 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAPE-IR: Frequency-Aware Planning and Execution Framework for All-in-One Image Restoration
Nov 18, 2025All-in-One Image Restoration (AIO-IR) aims to develop a unified model that can handle multiple degradations under complex conditions. However, existing methods often rely on task-specific designs or latent routing strategies, making it hard to adapt to real-world scenarios with various degradations. We propose FAPE-IR, a Frequency-Aware Planning and Execution framework for image restoration. It uses a frozen Multimodal Large Language Model (MLLM) as a planner to analyze degraded images and generate concise, frequency-aware restoration plans. These plans guide a LoRA-based Mixture-of-Experts (LoRA-MoE) module within a diffusion-based executor, which dynamically selects high- or low-frequency experts, complemented by frequency features of the input image. To further improve restoration quality and reduce artifacts, we introduce adversarial training and a frequency regularization loss. By coupling semantic planning with frequency-based restoration, FAPE-IR offers a unified and interpretable solution for all-in-one image restoration. Extensive experiments show that FAPE-IR achieves state-of-the-art performance across seven restoration tasks and exhibits strong zero-shot generalization under mixed degradations.
DemMamba: Alignment-free Raw Video Demoireing with Frequency-assisted Spatio-Temporal Mamba
Aug 20, 2024



Moire patterns arise when two similar repetitive patterns interfere, a phenomenon frequently observed during the capture of images or videos on screens. The color, shape, and location of moire patterns may differ across video frames, posing a challenge in learning information from adjacent frames and preserving temporal consistency. Previous video demoireing methods heavily rely on well-designed alignment modules, resulting in substantial computational burdens. Recently, Mamba, an improved version of the State Space Model (SSM), has demonstrated significant potential for modeling long-range dependencies with linear complexity, enabling efficient temporal modeling in video demoireing without requiring a specific alignment module. In this paper, we propose a novel alignment-free Raw video demoireing network with frequency-assisted spatio-temporal Mamba (DemMamba). The Spatial Mamba Block (SMB) and Temporal Mamba Block (TMB) are sequentially arranged to facilitate effective intra- and inter-relationship modeling in Raw videos with moire patterns. Within SMB, an Adaptive Frequency Block (AFB) is introduced to aid demoireing in the frequency domain. For TMB, a Channel Attention Block (CAB) is embedded to further enhance temporal information interactions by exploiting the inter-channel relationships among features. Extensive experiments demonstrate that our proposed DemMamba surpasses state-of-the-art approaches by 1.3 dB and delivers a superior visual experience.
Image Demoireing in RAW and sRGB Domains
Dec 14, 2023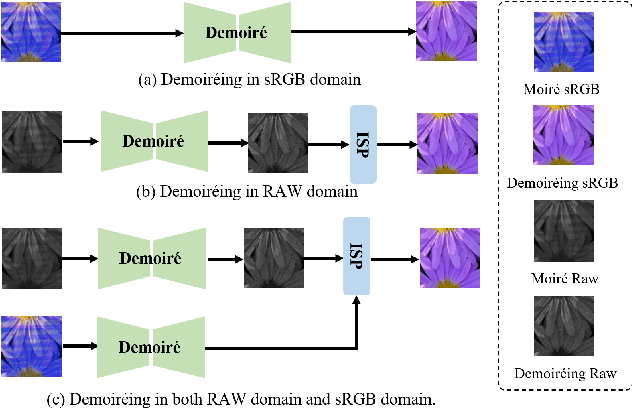

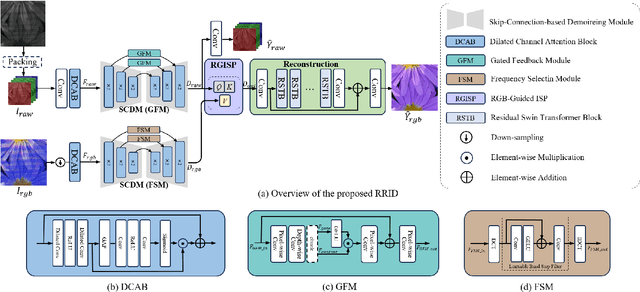
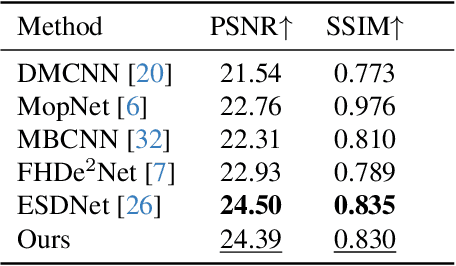
Moir\'e patterns frequently appear when capturing screens with smartphones or cameras, potentially compromising image quality. Previous studies suggest that moir\'e pattern elimination in the RAW domain offers greater efficiency compared to demoir\'eing in the sRGB domain. Nevertheless, relying solely on raw data for image demoir\'eing is insufficient in mitigating color cast due to the absence of essential information required for color correction by the Image Signal Processor (ISP). In this paper, we propose perform Image Demoir\'eing concurrently utilizing both RAW and sRGB data (RRID), which is readily accessible in both smartphones and digital cameras. We develop Skip-Connection-based Demoir\'eing Module (SCDM) with specific modules embeded in skip-connections for the efficient and effective demoir\'eing of RAW and sRGB features, respectively. Subsequently, we propose RGB Guided Image Signal Processor (RGISP) to incorporate color information from coarsely demoir\'ed sRGB features during the ISP stage, assisting the process of color recovery. Extensive experiments demonstrate that our RRID outperforms state-of-the-art approaches by 0.62dB in PSNR and 0.003 in SSIM, exhibiting superior performance both in moir\'e pattern removal and color cast correction.
CNN Injected Transformer for Image Exposure Correction
Sep 08, 2023



Capturing images with incorrect exposure settings fails to deliver a satisfactory visual experience. Only when the exposure is properly set, can the color and details of the images be appropriately preserved. Previous exposure correction methods based on convolutions often produce exposure deviation in images as a consequence of the restricted receptive field of convolutional kernels. This issue arises because convolutions are not capable of capturing long-range dependencies in images accurately. To overcome this challenge, we can apply the Transformer to address the exposure correction problem, leveraging its capability in modeling long-range dependencies to capture global representation. However, solely relying on the window-based Transformer leads to visually disturbing blocking artifacts due to the application of self-attention in small patches. In this paper, we propose a CNN Injected Transformer (CIT) to harness the individual strengths of CNN and Transformer simultaneously. Specifically, we construct the CIT by utilizing a window-based Transformer to exploit the long-range interactions among different regions in the entire image. Within each CIT block, we incorporate a channel attention block (CAB) and a half-instance normalization block (HINB) to assist the window-based self-attention to acquire the global statistics and refine local features. In addition to the hybrid architecture design for exposure correction, we apply a set of carefully formulated loss functions to improve the spatial coherence and rectify potential color deviations. Extensive experiments demonstrate that our image exposure correction method outperforms state-of-the-art approaches in terms of both quantitative and qualitative metrics.
Direction-aware Video Demoireing with Temporal-guided Bilateral Learning
Aug 25, 2023



Moire patterns occur when capturing images or videos on screens, severely degrading the quality of the captured images or videos. Despite the recent progresses, existing video demoireing methods neglect the physical characteristics and formation process of moire patterns, significantly limiting the effectiveness of video recovery. This paper presents a unified framework, DTNet, a direction-aware and temporal-guided bilateral learning network for video demoireing. DTNet effectively incorporates the process of moire pattern removal, alignment, color correction, and detail refinement. Our proposed DTNet comprises two primary stages: Frame-level Direction-aware Demoireing and Alignment (FDDA) and Tone and Detail Refinement (TDR). In FDDA, we employ multiple directional DCT modes to perform the moire pattern removal process in the frequency domain, effectively detecting the prominent moire edges. Then, the coarse and fine-grained alignment is applied on the demoired features for facilitating the utilization of neighboring information. In TDR, we propose a temporal-guided bilateral learning pipeline to mitigate the degradation of color and details caused by the moire patterns while preserving the restored frequency information in FDDA. Guided by the aligned temporal features from FDDA, the affine transformations for the recovery of the ultimate clean frames are learned in TDR. Extensive experiments demonstrate that our video demoireing method outperforms state-of-the-art approaches by 2.3 dB in PSNR, and also delivers a superior visual experience.
Under-Display Camera Image Restoration with Scattering Effect
Aug 08, 2023



The under-display camera (UDC) provides consumers with a full-screen visual experience without any obstruction due to notches or punched holes. However, the semi-transparent nature of the display inevitably introduces the severe degradation into UDC images. In this work, we address the UDC image restoration problem with the specific consideration of the scattering effect caused by the display. We explicitly model the scattering effect by treating the display as a piece of homogeneous scattering medium. With the physical model of the scattering effect, we improve the image formation pipeline for the image synthesis to construct a realistic UDC dataset with ground truths. To suppress the scattering effect for the eventual UDC image recovery, a two-branch restoration network is designed. More specifically, the scattering branch leverages global modeling capabilities of the channel-wise self-attention to estimate parameters of the scattering effect from degraded images. While the image branch exploits the local representation advantage of CNN to recover clear scenes, implicitly guided by the scattering branch. Extensive experiments are conducted on both real-world and synthesized data, demonstrating the superiority of the proposed method over the state-of-the-art UDC restoration techniques. The source code and dataset are available at \url{https://github.com/NamecantbeNULL/SRUDC}.