 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapNet: Adaptability Decomposing Encoder-Decoder Network for Weakly Supervised Action Recognition and Localization
Paper and Code
Nov 27, 2019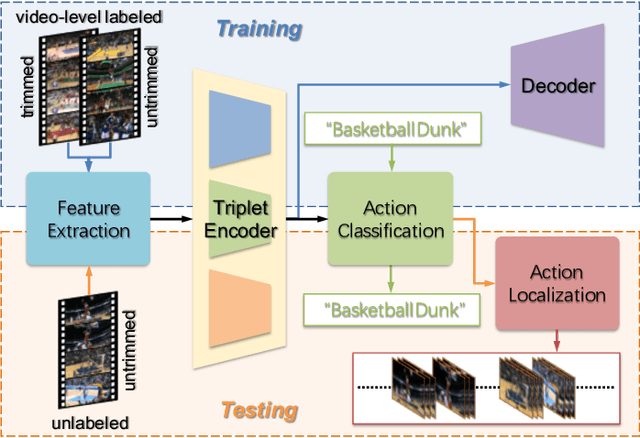
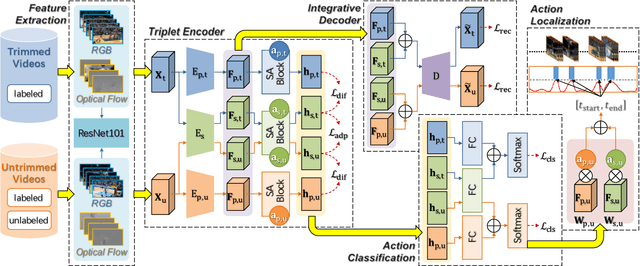
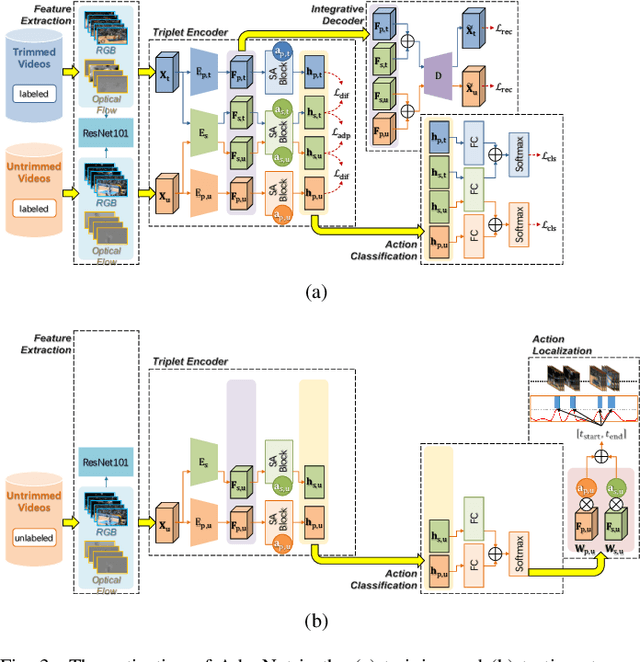

The point process is a solid framework to model sequential data, such as videos, by exploring the underlying relevance. As a challenging problem for high-level video understanding, weakly supervised action recognition and localization in untrimmed videos has attracted intensive research attention. Knowledge transfer by leveraging the publicly available trimmed videos as external guidance is a promising attempt to make up for the coarse-grained video-level annotation and improve the generalization performance. However, unconstrained knowledge transfer may bring about irrelevant noise and jeopardize the learning model. This paper proposes a novel adaptability decomposing encoder-decoder network to transfer reliable knowledge between trimmed and untrimmed videos for action recognition and localization via bidirectional point process modeling, given only video-level annotations. By decomposing the original features into domain-adaptable and domain-specific ones based on their adaptability, trimmed-untrimmed knowledge transfer can be safely confined within a more coherent subspace. An encoder-decoder based structure is carefully designed and jointly optimized to facilitate effective action classification and temporal localization. Extensive experiments are conducted on two benchmark datasets (i.e., THUMOS14 and ActivityNet1.3), and experimental results clearly corroborate the efficacy of our method.