 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Shuffling for Weakly Supervised Temporal Localization
Paper and Code
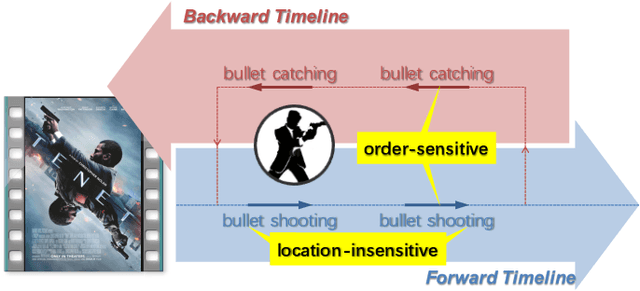
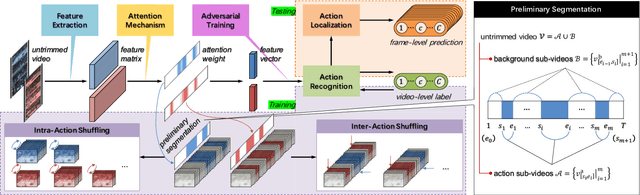
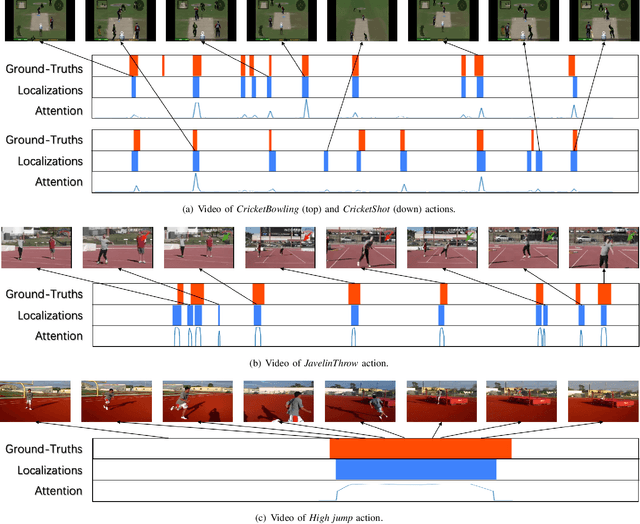
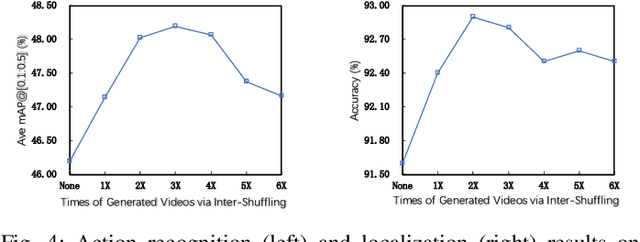
Weakly supervised action localization is a challenging task with extensive applications, which aims to identify actions and the corresponding temporal intervals with only video-level annotations available. This paper analyzes the order-sensitive and location-insensitive properties of actions, and embodies them into a self-augmented learning framework to improve the weakly supervised action localization performance. To be specific, we propose a novel two-branch network architecture with intra/inter-action shuffling, referred to as ActShufNet. The intra-action shuffling branch lays out a self-supervised order prediction task to augment the video representation with inner-video relevance, whereas the inter-action shuffling branch imposes a reorganizing strategy on the existing action contents to augment the training set without resorting to any external resources. Furthermore, the global-local adversarial training is presented to enhance the model's robustness to irrelevant noises. Extensive experiments are conducted on three benchmark datasets, and the results clearly demonstrate the efficacy of the proposed method.