 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemMamba: Alignment-free Raw Video Demoireing with Frequency-assisted Spatio-Temporal Mamba
Aug 20, 2024



Moire patterns arise when two similar repetitive patterns interfere, a phenomenon frequently observed during the capture of images or videos on screens. The color, shape, and location of moire patterns may differ across video frames, posing a challenge in learning information from adjacent frames and preserving temporal consistency. Previous video demoireing methods heavily rely on well-designed alignment modules, resulting in substantial computational burdens. Recently, Mamba, an improved version of the State Space Model (SSM), has demonstrated significant potential for modeling long-range dependencies with linear complexity, enabling efficient temporal modeling in video demoireing without requiring a specific alignment module. In this paper, we propose a novel alignment-free Raw video demoireing network with frequency-assisted spatio-temporal Mamba (DemMamba). The Spatial Mamba Block (SMB) and Temporal Mamba Block (TMB) are sequentially arranged to facilitate effective intra- and inter-relationship modeling in Raw videos with moire patterns. Within SMB, an Adaptive Frequency Block (AFB) is introduced to aid demoireing in the frequency domain. For TMB, a Channel Attention Block (CAB) is embedded to further enhance temporal information interactions by exploiting the inter-channel relationships among features. Extensive experiments demonstrate that our proposed DemMamba surpasses state-of-the-art approaches by 1.3 dB and delivers a superior visual experience.
SG-JND: Semantic-Guided Just Noticeable Distortion Predictor For Image Compression
Aug 08, 2024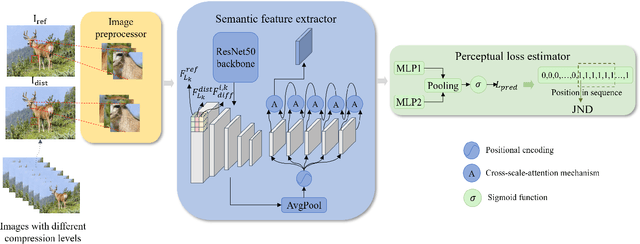
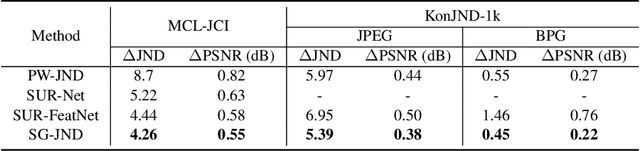
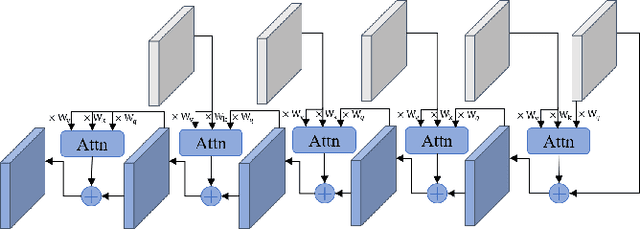

Just noticeable distortion (JND), representing the threshold of distortion in an image that is minimally perceptible to the human visual system (HVS), is crucial for image compression algorithms to achieve a trade-off between transmission bit rate and image quality. However, traditional JND prediction methods only rely on pixel-level or sub-band level features, lacking the ability to capture the impact of image content on JND. To bridge this gap, we propose a Semantic-Guided JND (SG-JND) network to leverage semantic information for JND prediction. In particular, SG-JND consists of three essential modules: the image preprocessing module extracts semantic-level patches from images, the feature extraction module extracts multi-layer features by utilizing the cross-scale attention layers, and the JND prediction module regresses the extracted features into the final JND value. Experimental results show that SG-JND achieves the state-of-the-art performance on two publicly available JND datasets, which demonstrates the effectiveness of SG-JND and highlight the significance of incorporating semantic information in JND assessment.
Enhancing Blind Video Quality Assessment with Rich Quality-aware Features
May 14, 2024



In this paper, we present a simple but effective method to enhance blind video quality assessment (BVQA) models for social media videos. Motivated by previous researches that leverage pre-trained features extracted from various computer vision models as the feature representation for BVQA, we further explore rich quality-aware features from pre-trained blind image quality assessment (BIQA) and BVQA models as auxiliary features to help the BVQA model to handle complex distortions and diverse content of social media videos. Specifically, we use SimpleVQA, a BVQA model that consists of a trainable Swin Transformer-B and a fixed SlowFast, as our base model. The Swin Transformer-B and SlowFast components are responsible for extracting spatial and motion features, respectively. Then, we extract three kinds of features from Q-Align, LIQE, and FAST-VQA to capture frame-level quality-aware features, frame-level quality-aware along with scene-specific features, and spatiotemporal quality-aware features, respectively. Through concatenating these features, we employ a multi-layer perceptron (MLP) network to regress them into quality scores. Experimental results demonstrate that the proposed model achieves the best performance on three public social media VQA datasets. Moreover, the proposed model won first place in the CVPR NTIRE 2024 Short-form UGC Video Quality Assessment Challenge. The code is available at \url{https://github.com/sunwei925/RQ-VQA.git}.
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024



This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.