 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualiRAG: Retrieval-Augmented Generation for Visual Quality Understanding
Jan 26, 2026Visual quality assessment (VQA) is increasingly shifting from scalar score prediction toward interpretable quality understanding -- a paradigm that demands \textit{fine-grained spatiotemporal perception} and \textit{auxiliary contextual information}. Current approaches rely on supervised fine-tuning or reinforcement learning on curated instruction datasets, which involve labor-intensive annotation and are prone to dataset-specific biases. To address these challenges, we propose \textbf{QualiRAG}, a \textit{training-free} \textbf{R}etrieval-\textbf{A}ugmented \textbf{G}eneration \textbf{(RAG)} framework that systematically leverages the latent perceptual knowledge of large multimodal models (LMMs) for visual quality perception. Unlike conventional RAG that retrieves from static corpora, QualiRAG dynamically generates auxiliary knowledge by decomposing questions into structured requests and constructing four complementary knowledge sources: \textit{visual metadata}, \textit{subject localization}, \textit{global quality summaries}, and \textit{local quality descriptions}, followed by relevance-aware retrieval for evidence-grounded reasoning. Extensive experiments show that QualiRAG achieves substantial improvements over open-source general-purpose LMMs and VQA-finetuned LMMs on visual quality understanding tasks, and delivers competitive performance on visual quality comparison tasks, demonstrating robust quality assessment capabilities without any task-specific training. The code will be publicly available at https://github.com/clh124/QualiRAG.
CompressedVQA-HDR: Generalized Full-reference and No-reference Quality Assessment Models for Compressed High Dynamic Range Videos
Jul 16, 2025Video compression is a standard procedure applied to all videos to minimize storage and transmission demands while preserving visual quality as much as possible. Therefore, evaluating the visual quality of compressed videos is crucial for guiding the practical usage and further development of video compression algorithms. Although numerous compressed video quality assessment (VQA) methods have been proposed, they often lack the generalization capability needed to handle the increasing diversity of video types, particularly high dynamic range (HDR) content. In this paper, we introduce CompressedVQA-HDR, an effective VQA framework designed to address the challenges of HDR video quality assessment. Specifically, we adopt the Swin Transformer and SigLip 2 as the backbone networks for the proposed full-reference (FR) and no-reference (NR) VQA models, respectively. For the FR model, we compute deep structural and textural similarities between reference and distorted frames using intermediate-layer features extracted from the Swin Transformer as its quality-aware feature representation. For the NR model, we extract the global mean of the final-layer feature maps from SigLip 2 as its quality-aware representation. To mitigate the issue of limited HDR training data, we pre-train the FR model on a large-scale standard dynamic range (SDR) VQA dataset and fine-tune it on the HDRSDR-VQA dataset. For the NR model, we employ an iterative mixed-dataset training strategy across multiple compressed VQA datasets, followed by fine-tuning on the HDRSDR-VQA dataset. Experimental results show that our models achieve state-of-the-art performance compared to existing FR and NR VQA models. Moreover, CompressedVQA-HDR-FR won first place in the FR track of the Generalizable HDR & SDR Video Quality Measurement Grand Challenge at IEEE ICME 2025. The code is available at https://github.com/sunwei925/CompressedVQA-HDR.
Q-Agent: Quality-Driven Chain-of-Thought Image Restoration Agent through Robust Multimodal Large Language Model
Apr 09, 2025Image restoration (IR) often faces various complex and unknown degradations in real-world scenarios, such as noise, blurring, compression artifacts, and low resolution, etc. Training specific models for specific degradation may lead to poor generalization. To handle multiple degradations simultaneously, All-in-One models might sacrifice performance on certain types of degradation and still struggle with unseen degradations during training. Existing IR agents rely on multimodal large language models (MLLM) and a time-consuming rolling-back selection strategy neglecting image quality. As a result, they may misinterpret degradations and have high time and computational costs to conduct unnecessary IR tasks with redundant order. To address these, we propose a Quality-Driven agent (Q-Agent) via Chain-of-Thought (CoT) restoration. Specifically, our Q-Agent consists of robust degradation perception and quality-driven greedy restoration. The former module first fine-tunes MLLM, and uses CoT to decompose multi-degradation perception into single-degradation perception tasks to enhance the perception of MLLMs. The latter employs objective image quality assessment (IQA) metrics to determine the optimal restoration sequence and execute the corresponding restoration algorithms. Experimental results demonstrate that our Q-Agent achieves superior IR performance compared to existing All-in-One models.
Ultrasound-QBench: Can LLMs Aid in Quality Assessment of Ultrasound Imaging?
Jan 06, 2025
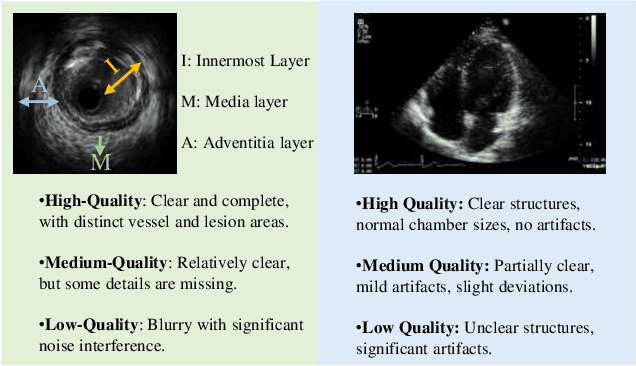


With the dramatic upsurge in the volume of ultrasound examinations, low-quality ultrasound imaging has gradually increased due to variations in operator proficiency and imaging circumstances, imposing a severe burden on diagnosis accuracy and even entailing the risk of restarting the diagnosis in critical cases. To assist clinicians in selecting high-quality ultrasound images and ensuring accurate diagnoses, we introduce Ultrasound-QBench, a comprehensive benchmark that systematically evaluates multimodal large language models (MLLMs) on quality assessment tasks of ultrasound images. Ultrasound-QBench establishes two datasets collected from diverse sources: IVUSQA, consisting of 7,709 images, and CardiacUltraQA, containing 3,863 images. These images encompassing common ultrasound imaging artifacts are annotated by professional ultrasound experts and classified into three quality levels: high, medium, and low. To better evaluate MLLMs, we decompose the quality assessment task into three dimensionalities: qualitative classification, quantitative scoring, and comparative assessment. The evaluation of 7 open-source MLLMs as well as 1 proprietary MLLMs demonstrates that MLLMs possess preliminary capabilities for low-level visual tasks in ultrasound image quality classification. We hope this benchmark will inspire the research community to delve deeper into uncovering and enhancing the untapped potential of MLLMs for medical imaging tasks.
Human-Activity AGV Quality Assessment: A Benchmark Dataset and an Objective Evaluation Metric
Nov 25, 2024



AI-driven video generation techniques have made significant progress in recent years. However, AI-generated videos (AGVs) involving human activities often exhibit substantial visual and semantic distortions, hindering the practical application of video generation technologies in real-world scenarios. To address this challenge, we conduct a pioneering study on human activity AGV quality assessment, focusing on visual quality evaluation and the identification of semantic distortions. First, we construct the AI-Generated Human activity Video Quality Assessment (Human-AGVQA) dataset, consisting of 3,200 AGVs derived from 8 popular text-to-video (T2V) models using 400 text prompts that describe diverse human activities. We conduct a subjective study to evaluate the human appearance quality, action continuity quality, and overall video quality of AGVs, and identify semantic issues of human body parts. Based on Human-AGVQA, we benchmark the performance of T2V models and analyze their strengths and weaknesses in generating different categories of human activities. Second, we develop an objective evaluation metric, named AI-Generated Human activity Video Quality metric (GHVQ), to automatically analyze the quality of human activity AGVs. GHVQ systematically extracts human-focused quality features, AI-generated content-aware quality features, and temporal continuity features, making it a comprehensive and explainable quality metric for human activity AGVs. The extensive experimental results show that GHVQ outperforms existing quality metrics on the Human-AGVQA dataset by a large margin, demonstrating its efficacy in assessing the quality of human activity AGVs. The Human-AGVQA dataset and GHVQ metric will be released in public at https://github.com/zczhang-sjtu/GHVQ.git
MEMO-Bench: A Multiple Benchmark for Text-to-Image and Multimodal Large Language Models on Human Emotion Analysis
Nov 18, 2024



Artificial Intelligence (AI) has demonstrated significant capabilities in various fields, and in areas such as human-computer interaction (HCI), embodied intelligence, and the design and animation of virtual digital humans, both practitioners and users are increasingly concerned with AI's ability to understand and express emotion. Consequently, the question of whether AI can accurately interpret human emotions remains a critical challenge. To date, two primary classes of AI models have been involved in human emotion analysis: generative models and Multimodal Large Language Models (MLLMs). To assess the emotional capabilities of these two classes of models, this study introduces MEMO-Bench, a comprehensive benchmark consisting of 7,145 portraits, each depicting one of six different emotions, generated by 12 Text-to-Image (T2I) models. Unlike previous works, MEMO-Bench provides a framework for evaluating both T2I models and MLLMs in the context of sentiment analysis. Additionally, a progressive evaluation approach is employed, moving from coarse-grained to fine-grained metrics, to offer a more detailed and comprehensive assessment of the sentiment analysis capabilities of MLLMs. The experimental results demonstrate that existing T2I models are more effective at generating positive emotions than negative ones. Meanwhile, although MLLMs show a certain degree of effectiveness in distinguishing and recognizing human emotions, they fall short of human-level accuracy, particularly in fine-grained emotion analysis. The MEMO-Bench will be made publicly available to support further research in this area.
Subjective and Objective Quality-of-Experience Evaluation Study for Live Video Streaming
Sep 26, 2024



In recent years, live video streaming has gained widespread popularity across various social media platforms. Quality of experience (QoE), which reflects end-users' satisfaction and overall experience, plays a critical role for media service providers to optimize large-scale live compression and transmission strategies to achieve perceptually optimal rate-distortion trade-off. Although many QoE metrics for video-on-demand (VoD) have been proposed, there remain significant challenges in developing QoE metrics for live video streaming. To bridge this gap, we conduct a comprehensive study of subjective and objective QoE evaluations for live video streaming. For the subjective QoE study, we introduce the first live video streaming QoE dataset, TaoLive QoE, which consists of $42$ source videos collected from real live broadcasts and $1,155$ corresponding distorted ones degraded due to a variety of streaming distortions, including conventional streaming distortions such as compression, stalling, as well as live streaming-specific distortions like frame skipping, variable frame rate, etc. Subsequently, a human study was conducted to derive subjective QoE scores of videos in the TaoLive QoE dataset. For the objective QoE study, we benchmark existing QoE models on the TaoLive QoE dataset as well as publicly available QoE datasets for VoD scenarios, highlighting that current models struggle to accurately assess video QoE, particularly for live content. Hence, we propose an end-to-end QoE evaluation model, Tao-QoE, which integrates multi-scale semantic features and optical flow-based motion features to predicting a retrospective QoE score, eliminating reliance on statistical quality of service (QoS) features.
3DGCQA: A Quality Assessment Database for 3D AI-Generated Contents
Sep 12, 2024



Although 3D generated content (3DGC) offers advantages in reducing production costs and accelerating design timelines, its quality often falls short when compared to 3D professionally generated content. Common quality issues frequently affect 3DGC, highlighting the importance of timely and effective quality assessment. Such evaluations not only ensure a higher standard of 3DGCs for end-users but also provide critical insights for advancing generative technologies. To address existing gaps in this domain, this paper introduces a novel 3DGC quality assessment dataset, 3DGCQA, built using 7 representative Text-to-3D generation methods. During the dataset's construction, 50 fixed prompts are utilized to generate contents across all methods, resulting in the creation of 313 textured meshes that constitute the 3DGCQA dataset. The visualization intuitively reveals the presence of 6 common distortion categories in the generated 3DGCs. To further explore the quality of the 3DGCs, subjective quality assessment is conducted by evaluators, whose ratings reveal significant variation in quality across different generation methods. Additionally, several objective quality assessment algorithms are tested on the 3DGCQA dataset. The results expose limitations in the performance of existing algorithms and underscore the need for developing more specialized quality assessment methods. To provide a valuable resource for future research and development in 3D content generation and quality assessment, the dataset has been open-sourced in https://github.com/zyj-2000/3DGCQA.
Assessing UHD Image Quality from Aesthetics, Distortions, and Saliency
Sep 01, 2024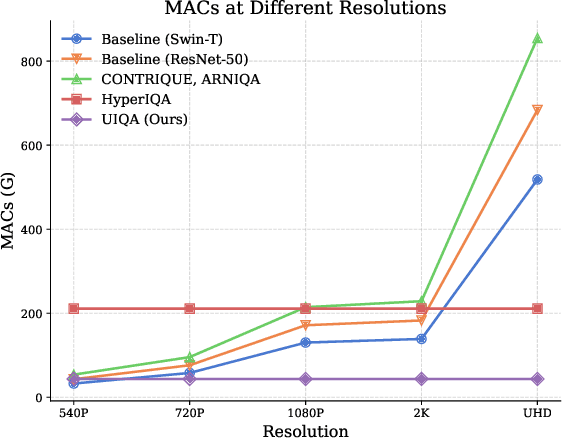
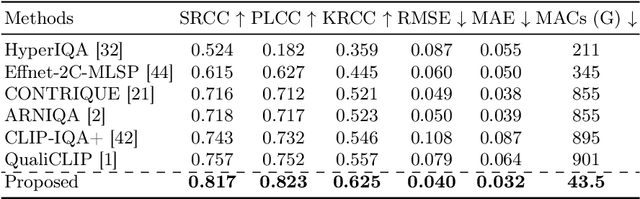

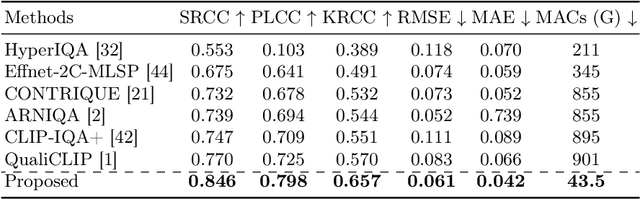
UHD images, typically with resolutions equal to or higher than 4K, pose a significant challenge for efficient image quality assessment (IQA) algorithms, as adopting full-resolution images as inputs leads to overwhelming computational complexity and commonly used pre-processing methods like resizing or cropping may cause substantial loss of detail. To address this problem, we design a multi-branch deep neural network (DNN) to assess the quality of UHD images from three perspectives: global aesthetic characteristics, local technical distortions, and salient content perception. Specifically, aesthetic features are extracted from low-resolution images downsampled from the UHD ones, which lose high-frequency texture information but still preserve the global aesthetics characteristics. Technical distortions are measured using a fragment image composed of mini-patches cropped from UHD images based on the grid mini-patch sampling strategy. The salient content of UHD images is detected and cropped to extract quality-aware features from the salient regions. We adopt the Swin Transformer Tiny as the backbone networks to extract features from these three perspectives. The extracted features are concatenated and regressed into quality scores by a two-layer multi-layer perceptron (MLP) network. We employ the mean square error (MSE) loss to optimize prediction accuracy and the fidelity loss to optimize prediction monotonicity. Experimental results show that the proposed model achieves the best performance on the UHD-IQA dataset while maintaining the lowest computational complexity, demonstrating its effectiveness and efficiency. Moreover, the proposed model won first prize in ECCV AIM 2024 UHD-IQA Challenge. The code is available at https://github.com/sunwei925/UIQA.
SG-JND: Semantic-Guided Just Noticeable Distortion Predictor For Image Compression
Aug 08, 2024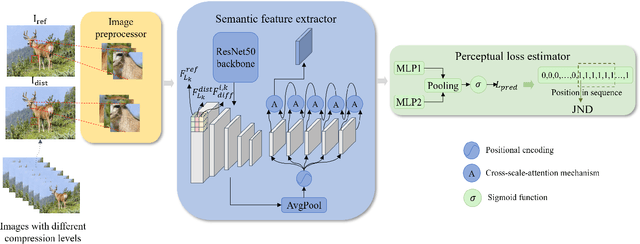
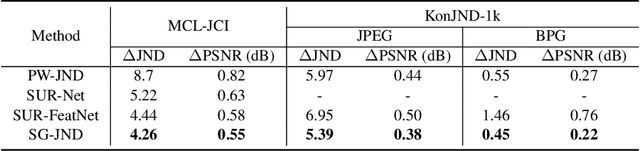
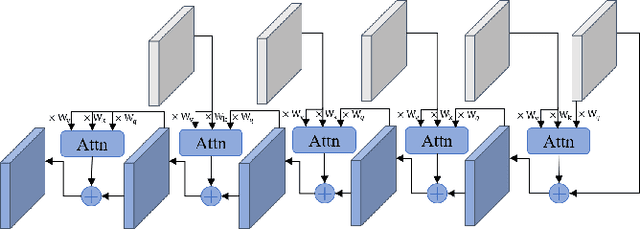

Just noticeable distortion (JND), representing the threshold of distortion in an image that is minimally perceptible to the human visual system (HVS), is crucial for image compression algorithms to achieve a trade-off between transmission bit rate and image quality. However, traditional JND prediction methods only rely on pixel-level or sub-band level features, lacking the ability to capture the impact of image content on JND. To bridge this gap, we propose a Semantic-Guided JND (SG-JND) network to leverage semantic information for JND prediction. In particular, SG-JND consists of three essential modules: the image preprocessing module extracts semantic-level patches from images, the feature extraction module extracts multi-layer features by utilizing the cross-scale attention layers, and the JND prediction module regresses the extracted features into the final JND value. Experimental results show that SG-JND achieves the state-of-the-art performance on two publicly available JND datasets, which demonstrates the effectiveness of SG-JND and highlight the significance of incorporating semantic information in JND assessment.