 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Agent: Quality-Driven Chain-of-Thought Image Restoration Agent through Robust Multimodal Large Language Model
Apr 09, 2025Image restoration (IR) often faces various complex and unknown degradations in real-world scenarios, such as noise, blurring, compression artifacts, and low resolution, etc. Training specific models for specific degradation may lead to poor generalization. To handle multiple degradations simultaneously, All-in-One models might sacrifice performance on certain types of degradation and still struggle with unseen degradations during training. Existing IR agents rely on multimodal large language models (MLLM) and a time-consuming rolling-back selection strategy neglecting image quality. As a result, they may misinterpret degradations and have high time and computational costs to conduct unnecessary IR tasks with redundant order. To address these, we propose a Quality-Driven agent (Q-Agent) via Chain-of-Thought (CoT) restoration. Specifically, our Q-Agent consists of robust degradation perception and quality-driven greedy restoration. The former module first fine-tunes MLLM, and uses CoT to decompose multi-degradation perception into single-degradation perception tasks to enhance the perception of MLLMs. The latter employs objective image quality assessment (IQA) metrics to determine the optimal restoration sequence and execute the corresponding restoration algorithms. Experimental results demonstrate that our Q-Agent achieves superior IR performance compared to existing All-in-One models.
Ultrasound-QBench: Can LLMs Aid in Quality Assessment of Ultrasound Imaging?
Jan 06, 2025
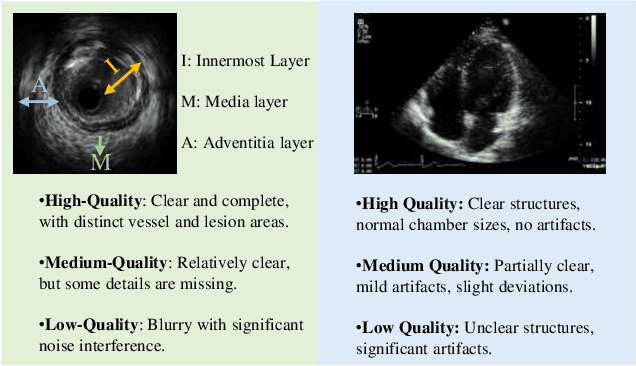


With the dramatic upsurge in the volume of ultrasound examinations, low-quality ultrasound imaging has gradually increased due to variations in operator proficiency and imaging circumstances, imposing a severe burden on diagnosis accuracy and even entailing the risk of restarting the diagnosis in critical cases. To assist clinicians in selecting high-quality ultrasound images and ensuring accurate diagnoses, we introduce Ultrasound-QBench, a comprehensive benchmark that systematically evaluates multimodal large language models (MLLMs) on quality assessment tasks of ultrasound images. Ultrasound-QBench establishes two datasets collected from diverse sources: IVUSQA, consisting of 7,709 images, and CardiacUltraQA, containing 3,863 images. These images encompassing common ultrasound imaging artifacts are annotated by professional ultrasound experts and classified into three quality levels: high, medium, and low. To better evaluate MLLMs, we decompose the quality assessment task into three dimensionalities: qualitative classification, quantitative scoring, and comparative assessment. The evaluation of 7 open-source MLLMs as well as 1 proprietary MLLMs demonstrates that MLLMs possess preliminary capabilities for low-level visual tasks in ultrasound image quality classification. We hope this benchmark will inspire the research community to delve deeper into uncovering and enhancing the untapped potential of MLLMs for medical imaging tasks.
MEMO-Bench: A Multiple Benchmark for Text-to-Image and Multimodal Large Language Models on Human Emotion Analysis
Nov 18, 2024



Artificial Intelligence (AI) has demonstrated significant capabilities in various fields, and in areas such as human-computer interaction (HCI), embodied intelligence, and the design and animation of virtual digital humans, both practitioners and users are increasingly concerned with AI's ability to understand and express emotion. Consequently, the question of whether AI can accurately interpret human emotions remains a critical challenge. To date, two primary classes of AI models have been involved in human emotion analysis: generative models and Multimodal Large Language Models (MLLMs). To assess the emotional capabilities of these two classes of models, this study introduces MEMO-Bench, a comprehensive benchmark consisting of 7,145 portraits, each depicting one of six different emotions, generated by 12 Text-to-Image (T2I) models. Unlike previous works, MEMO-Bench provides a framework for evaluating both T2I models and MLLMs in the context of sentiment analysis. Additionally, a progressive evaluation approach is employed, moving from coarse-grained to fine-grained metrics, to offer a more detailed and comprehensive assessment of the sentiment analysis capabilities of MLLMs. The experimental results demonstrate that existing T2I models are more effective at generating positive emotions than negative ones. Meanwhile, although MLLMs show a certain degree of effectiveness in distinguishing and recognizing human emotions, they fall short of human-level accuracy, particularly in fine-grained emotion analysis. The MEMO-Bench will be made publicly available to support further research in this area.
3DGCQA: A Quality Assessment Database for 3D AI-Generated Contents
Sep 12, 2024



Although 3D generated content (3DGC) offers advantages in reducing production costs and accelerating design timelines, its quality often falls short when compared to 3D professionally generated content. Common quality issues frequently affect 3DGC, highlighting the importance of timely and effective quality assessment. Such evaluations not only ensure a higher standard of 3DGCs for end-users but also provide critical insights for advancing generative technologies. To address existing gaps in this domain, this paper introduces a novel 3DGC quality assessment dataset, 3DGCQA, built using 7 representative Text-to-3D generation methods. During the dataset's construction, 50 fixed prompts are utilized to generate contents across all methods, resulting in the creation of 313 textured meshes that constitute the 3DGCQA dataset. The visualization intuitively reveals the presence of 6 common distortion categories in the generated 3DGCs. To further explore the quality of the 3DGCs, subjective quality assessment is conducted by evaluators, whose ratings reveal significant variation in quality across different generation methods. Additionally, several objective quality assessment algorithms are tested on the 3DGCQA dataset. The results expose limitations in the performance of existing algorithms and underscore the need for developing more specialized quality assessment methods. To provide a valuable resource for future research and development in 3D content generation and quality assessment, the dataset has been open-sourced in https://github.com/zyj-2000/3DGCQA.
Dual-Branch Network for Portrait Image Quality Assessment
May 14, 2024

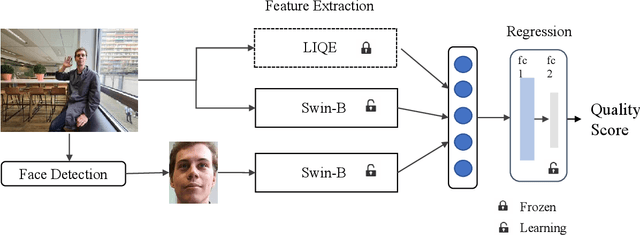
Portrait images typically consist of a salient person against diverse backgrounds. With the development of mobile devices and image processing techniques, users can conveniently capture portrait images anytime and anywhere. However, the quality of these portraits may suffer from the degradation caused by unfavorable environmental conditions, subpar photography techniques, and inferior capturing devices. In this paper, we introduce a dual-branch network for portrait image quality assessment (PIQA), which can effectively address how the salient person and the background of a portrait image influence its visual quality. Specifically, we utilize two backbone networks (\textit{i.e.,} Swin Transformer-B) to extract the quality-aware features from the entire portrait image and the facial image cropped from it. To enhance the quality-aware feature representation of the backbones, we pre-train them on the large-scale video quality assessment dataset LSVQ and the large-scale facial image quality assessment dataset GFIQA. Additionally, we leverage LIQE, an image scene classification and quality assessment model, to capture the quality-aware and scene-specific features as the auxiliary features. Finally, we concatenate these features and regress them into quality scores via a multi-perception layer (MLP). We employ the fidelity loss to train the model via a learning-to-rank manner to mitigate inconsistencies in quality scores in the portrait image quality assessment dataset PIQ. Experimental results demonstrate that the proposed model achieves superior performance in the PIQ dataset, validating its effectiveness. The code is available at \url{https://github.com/sunwei925/DN-PIQA.git}.
Large Multi-modality Model Assisted AI-Generated Image Quality Assessment
Apr 27, 2024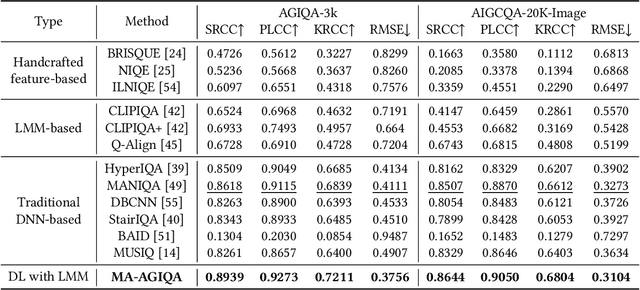

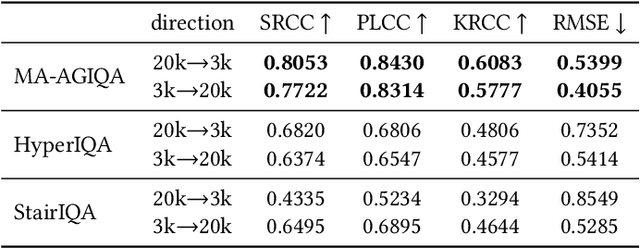

Traditional deep neural network (DNN)-based image quality assessment (IQA) models leverage convolutional neural networks (CNN) or Transformer to learn the quality-aware feature representation, achieving commendable performance on natural scene images. However, when applied to AI-Generated images (AGIs), these DNN-based IQA models exhibit subpar performance. This situation is largely due to the semantic inaccuracies inherent in certain AGIs caused by uncontrollable nature of the generation process. Thus, the capability to discern semantic content becomes crucial for assessing the quality of AGIs. Traditional DNN-based IQA models, constrained by limited parameter complexity and training data, struggle to capture complex fine-grained semantic features, making it challenging to grasp the existence and coherence of semantic content of the entire image. To address the shortfall in semantic content perception of current IQA models, we introduce a large Multi-modality model Assisted AI-Generated Image Quality Assessment (MA-AGIQA) model, which utilizes semantically informed guidance to sense semantic information and extract semantic vectors through carefully designed text prompts. Moreover, it employs a mixture of experts (MoE) structure to dynamically integrate the semantic information with the quality-aware features extracted by traditional DNN-based IQA models. Comprehensive experiments conducted on two AI-generated content datasets, AIGCQA-20k and AGIQA-3k show that MA-AGIQA achieves state-of-the-art performance, and demonstrate its superior generalization capabilities on assessing the quality of AGIs. Code is available at https://github.com/wangpuyi/MA-AGIQA.
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024



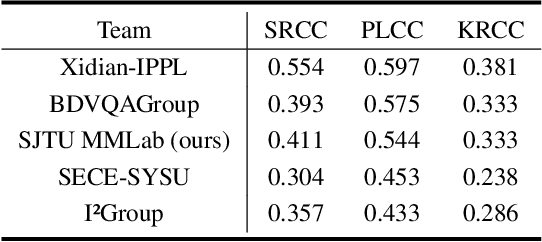
This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.