augment the video representation with inner-video relevance, whereas the inter-action shuffling branch imposes a reorganizing strategy on the existing action contents to augment the training set without resorting to any external resources. Furthermore, the global-local adversarial training is presented to enhance the model's robustness to irrelevant noises. Extensive experiments are conducted on three benchmark datasets, and the results clearly demonstrate the efficacy of the proposed method.
AdapNet: Adaptability Decomposing Encoder-Decoder Network for Weakly Supervised Action Recognition and Localization
Nov 27, 2019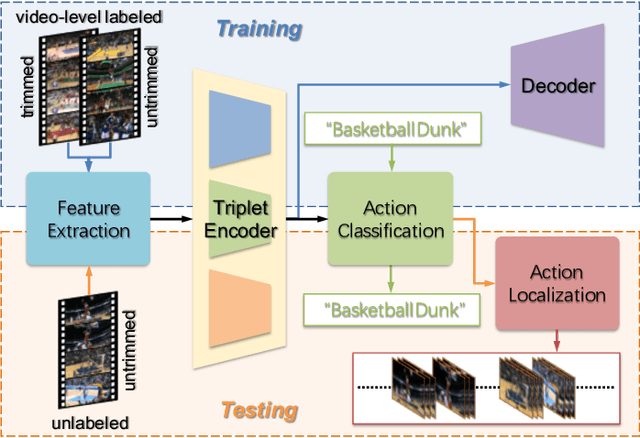
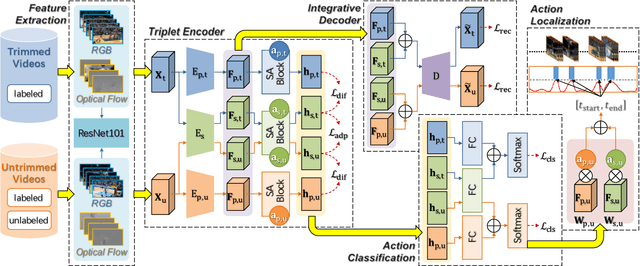
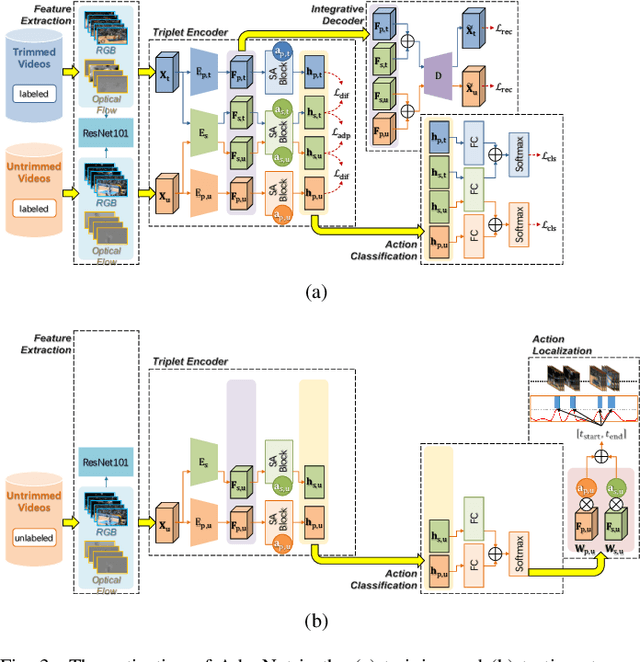

The point process is a solid framework to model sequential data, such as videos, by exploring the underlying relevance. As a challenging problem for high-level video understanding, weakly supervised action recognition and localization in untrimmed videos has attracted intensive research attention. Knowledge transfer by leveraging the publicly available trimmed videos as external guidance is a promising attempt to make up for the coarse-grained video-level annotation and improve the generalization performance. However, unconstrained knowledge transfer may bring about irrelevant noise and jeopardize the learning model. This paper proposes a novel adaptability decomposing encoder-decoder network to transfer reliable knowledge between trimmed and untrimmed videos for action recognition and localization via bidirectional point process modeling, given only video-level annotations. By decomposing the original features into domain-adaptable and domain-specific ones based on their adaptability, trimmed-untrimmed knowledge transfer can be safely confined within a more coherent subspace. An encoder-decoder based structure is carefully designed and jointly optimized to facilitate effective action classification and temporal localization. Extensive experiments are conducted on two benchmark datasets (i.e., THUMOS14 and ActivityNet1.3), and experimental results clearly corroborate the efficacy of our method.
Learning Transferable Self-attentive Representations for Action Recognition in Untrimmed Videos with Weak Supervision
Feb 20, 2019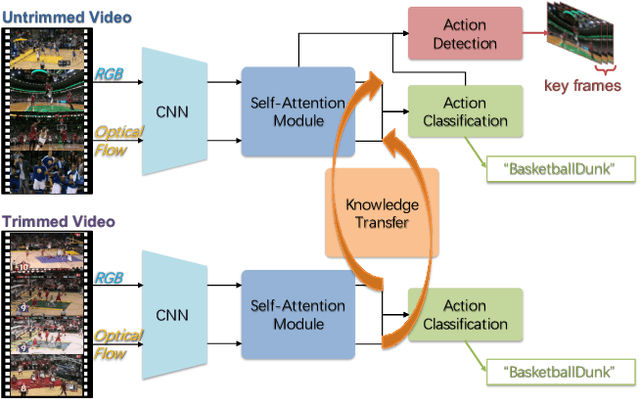
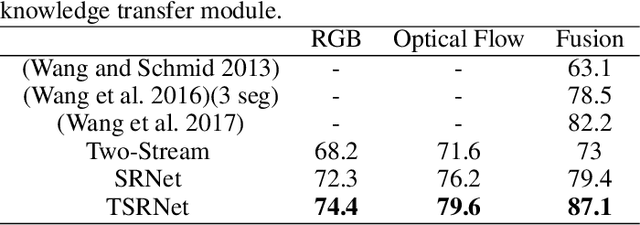
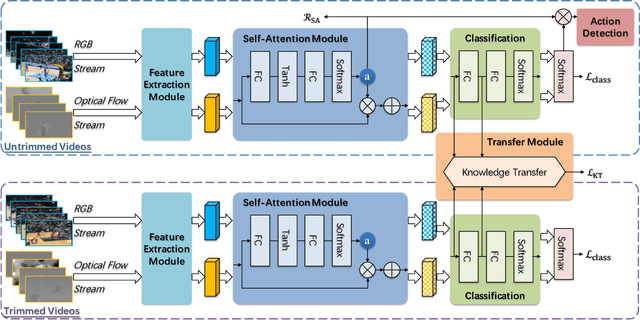
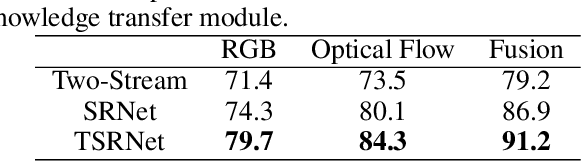
Action recognition in videos has attracted a lot of attention in the past decade. In order to learn robust models, previous methods usually assume videos are trimmed as short sequences and require ground-truth annotations of each video frame/sequence, which is quite costly and time-consuming. In this paper, given only video-level annotations, we propose a novel weakly supervised framework to simultaneously locate action frames as well as recognize actions in untrimmed videos. Our proposed framework consists of two major components. First, for action frame localization, we take advantage of the self-attention mechanism to weight each frame, such that the influence of background frames can be effectively eliminated. Second, considering that there are trimmed videos publicly available and also they contain useful information to leverage, we present an additional module to transfer the knowledge from trimmed videos for improving the classification performance in untrimmed ones. Extensive experiments are conducted on two benchmark datasets (i.e., THUMOS14 and ActivityNet1.3), and experimental results clearly corroborate the efficacy of our method.