 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Image Quality Assessment Ability of LMMs via Retrieval-Augmented Generation
Jan 13, 2026Large Multimodal Models (LMMs) have recently shown remarkable promise in low-level visual perception tasks, particularly in Image Quality Assessment (IQA), demonstrating strong zero-shot capability. However, achieving state-of-the-art performance often requires computationally expensive fine-tuning methods, which aim to align the distribution of quality-related token in output with image quality levels. Inspired by recent training-free works for LMM, we introduce IQARAG, a novel, training-free framework that enhances LMMs' IQA ability. IQARAG leverages Retrieval-Augmented Generation (RAG) to retrieve some semantically similar but quality-variant reference images with corresponding Mean Opinion Scores (MOSs) for input image. These retrieved images and input image are integrated into a specific prompt. Retrieved images provide the LMM with a visual perception anchor for IQA task. IQARAG contains three key phases: Retrieval Feature Extraction, Image Retrieval, and Integration & Quality Score Generation. Extensive experiments across multiple diverse IQA datasets, including KADID, KonIQ, LIVE Challenge, and SPAQ, demonstrate that the proposed IQARAG effectively boosts the IQA performance of LMMs, offering a resource-efficient alternative to fine-tuning for quality assessment.
MDiffFR: Modality-Guided Diffusion Generation for Cold-start Items in Federated Recommendation
Dec 31, 2025Federated recommendations (FRs) provide personalized services while preserving user privacy by keeping user data on local clients, which has attracted significant attention in recent years. However, due to the strict privacy constraints inherent in FRs, access to user-item interaction data and user profiles across clients is highly restricted, making it difficult to learn globally effective representations for new (cold-start) items. Consequently, the item cold-start problem becomes even more challenging in FRs. Existing solutions typically predict embeddings for new items through the attribute-to-embedding mapping paradigm, which establishes a fixed one-to-one correspondence between item attributes and their embeddings. However, this one-to-one mapping paradigm often fails to model varying data distributions and tends to cause embedding misalignment, as verified by our empirical studies. To this end, we propose MDiffFR, a novel generation-based modality-guided diffusion method for cold-start items in FRs. In this framework, we employ a tailored diffusion model on the server to generate embeddings for new items, which are then distributed to clients for cold-start inference. To align item semantics, we deploy a pre-trained modality encoder to extract modality features as conditional signals to guide the reverse denoising process. Furthermore, our theoretical analysis verifies that the proposed method achieves stronger privacy guarantees compared to existing mapping-based approaches. Extensive experiments on four real datasets demonstrate that our method consistently outperforms all baselines in FRs.
CompressedVQA-HDR: Generalized Full-reference and No-reference Quality Assessment Models for Compressed High Dynamic Range Videos
Jul 16, 2025Video compression is a standard procedure applied to all videos to minimize storage and transmission demands while preserving visual quality as much as possible. Therefore, evaluating the visual quality of compressed videos is crucial for guiding the practical usage and further development of video compression algorithms. Although numerous compressed video quality assessment (VQA) methods have been proposed, they often lack the generalization capability needed to handle the increasing diversity of video types, particularly high dynamic range (HDR) content. In this paper, we introduce CompressedVQA-HDR, an effective VQA framework designed to address the challenges of HDR video quality assessment. Specifically, we adopt the Swin Transformer and SigLip 2 as the backbone networks for the proposed full-reference (FR) and no-reference (NR) VQA models, respectively. For the FR model, we compute deep structural and textural similarities between reference and distorted frames using intermediate-layer features extracted from the Swin Transformer as its quality-aware feature representation. For the NR model, we extract the global mean of the final-layer feature maps from SigLip 2 as its quality-aware representation. To mitigate the issue of limited HDR training data, we pre-train the FR model on a large-scale standard dynamic range (SDR) VQA dataset and fine-tune it on the HDRSDR-VQA dataset. For the NR model, we employ an iterative mixed-dataset training strategy across multiple compressed VQA datasets, followed by fine-tuning on the HDRSDR-VQA dataset. Experimental results show that our models achieve state-of-the-art performance compared to existing FR and NR VQA models. Moreover, CompressedVQA-HDR-FR won first place in the FR track of the Generalizable HDR & SDR Video Quality Measurement Grand Challenge at IEEE ICME 2025. The code is available at https://github.com/sunwei925/CompressedVQA-HDR.
LMME3DHF: Benchmarking and Evaluating Multimodal 3D Human Face Generation with LMMs
May 05, 2025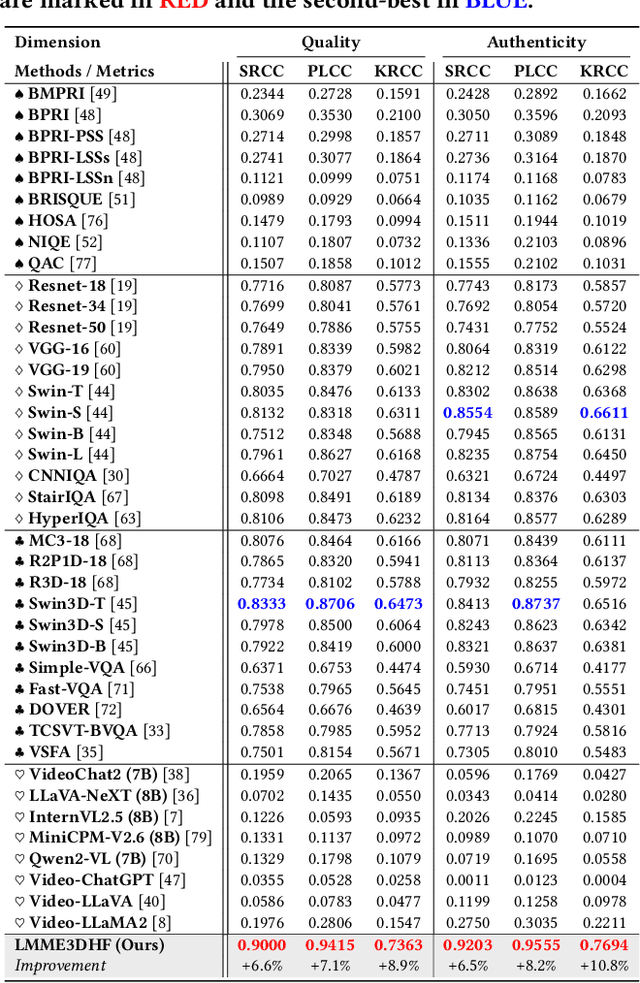
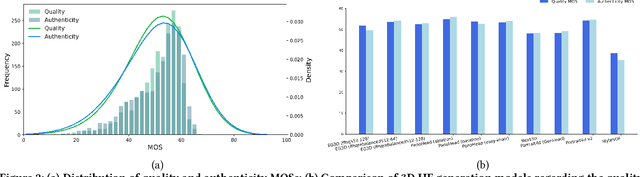

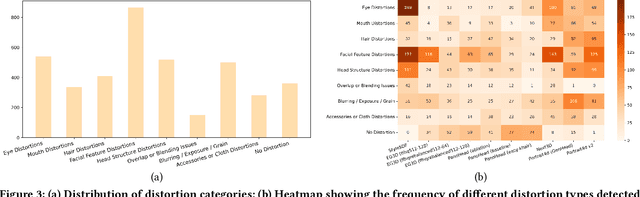
The rapid advancement in generative artificial intelligence have enabled the creation of 3D human faces (HFs) for applications including media production, virtual reality, security, healthcare, and game development, etc. However, assessing the quality and realism of these AI-generated 3D human faces remains a significant challenge due to the subjective nature of human perception and innate perceptual sensitivity to facial features. To this end, we conduct a comprehensive study on the quality assessment of AI-generated 3D human faces. We first introduce Gen3DHF, a large-scale benchmark comprising 2,000 videos of AI-Generated 3D Human Faces along with 4,000 Mean Opinion Scores (MOS) collected across two dimensions, i.e., quality and authenticity, 2,000 distortion-aware saliency maps and distortion descriptions. Based on Gen3DHF, we propose LMME3DHF, a Large Multimodal Model (LMM)-based metric for Evaluating 3DHF capable of quality and authenticity score prediction, distortion-aware visual question answering, and distortion-aware saliency prediction. Experimental results show that LMME3DHF achieves state-of-the-art performance, surpassing existing methods in both accurately predicting quality scores for AI-generated 3D human faces and effectively identifying distortion-aware salient regions and distortion types, while maintaining strong alignment with human perceptual judgments. Both the Gen3DHF database and the LMME3DHF will be released upon the publication.
LMM4Gen3DHF: Benchmarking and Evaluating Multimodal 3D Human Face Generation with LMMs
Apr 29, 2025The rapid advancement in generative artificial intelligence have enabled the creation of 3D human faces (HFs) for applications including media production, virtual reality, security, healthcare, and game development, etc. However, assessing the quality and realism of these AI-generated 3D human faces remains a significant challenge due to the subjective nature of human perception and innate perceptual sensitivity to facial features. To this end, we conduct a comprehensive study on the quality assessment of AI-generated 3D human faces. We first introduce Gen3DHF, a large-scale benchmark comprising 2,000 videos of AI-Generated 3D Human Faces along with 4,000 Mean Opinion Scores (MOS) collected across two dimensions, i.e., quality and authenticity, 2,000 distortion-aware saliency maps and distortion descriptions. Based on Gen3DHF, we propose LMME3DHF, a Large Multimodal Model (LMM)-based metric for Evaluating 3DHF capable of quality and authenticity score prediction, distortion-aware visual question answering, and distortion-aware saliency prediction. Experimental results show that LMME3DHF achieves state-of-the-art performance, surpassing existing methods in both accurately predicting quality scores for AI-generated 3D human faces and effectively identifying distortion-aware salient regions and distortion types, while maintaining strong alignment with human perceptual judgments. Both the Gen3DHF database and the LMME3DHF will be released upon the publication.
Multi-Dimensional Quality Assessment for Text-to-3D Assets: Dataset and Model
Feb 24, 2025Recent advancements in text-to-image (T2I) generation have spurred the development of text-to-3D asset (T23DA) generation, leveraging pretrained 2D text-to-image diffusion models for text-to-3D asset synthesis. Despite the growing popularity of text-to-3D asset generation, its evaluation has not been well considered and studied. However, given the significant quality discrepancies among various text-to-3D assets, there is a pressing need for quality assessment models aligned with human subjective judgments. To tackle this challenge, we conduct a comprehensive study to explore the T23DA quality assessment (T23DAQA) problem in this work from both subjective and objective perspectives. Given the absence of corresponding databases, we first establish the largest text-to-3D asset quality assessment database to date, termed the AIGC-T23DAQA database. This database encompasses 969 validated 3D assets generated from 170 prompts via 6 popular text-to-3D asset generation models, and corresponding subjective quality ratings for these assets from the perspectives of quality, authenticity, and text-asset correspondence, respectively. Subsequently, we establish a comprehensive benchmark based on the AIGC-T23DAQA database, and devise an effective T23DAQA model to evaluate the generated 3D assets from the aforementioned three perspectives, respectively.
Quality-guided Skin Tone Enhancement for Portrait Photography
Jun 22, 2024In recent years, learning-based color and tone enhancement methods for photos have become increasingly popular. However, most learning-based image enhancement methods just learn a mapping from one distribution to another based on one dataset, lacking the ability to adjust images continuously and controllably. It is important to enable the learning-based enhancement models to adjust an image continuously, since in many cases we may want to get a slighter or stronger enhancement effect rather than one fixed adjusted result. In this paper, we propose a quality-guided image enhancement paradigm that enables image enhancement models to learn the distribution of images with various quality ratings. By learning this distribution, image enhancement models can associate image features with their corresponding perceptual qualities, which can be used to adjust images continuously according to different quality scores. To validate the effectiveness of our proposed method, a subjective quality assessment experiment is first conducted, focusing on skin tone adjustment in portrait photography. Guided by the subjective quality ratings obtained from this experiment, our method can adjust the skin tone corresponding to different quality requirements. Furthermore, an experiment conducted on 10 natural raw images corroborates the effectiveness of our model in situations with fewer subjects and fewer shots, and also demonstrates its general applicability to natural images. Our project page is https://github.com/IntMeGroup/quality-guided-enhancement .
AttentionLut: Attention Fusion-based Canonical Polyadic LUT for Real-time Image Enhancement
Jan 03, 2024Recently, many algorithms have employed image-adaptive lookup tables (LUTs) to achieve real-time image enhancement. Nonetheless, a prevailing trend among existing methods has been the employment of linear combinations of basic LUTs to formulate image-adaptive LUTs, which limits the generalization ability of these methods. To address this limitation, we propose a novel framework named AttentionLut for real-time image enhancement, which utilizes the attention mechanism to generate image-adaptive LUTs. Our proposed framework consists of three lightweight modules. We begin by employing the global image context feature module to extract image-adaptive features. Subsequently, the attention fusion module integrates the image feature with the priori attention feature obtained during training to generate image-adaptive canonical polyadic tensors. Finally, the canonical polyadic reconstruction module is deployed to reconstruct image-adaptive residual 3DLUT, which is subsequently utilized for enhancing input images. Experiments on the benchmark MIT-Adobe FiveK dataset demonstrate that the proposed method achieves better enhancement performance quantitatively and qualitatively than the state-of-the-art methods.
RAWIW: RAW Image Watermarking Robust to ISP Pipeline
Jul 28, 2023Invisible image watermarking is essential for image copyright protection. Compared to RGB images, RAW format images use a higher dynamic range to capture the radiometric characteristics of the camera sensor, providing greater flexibility in post-processing and retouching. Similar to the master recording in the music industry, RAW images are considered the original format for distribution and image production, thus requiring copyright protection. Existing watermarking methods typically target RGB images, leaving a gap for RAW images. To address this issue, we propose the first deep learning-based RAW Image Watermarking (RAWIW) framework for copyright protection. Unlike RGB image watermarking, our method achieves cross-domain copyright protection. We directly embed copyright information into RAW images, which can be later extracted from the corresponding RGB images generated by different post-processing methods. To achieve end-to-end training of the framework, we integrate a neural network that simulates the ISP pipeline to handle the RAW-to-RGB conversion process. To further validate the generalization of our framework to traditional ISP pipelines and its robustness to transmission distortion, we adopt a distortion network. This network simulates various types of noises introduced during the traditional ISP pipeline and transmission. Furthermore, we employ a three-stage training strategy to strike a balance between robustness and concealment of watermarking. Our extensive experiments demonstrate that RAWIW successfully achieves cross-domain copyright protection for RAW images while maintaining their visual quality and robustness to ISP pipeline distortions.