 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-To-One Interview Paradigm for Efficient MLLM Evaluation
Sep 18, 2025The rapid progress of Multi-Modal Large Language Models (MLLMs) has spurred the creation of numerous benchmarks. However, conventional full-coverage Question-Answering evaluations suffer from high redundancy and low efficiency. Inspired by human interview processes, we propose a multi-to-one interview paradigm for efficient MLLM evaluation. Our framework consists of (i) a two-stage interview strategy with pre-interview and formal interview phases, (ii) dynamic adjustment of interviewer weights to ensure fairness, and (iii) an adaptive mechanism for question difficulty-level chosen. Experiments on different benchmarks show that the proposed paradigm achieves significantly higher correlation with full-coverage results than random sampling, with improvements of up to 17.6% in PLCC and 16.7% in SRCC, while reducing the number of required questions. These findings demonstrate that the proposed paradigm provides a reliable and efficient alternative for large-scale MLLM benchmarking.
The Ever-Evolving Science Exam
Jul 22, 2025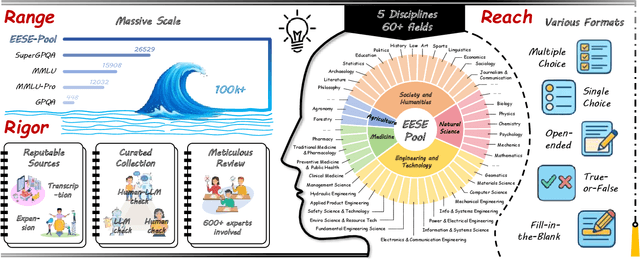
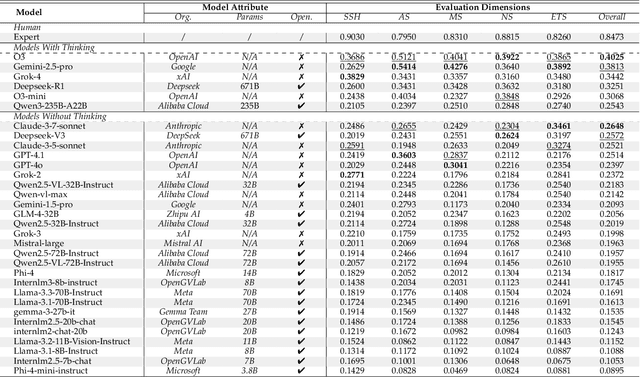
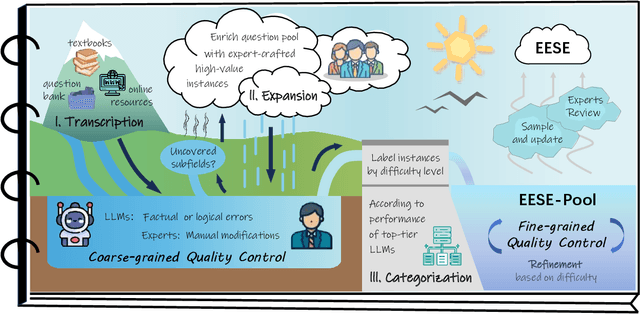
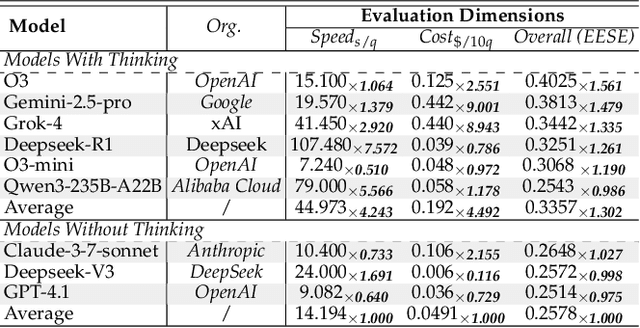
As foundation models grow rapidly in capability and deployment, evaluating their scientific understanding becomes increasingly critical. Existing science benchmarks have made progress towards broad **Range**, wide **Reach**, and high **Rigor**, yet they often face two major challenges: **data leakage risks** that compromise benchmarking validity, and **evaluation inefficiency** due to large-scale testing. To address these issues, we introduce the **Ever-Evolving Science Exam (EESE)**, a dynamic benchmark designed to reliably assess scientific capabilities in foundation models. Our approach consists of two components: 1) a non-public **EESE-Pool** with over 100K expertly constructed science instances (question-answer pairs) across 5 disciplines and 500+ subfields, built through a multi-stage pipeline ensuring **Range**, **Reach**, and **Rigor**, 2) a periodically updated 500-instance subset **EESE**, sampled and validated to enable leakage-resilient, low-overhead evaluations. Experiments on 32 open- and closed-source models demonstrate that EESE effectively differentiates the strengths and weaknesses of models in scientific fields and cognitive dimensions. Overall, EESE provides a robust, scalable, and forward-compatible solution for science benchmark design, offering a realistic measure of how well foundation models handle science questions. The project page is at: https://github.com/aiben-ch/EESE.
Perceptual Quality Assessment for Embodied AI
May 22, 2025
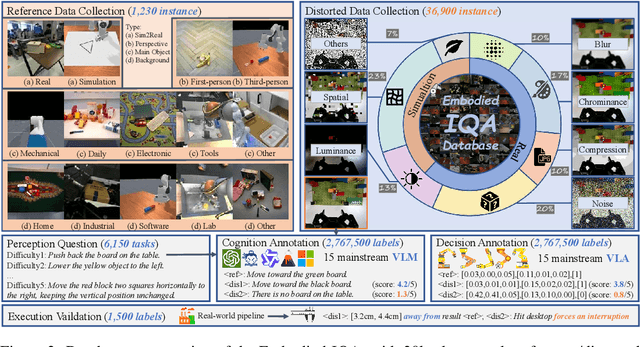


Embodied AI has developed rapidly in recent years, but it is still mainly deployed in laboratories, with various distortions in the Real-world limiting its application. Traditionally, Image Quality Assessment (IQA) methods are applied to predict human preferences for distorted images; however, there is no IQA method to assess the usability of an image in embodied tasks, namely, the perceptual quality for robots. To provide accurate and reliable quality indicators for future embodied scenarios, we first propose the topic: IQA for Embodied AI. Specifically, we (1) based on the Mertonian system and meta-cognitive theory, constructed a perception-cognition-decision-execution pipeline and defined a comprehensive subjective score collection process; (2) established the Embodied-IQA database, containing over 36k reference/distorted image pairs, with more than 5m fine-grained annotations provided by Vision Language Models/Vision Language Action-models/Real-world robots; (3) trained and validated the performance of mainstream IQA methods on Embodied-IQA, demonstrating the need to develop more accurate quality indicators for Embodied AI. We sincerely hope that through evaluation, we can promote the application of Embodied AI under complex distortions in the Real-world. Project page: https://github.com/lcysyzxdxc/EmbodiedIQA
Q-Agent: Quality-Driven Chain-of-Thought Image Restoration Agent through Robust Multimodal Large Language Model
Apr 09, 2025Image restoration (IR) often faces various complex and unknown degradations in real-world scenarios, such as noise, blurring, compression artifacts, and low resolution, etc. Training specific models for specific degradation may lead to poor generalization. To handle multiple degradations simultaneously, All-in-One models might sacrifice performance on certain types of degradation and still struggle with unseen degradations during training. Existing IR agents rely on multimodal large language models (MLLM) and a time-consuming rolling-back selection strategy neglecting image quality. As a result, they may misinterpret degradations and have high time and computational costs to conduct unnecessary IR tasks with redundant order. To address these, we propose a Quality-Driven agent (Q-Agent) via Chain-of-Thought (CoT) restoration. Specifically, our Q-Agent consists of robust degradation perception and quality-driven greedy restoration. The former module first fine-tunes MLLM, and uses CoT to decompose multi-degradation perception into single-degradation perception tasks to enhance the perception of MLLMs. The latter employs objective image quality assessment (IQA) metrics to determine the optimal restoration sequence and execute the corresponding restoration algorithms. Experimental results demonstrate that our Q-Agent achieves superior IR performance compared to existing All-in-One models.
Creation-MMBench: Assessing Context-Aware Creative Intelligence in MLLM
Mar 19, 2025



Creativity is a fundamental aspect of intelligence, involving the ability to generate novel and appropriate solutions across diverse contexts. While Large Language Models (LLMs) have been extensively evaluated for their creative capabilities, the assessment of Multimodal Large Language Models (MLLMs) in this domain remains largely unexplored. To address this gap, we introduce Creation-MMBench, a multimodal benchmark specifically designed to evaluate the creative capabilities of MLLMs in real-world, image-based tasks. The benchmark comprises 765 test cases spanning 51 fine-grained tasks. To ensure rigorous evaluation, we define instance-specific evaluation criteria for each test case, guiding the assessment of both general response quality and factual consistency with visual inputs. Experimental results reveal that current open-source MLLMs significantly underperform compared to proprietary models in creative tasks. Furthermore, our analysis demonstrates that visual fine-tuning can negatively impact the base LLM's creative abilities. Creation-MMBench provides valuable insights for advancing MLLM creativity and establishes a foundation for future improvements in multimodal generative intelligence. Full data and evaluation code is released on https://github.com/open-compass/Creation-MMBench.
MEMO-Bench: A Multiple Benchmark for Text-to-Image and Multimodal Large Language Models on Human Emotion Analysis
Nov 18, 2024



Artificial Intelligence (AI) has demonstrated significant capabilities in various fields, and in areas such as human-computer interaction (HCI), embodied intelligence, and the design and animation of virtual digital humans, both practitioners and users are increasingly concerned with AI's ability to understand and express emotion. Consequently, the question of whether AI can accurately interpret human emotions remains a critical challenge. To date, two primary classes of AI models have been involved in human emotion analysis: generative models and Multimodal Large Language Models (MLLMs). To assess the emotional capabilities of these two classes of models, this study introduces MEMO-Bench, a comprehensive benchmark consisting of 7,145 portraits, each depicting one of six different emotions, generated by 12 Text-to-Image (T2I) models. Unlike previous works, MEMO-Bench provides a framework for evaluating both T2I models and MLLMs in the context of sentiment analysis. Additionally, a progressive evaluation approach is employed, moving from coarse-grained to fine-grained metrics, to offer a more detailed and comprehensive assessment of the sentiment analysis capabilities of MLLMs. The experimental results demonstrate that existing T2I models are more effective at generating positive emotions than negative ones. Meanwhile, although MLLMs show a certain degree of effectiveness in distinguishing and recognizing human emotions, they fall short of human-level accuracy, particularly in fine-grained emotion analysis. The MEMO-Bench will be made publicly available to support further research in this area.
3DGCQA: A Quality Assessment Database for 3D AI-Generated Contents
Sep 12, 2024



Although 3D generated content (3DGC) offers advantages in reducing production costs and accelerating design timelines, its quality often falls short when compared to 3D professionally generated content. Common quality issues frequently affect 3DGC, highlighting the importance of timely and effective quality assessment. Such evaluations not only ensure a higher standard of 3DGCs for end-users but also provide critical insights for advancing generative technologies. To address existing gaps in this domain, this paper introduces a novel 3DGC quality assessment dataset, 3DGCQA, built using 7 representative Text-to-3D generation methods. During the dataset's construction, 50 fixed prompts are utilized to generate contents across all methods, resulting in the creation of 313 textured meshes that constitute the 3DGCQA dataset. The visualization intuitively reveals the presence of 6 common distortion categories in the generated 3DGCs. To further explore the quality of the 3DGCs, subjective quality assessment is conducted by evaluators, whose ratings reveal significant variation in quality across different generation methods. Additionally, several objective quality assessment algorithms are tested on the 3DGCQA dataset. The results expose limitations in the performance of existing algorithms and underscore the need for developing more specialized quality assessment methods. To provide a valuable resource for future research and development in 3D content generation and quality assessment, the dataset has been open-sourced in https://github.com/zyj-2000/3DGCQA.