 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenPathNet: An Open-Source RF Multipath Data Generator for AI-Driven Wireless Systems
Dec 19, 2025The convergence of artificial intelligence (AI) and sixth-generation (6G) wireless technologies is driving an urgent need for large-scale, high-fidelity, and reproducible radio frequency (RF) datasets. Existing resources, such as CKMImageNet, primarily provide preprocessed and image-based channel representations, which conceal the fine-grained physical characteristics of signal propagation that are essential for effective AI modeling. To bridge this gap, we present OpenPathNet, an open-source RF multipath data generator accompanied by a publicly released dataset for AI-driven wireless research. Distinct from prior datasets, OpenPathNet offers disaggregated and physically consistent multipath parameters, including per-path gain, time of arrival (ToA), and spatial angles, derived from high-precision ray tracing simulations constructed on real-world environment maps. By adopting a modular, parameterized pipeline, OpenPathNet enables reproducible generation of multipath data and can be readily extended to new environments and configurations, improving scalability and transparency. The released generator and accompanying dataset provide an extensible testbed that holds promise for advancing studies on channel modeling, beam prediction, environment-aware communication, and integrated sensing in AI-enabled 6G systems. The source code and dataset are publicly available at https://github.com/liu-lz/OpenPathNet.
PINN and GNN-based RF Map Construction for Wireless Communication Systems
Jul 30, 2025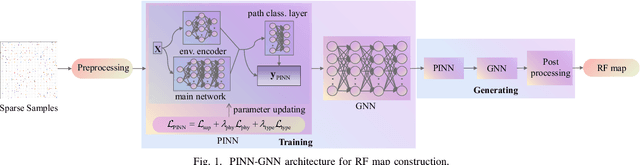
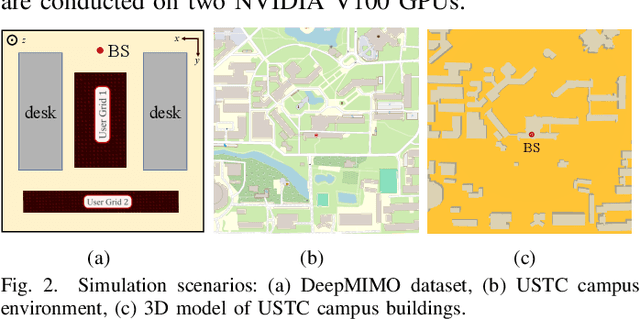
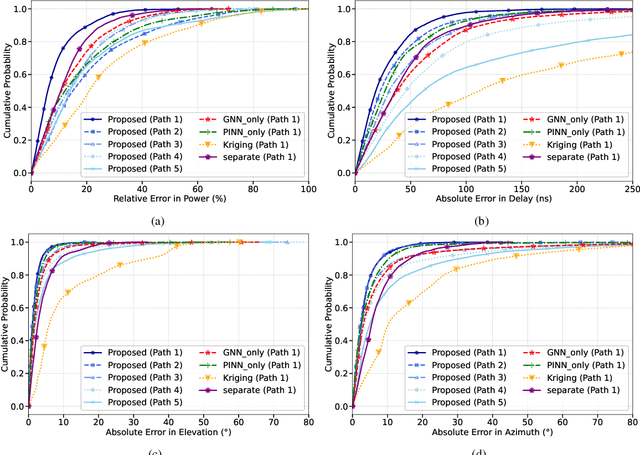
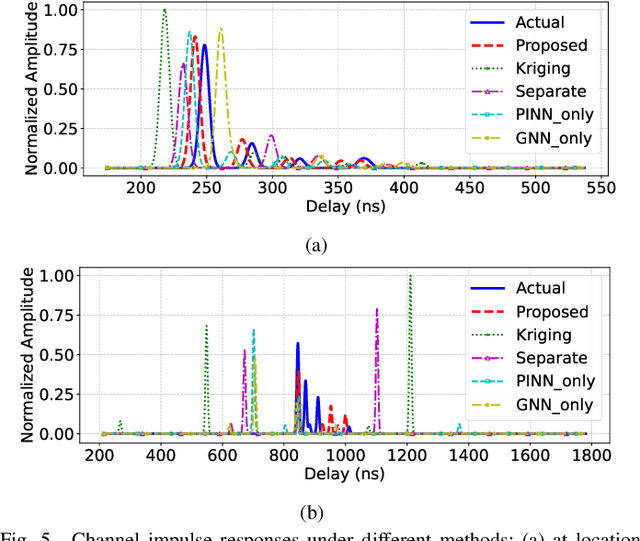
Radio frequency (RF) map is a promising technique for capturing the characteristics of multipath signal propagation, offering critical support for channel modeling, coverage analysis, and beamforming in wireless communication networks. This paper proposes a novel RF map construction method based on a combination of physics-informed neural network (PINN) and graph neural network (GNN). The PINN incorporates physical constraints derived from electromagnetic propagation laws to guide the learning process, while the GNN models spatial correlations among receiver locations. By parameterizing multipath signals into received power, delay, and angle of arrival (AoA), and integrating both physical priors and spatial dependencies, the proposed method achieves accurate prediction of multipath parameters. Experimental results demonstrate that the method enables high-precision RF map construction under sparse sampling conditions and delivers robust performance in both indoor and complex outdoor environments, outperforming baseline methods in terms of generalization and accuracy.
SG-JND: Semantic-Guided Just Noticeable Distortion Predictor For Image Compression
Aug 08, 2024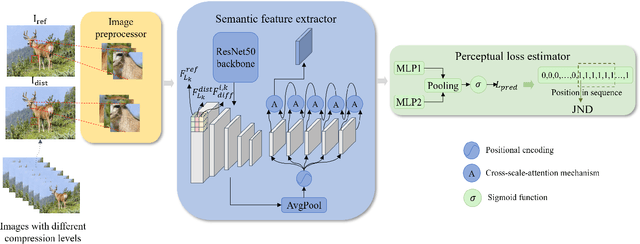
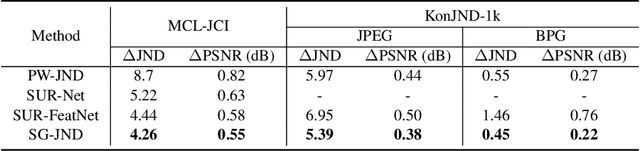
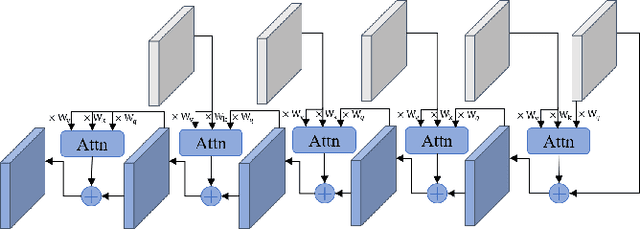

Just noticeable distortion (JND), representing the threshold of distortion in an image that is minimally perceptible to the human visual system (HVS), is crucial for image compression algorithms to achieve a trade-off between transmission bit rate and image quality. However, traditional JND prediction methods only rely on pixel-level or sub-band level features, lacking the ability to capture the impact of image content on JND. To bridge this gap, we propose a Semantic-Guided JND (SG-JND) network to leverage semantic information for JND prediction. In particular, SG-JND consists of three essential modules: the image preprocessing module extracts semantic-level patches from images, the feature extraction module extracts multi-layer features by utilizing the cross-scale attention layers, and the JND prediction module regresses the extracted features into the final JND value. Experimental results show that SG-JND achieves the state-of-the-art performance on two publicly available JND datasets, which demonstrates the effectiveness of SG-JND and highlight the significance of incorporating semantic information in JND assessment.