 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSG-JND: Semantic-Guided Just Noticeable Distortion Predictor For Image Compression
Paper and Code
Aug 08, 2024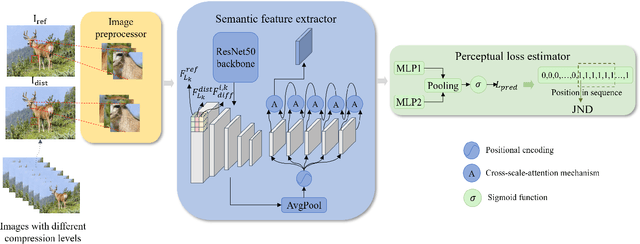
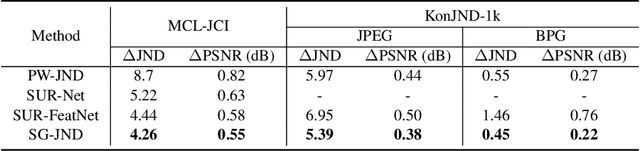
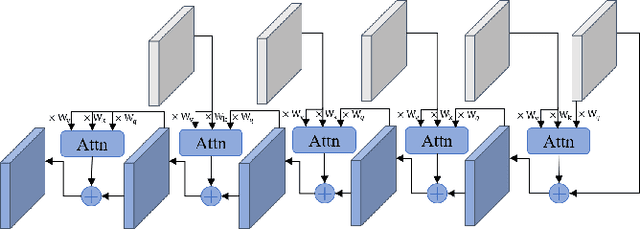

Just noticeable distortion (JND), representing the threshold of distortion in an image that is minimally perceptible to the human visual system (HVS), is crucial for image compression algorithms to achieve a trade-off between transmission bit rate and image quality. However, traditional JND prediction methods only rely on pixel-level or sub-band level features, lacking the ability to capture the impact of image content on JND. To bridge this gap, we propose a Semantic-Guided JND (SG-JND) network to leverage semantic information for JND prediction. In particular, SG-JND consists of three essential modules: the image preprocessing module extracts semantic-level patches from images, the feature extraction module extracts multi-layer features by utilizing the cross-scale attention layers, and the JND prediction module regresses the extracted features into the final JND value. Experimental results show that SG-JND achieves the state-of-the-art performance on two publicly available JND datasets, which demonstrates the effectiveness of SG-JND and highlight the significance of incorporating semantic information in JND assessment.