 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-Guided Debiasing for No-Reference Enhancement Image Quality Assessment
Mar 20, 2026Current no-reference image quality assessment (NR-IQA) models for enhanced images often struggle to generalize, as they tend to overfit to the distinct patterns of specific enhancement algorithms rather than evaluating genuine perceptual quality. To address this issue, we propose a preference-guided debiasing framework for no-reference enhancement image quality assessment (EIQA). Specifically, we first learn a continuous enhancement-preference embedding space using supervised contrastive learning, where images generated by similar enhancement styles are encouraged to have closer representations. Based on this, we further estimate the enhancement-induced nuisance component contained in the raw quality representation and remove it before quality regression. In this way, the model is guided to focus on algorithm-invariant perceptual quality cues instead of enhancement-specific visual fingerprints. To facilitate stable optimization, we adopt a two-stage training strategy that first learns the enhancement-preference space and then performs debiased quality prediction. Extensive experiments on public EIQA benchmarks demonstrate that the proposed method effectively mitigates algorithm-induced representation bias and achieves superior robustness and cross-algorithm generalization compared with existing approaches.
Evaluating Image Editing with LLMs: A Comprehensive Benchmark and Intermediate-Layer Probing Approach
Mar 20, 2026Evaluating text-guided image editing (TIE) methods remains a challenging problem, as reliable assessment should simultaneously consider perceptual quality, alignment with textual instructions, and preservation of original image content. Despite rapid progress in TIE models, existing evaluation benchmarks remain limited in scale and often show weak correlation with human perceptual judgments. In this work, we introduce TIEdit, a benchmark for systematic evaluation of text-guided image editing methods. TIEdit consists of 512 source images paired with editing prompts across eight representative editing tasks, producing 5,120 edited images generated by ten state-of-the-art TIE models. To obtain reliable subjective ratings, 20 experts are recruited to produce 307,200 raw subjective ratings, which accumulates into 15,360 mean opinion scores (MOSs) across three evaluation dimensions: perceptual quality, editing alignment, and content preservation. Beyond the benchmark itself, we further propose EditProbe, an LLM-based evaluator that estimates editing quality via intermediate-layer probing of hidden representations. Instead of relying solely on final model outputs, EditProbe extracts informative representations from intermediate layers of multimodal large language models to better capture semantic and perceptual relationships between source images, editing instructions, and edited results. Experimental results demonstrate that widely used automatic evaluation metrics show limited correlation with human judgments on editing tasks, while EditProbe achieves substantially stronger alignment with human perception. Together, TIEdit and EditProbe provide a foundation for more reliable and perceptually aligned evaluation of text-guided image editing methods.
Fine-Tuned LLMs Know They Don't Know: A Parameter-Efficient Approach to Recovering Honesty
Nov 17, 2025The honesty of Large Language Models (LLMs) is increasingly important for safe deployment in high-stakes domains. However, this crucial trait is severely undermined by supervised fine-tuning (SFT), a common technique for model specialization. Existing recovery methods rely on data-intensive global parameter adjustments, implicitly assuming that SFT deeply corrupts the models' ability to recognize their knowledge boundaries. However, we observe that fine-tuned LLMs still preserve this ability; what is damaged is their capacity to faithfully express that awareness. Building on this, we propose Honesty-Critical Neurons Restoration (HCNR) to surgically repair this suppressed capacity. HCNR identifies and restores key expression-governing neurons to their pre-trained state while harmonizing them with task-oriented neurons via Hessian-guided compensation. Experiments on four QA tasks and five LLM families demonstrate that HCNR effectively recovers 33.25% of the compromised honesty while achieving at least 2.23x speedup with over 10x less data compared to baseline methods, offering a practical solution for trustworthy LLM deployment.
Towards Objective Fine-tuning: How LLMs' Prior Knowledge Causes Potential Poor Calibration?
May 27, 2025Fine-tuned Large Language Models (LLMs) often demonstrate poor calibration, with their confidence scores misaligned with actual performance. While calibration has been extensively studied in models trained from scratch, the impact of LLMs' prior knowledge on calibration during fine-tuning remains understudied. Our research reveals that LLMs' prior knowledge causes potential poor calibration due to the ubiquitous presence of known data in real-world fine-tuning, which appears harmful for calibration. Specifically, data aligned with LLMs' prior knowledge would induce overconfidence, while new knowledge improves calibration. Our findings expose a tension: LLMs' encyclopedic knowledge, while enabling task versatility, undermines calibration through unavoidable knowledge overlaps. To address this, we propose CogCalib, a cognition-aware framework that applies targeted learning strategies according to the model's prior knowledge. Experiments across 7 tasks using 3 LLM families prove that CogCalib significantly improves calibration while maintaining performance, achieving an average 57\% reduction in ECE compared to standard fine-tuning in Llama3-8B. These improvements generalize well to out-of-domain tasks, enhancing the objectivity and reliability of domain-specific LLMs, and making them more trustworthy for critical human-AI interaction applications.
Dual Defense: Enhancing Privacy and Mitigating Poisoning Attacks in Federated Learning
Feb 08, 2025Federated learning (FL) is inherently susceptible to privacy breaches and poisoning attacks. To tackle these challenges, researchers have separately devised secure aggregation mechanisms to protect data privacy and robust aggregation methods that withstand poisoning attacks. However, simultaneously addressing both concerns is challenging; secure aggregation facilitates poisoning attacks as most anomaly detection techniques require access to unencrypted local model updates, which are obscured by secure aggregation. Few recent efforts to simultaneously tackle both challenges offen depend on impractical assumption of non-colluding two-server setups that disrupt FL's topology, or three-party computation which introduces scalability issues, complicating deployment and application. To overcome this dilemma, this paper introduce a Dual Defense Federated learning (DDFed) framework. DDFed simultaneously boosts privacy protection and mitigates poisoning attacks, without introducing new participant roles or disrupting the existing FL topology. DDFed initially leverages cutting-edge fully homomorphic encryption (FHE) to securely aggregate model updates, without the impractical requirement for non-colluding two-server setups and ensures strong privacy protection. Additionally, we proposes a unique two-phase anomaly detection mechanism for encrypted model updates, featuring secure similarity computation and feedback-driven collaborative selection, with additional measures to prevent potential privacy breaches from Byzantine clients incorporated into the detection process. We conducted extensive experiments on various model poisoning attacks and FL scenarios, including both cross-device and cross-silo FL. Experiments on publicly available datasets demonstrate that DDFed successfully protects model privacy and effectively defends against model poisoning threats.
Beyond Human Preferences: Exploring Reinforcement Learning Trajectory Evaluation and Improvement through LLMs
Jun 28, 2024



Reinforcement learning (RL) faces challenges in evaluating policy trajectories within intricate game tasks due to the difficulty in designing comprehensive and precise reward functions. This inherent difficulty curtails the broader application of RL within game environments characterized by diverse constraints. Preference-based reinforcement learning (PbRL) presents a pioneering framework that capitalizes on human preferences as pivotal reward signals, thereby circumventing the need for meticulous reward engineering. However, obtaining preference data from human experts is costly and inefficient, especially under conditions marked by complex constraints. To tackle this challenge, we propose a LLM-enabled automatic preference generation framework named LLM4PG , which harnesses the capabilities of large language models (LLMs) to abstract trajectories, rank preferences, and reconstruct reward functions to optimize conditioned policies. Experiments on tasks with complex language constraints demonstrated the effectiveness of our LLM-enabled reward functions, accelerating RL convergence and overcoming stagnation caused by slow or absent progress under original reward structures. This approach mitigates the reliance on specialized human knowledge and demonstrates the potential of LLMs to enhance RL's effectiveness in complex environments in the wild.
Quality-guided Skin Tone Enhancement for Portrait Photography
Jun 22, 2024In recent years, learning-based color and tone enhancement methods for photos have become increasingly popular. However, most learning-based image enhancement methods just learn a mapping from one distribution to another based on one dataset, lacking the ability to adjust images continuously and controllably. It is important to enable the learning-based enhancement models to adjust an image continuously, since in many cases we may want to get a slighter or stronger enhancement effect rather than one fixed adjusted result. In this paper, we propose a quality-guided image enhancement paradigm that enables image enhancement models to learn the distribution of images with various quality ratings. By learning this distribution, image enhancement models can associate image features with their corresponding perceptual qualities, which can be used to adjust images continuously according to different quality scores. To validate the effectiveness of our proposed method, a subjective quality assessment experiment is first conducted, focusing on skin tone adjustment in portrait photography. Guided by the subjective quality ratings obtained from this experiment, our method can adjust the skin tone corresponding to different quality requirements. Furthermore, an experiment conducted on 10 natural raw images corroborates the effectiveness of our model in situations with fewer subjects and fewer shots, and also demonstrates its general applicability to natural images. Our project page is https://github.com/IntMeGroup/quality-guided-enhancement .
MIKO: Multimodal Intention Knowledge Distillation from Large Language Models for Social-Media Commonsense Discovery
Feb 29, 2024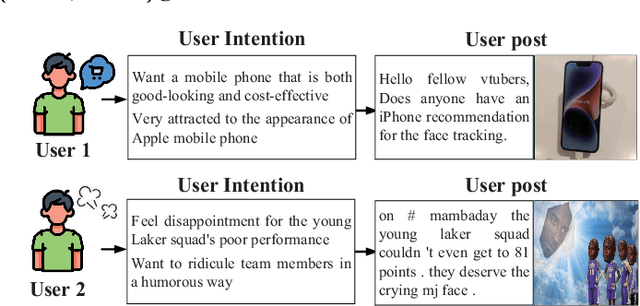

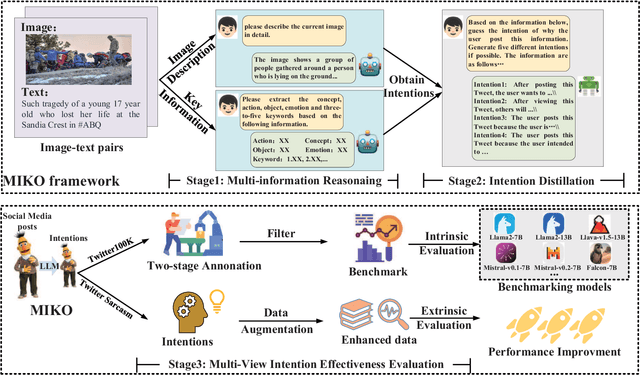

Social media has become a ubiquitous tool for connecting with others, staying updated with news, expressing opinions, and finding entertainment. However, understanding the intention behind social media posts remains challenging due to the implicitness of intentions in social media posts, the need for cross-modality understanding of both text and images, and the presence of noisy information such as hashtags, misspelled words, and complicated abbreviations. To address these challenges, we present MIKO, a Multimodal Intention Kowledge DistillatiOn framework that collaboratively leverages a Large Language Model (LLM) and a Multimodal Large Language Model (MLLM) to uncover users' intentions. Specifically, we use an MLLM to interpret the image and an LLM to extract key information from the text and finally instruct the LLM again to generate intentions. By applying MIKO to publicly available social media datasets, we construct an intention knowledge base featuring 1,372K intentions rooted in 137,287 posts. We conduct a two-stage annotation to verify the quality of the generated knowledge and benchmark the performance of widely used LLMs for intention generation. We further apply MIKO to a sarcasm detection dataset and distill a student model to demonstrate the downstream benefits of applying intention knowledge.
SSGD: A safe and efficient method of gradient descent
Dec 03, 2020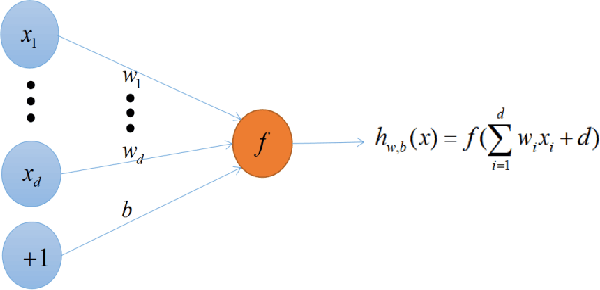

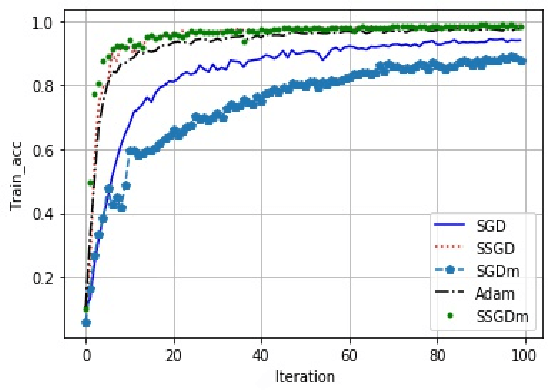
With the vigorous development of artificial intelligence technology, various engineering technology applications have been implemented one after another. The gradient descent method plays an important role in solving various optimization problems, due to its simple structure, good stability and easy implementation. In multi-node machine learning system, the gradients usually need to be shared. Data reconstruction attacks can reconstruct training data simply by knowing the gradient information. In this paper, to prevent gradient leakage while keeping the accuracy of model, we propose the super stochastic gradient descent approach to update parameters by concealing the modulus length of gradient vectors and converting it or them into a unit vector. Furthermore, we analyze the security of stochastic gradient descent approach. Experiment results show that our approach is obviously superior to prevalent gradient descent approaches in terms of accuracy and robustness.
Building a Computer Mahjong Player via Deep Convolutional Neural Networks
Jun 07, 2019
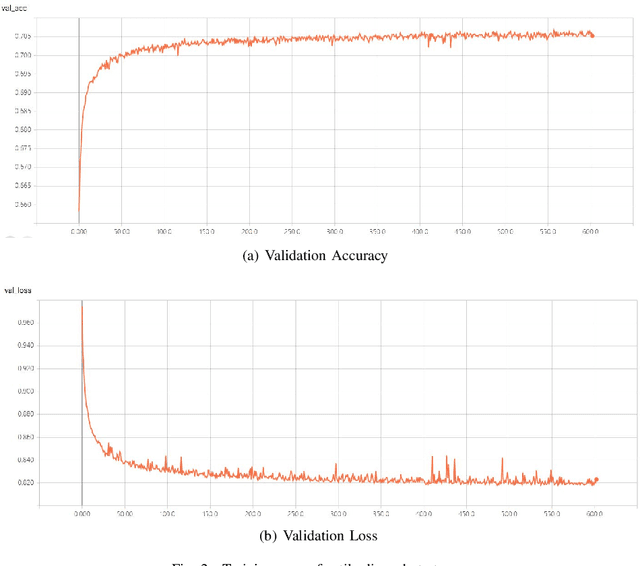


The evaluation function for imperfect information games is always hard to define but owns a significant impact on the playing strength of a program. Deep learning has made great achievements these years, and already exceeded the top human players' level even in the game of Go. In this paper, we introduce a new data model to represent the available imperfect information on the game table, and construct a well-designed convolutional neural network for game record training. We choose the accuracy of tile discarding which is also called as the agreement rate as the benchmark for this study. Our accuracy on test data reaches 70.44%, while the state-of-art baseline is 62.1% reported by Mizukami and Tsuruoka (2015), and is significantly higher than previous trials using deep learning, which shows the promising potential of our new model. For the AI program building, besides the tile discarding strategy, we adopt similar predicting strategies for other actions such as stealing (pon, chi, and kan) and riichi. With the simple combination of these several predicting networks and without any knowledge about the concrete rules of the game, a strength evaluation is made for the resulting program on the largest Japanese Mahjong site `Tenhou'. The program has achieved a rating of around 1850, which is significantly higher than that of an average human player and of programs among past studies.