 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeoAMT: Neologism-Aware Agentic Machine Translation with Reinforcement Learning
Jan 07, 2026Neologism-aware machine translation aims to translate source sentences containing neologisms into target languages. This field remains underexplored compared with general machine translation (MT). In this paper, we propose an agentic framework, NeoAMT, for neologism-aware machine translation using a Wiktionary search tool. Specifically, we first create a new dataset for neologism-aware machine translation and develop a search tool based on Wiktionary. The new dataset covers 16 languages and 75 translation directions and is derived from approximately 10 million records of an English Wiktionary dump. The retrieval corpus of the search tool is also constructed from around 3 million cleaned records of the Wiktionary dump. We then use it for training the translation agent with reinforcement learning (RL) and evaluating the accuracy of neologism-aware machine translation. Based on this, we also propose an RL training framework that contains a novel reward design and an adaptive rollout generation approach by leveraging "translation difficulty" to further improve the translation quality of translation agents using our search tool.
Improving Multimodal Contrastive Learning of Sentence Embeddings with Object-Phrase Alignment
Aug 01, 2025Multimodal sentence embedding models typically leverage image-caption pairs in addition to textual data during training. However, such pairs often contain noise, including redundant or irrelevant information on either the image or caption side. To mitigate this issue, we propose MCSEO, a method that enhances multimodal sentence embeddings by incorporating fine-grained object-phrase alignment alongside traditional image-caption alignment. Specifically, MCSEO utilizes existing segmentation and object detection models to extract accurate object-phrase pairs, which are then used to optimize a contrastive learning objective tailored to object-phrase correspondence. Experimental results on semantic textual similarity (STS) tasks across different backbone models demonstrate that MCSEO consistently outperforms strong baselines, highlighting the significance of precise object-phrase alignment in multimodal representation learning.
Direct Quantized Training of Language Models with Stochastic Rounding
Dec 06, 2024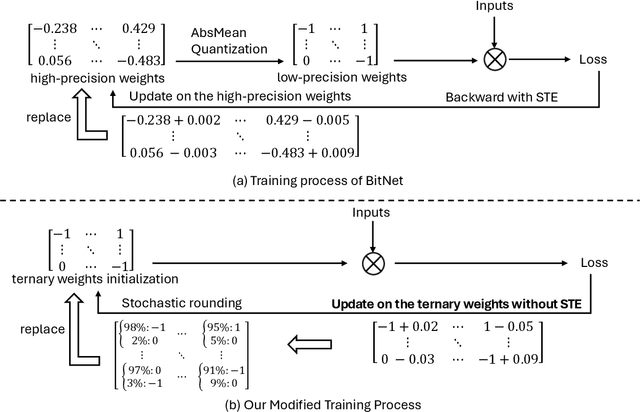
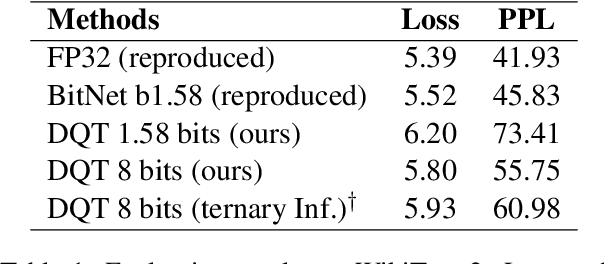
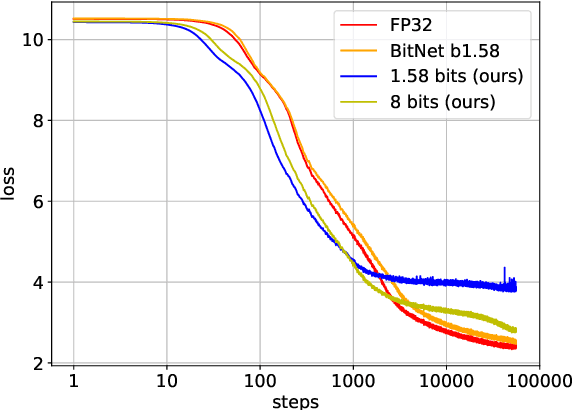
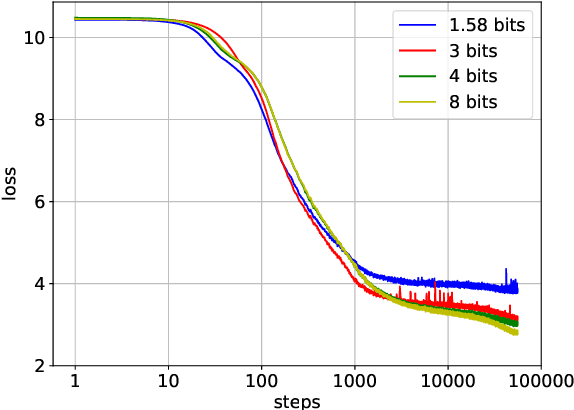
Although recent quantized Large Language Models (LLMs), such as BitNet, have paved the way for significant reduction in memory usage during deployment with binary or ternary weights, training these models still demands substantial memory footprints. This is partly because high-precision (i.e., unquantized) weight matrices required for straight-through estimation must be maintained throughout the whole training process. To address this, we explore the potential of directly updating the quantized low-precision weight matrices without relying on the straight-through estimator during backpropagation, thereby saving memory usage during training. Specifically, we employ a stochastic rounding technique to minimize information loss caused by the use of low-bit weights throughout training. Experimental results on our LLaMA-structured models indicate that (1) training with only low-precision weights is feasible even when they are constrained to ternary values, (2) extending the bit width to 8 bits results in only a 5% loss degradation compared to BitNet b1.58 while offering the potential for reduced memory usage during training, and (3) our models can also perform inference using ternary weights, showcasing their flexibility in deployment.
M2M-Gen: A Multimodal Framework for Automated Background Music Generation in Japanese Manga Using Large Language Models
Oct 13, 2024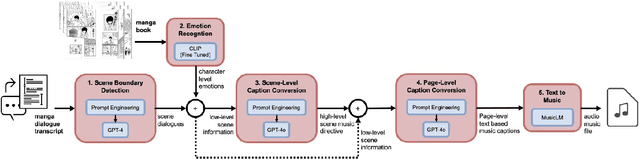

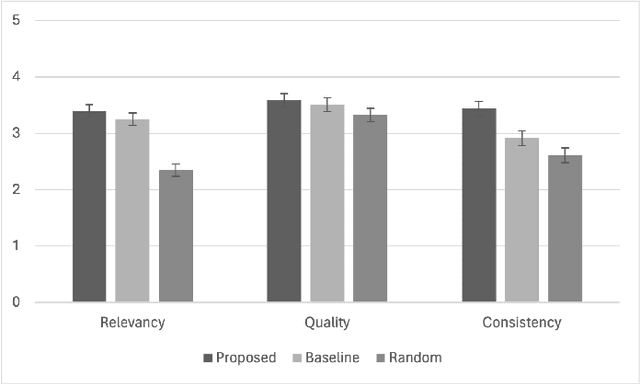
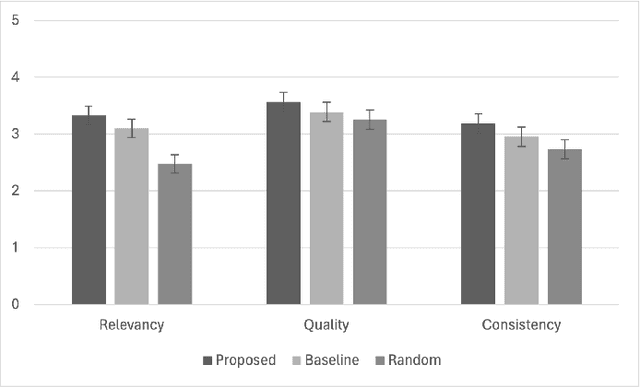
This paper introduces M2M Gen, a multi modal framework for generating background music tailored to Japanese manga. The key challenges in this task are the lack of an available dataset or a baseline. To address these challenges, we propose an automated music generation pipeline that produces background music for an input manga book. Initially, we use the dialogues in a manga to detect scene boundaries and perform emotion classification using the characters faces within a scene. Then, we use GPT4o to translate this low level scene information into a high level music directive. Conditioned on the scene information and the music directive, another instance of GPT 4o generates page level music captions to guide a text to music model. This produces music that is aligned with the mangas evolving narrative. The effectiveness of M2M Gen is confirmed through extensive subjective evaluations, showcasing its capability to generate higher quality, more relevant and consistent music that complements specific scenes when compared to our baselines.
Cross-Domain Policy Transfer by Representation Alignment via Multi-Domain Behavioral Cloning
Jul 24, 2024



Transferring learned skills across diverse situations remains a fundamental challenge for autonomous agents, particularly when agents are not allowed to interact with an exact target setup. While prior approaches have predominantly focused on learning domain translation, they often struggle with handling significant domain gaps or out-of-distribution tasks. In this paper, we present a simple approach for cross-domain policy transfer that learns a shared latent representation across domains and a common abstract policy on top of it. Our approach leverages multi-domain behavioral cloning on unaligned trajectories of proxy tasks and employs maximum mean discrepancy (MMD) as a regularization term to encourage cross-domain alignment. The MMD regularization better preserves structures of latent state distributions than commonly used domain-discriminative distribution matching, leading to higher transfer performance. Moreover, our approach involves training only one multi-domain policy, which makes extension easier than existing methods. Empirical evaluations demonstrate the efficacy of our method across various domain shifts, especially in scenarios where exact domain translation is challenging, such as cross-morphology or cross-viewpoint settings. Our ablation studies further reveal that multi-domain behavioral cloning implicitly contributes to representation alignment alongside domain-adversarial regularization.
Improving Arithmetic Reasoning Ability of Large Language Models through Relation Tuples, Verification and Dynamic Feedback
Jun 25, 2024



Current representations used in reasoning steps of large language models can mostly be categorized into two main types: (1) natural language, which is difficult to verify; and (2) non-natural language, usually programming code, which is difficult for people who are unfamiliar with coding to read. In this paper, we propose to use a semi-structured form to represent reasoning steps of large language models. Specifically, we use relation tuples, which are not only human-readable but also machine-friendly and easier to verify than natural language. We implement a framework that includes three main components: (1) introducing relation tuples into the reasoning steps of large language models; (2) implementing an automatic verification process of reasoning steps with a local code interpreter based on relation tuples; and (3) integrating a simple and effective dynamic feedback mechanism, which we found helpful for self-improvement of large language models. The experimental results on various arithmetic datasets demonstrate the effectiveness of our method in improving the arithmetic reasoning ability of large language models. The source code is available at https://github.com/gpgg/art.
Which Experiences Are Influential for RL Agents? Efficiently Estimating The Influence of Experiences
May 23, 2024



In reinforcement learning (RL) with experience replay, experiences stored in a replay buffer influence the RL agent's performance. Information about the influence of these experiences is valuable for various purposes, such as identifying experiences that negatively influence poorly performing RL agents. One method for estimating the influence of experiences is the leave-one-out (LOO) method. However, this method is usually computationally prohibitive. In this paper, we present Policy Iteration with Turn-over Dropout (PIToD), which efficiently estimates the influence of experiences. We evaluate how accurately PIToD estimates the influence of experiences and its efficiency compared to LOO. We then apply PIToD to amend poorly performing RL agents, i.e., we use PIToD to estimate negatively influential experiences for the RL agents and to delete the influence of these experiences. We show that RL agents' performance is significantly improved via amendments with PIToD.
Word Alignment as Preference for Machine Translation
May 15, 2024The problem of hallucination and omission, a long-standing problem in machine translation (MT), is more pronounced when a large language model (LLM) is used in MT because an LLM itself is susceptible to these phenomena. In this work, we mitigate the problem in an LLM-based MT model by guiding it to better word alignment. We first study the correlation between word alignment and the phenomena of hallucination and omission in MT. Then we propose to utilize word alignment as preference to optimize the LLM-based MT model. The preference data are constructed by selecting chosen and rejected translations from multiple MT tools. Subsequently, direct preference optimization is used to optimize the LLM-based model towards the preference signal. Given the absence of evaluators specifically designed for hallucination and omission in MT, we further propose selecting hard instances and utilizing GPT-4 to directly evaluate the performance of the models in mitigating these issues. We verify the rationality of these designed evaluation methods by experiments, followed by extensive results demonstrating the effectiveness of word alignment-based preference optimization to mitigate hallucination and omission.
Enhancing Cross-lingual Sentence Embedding for Low-resource Languages with Word Alignment
Apr 03, 2024The field of cross-lingual sentence embeddings has recently experienced significant advancements, but research concerning low-resource languages has lagged due to the scarcity of parallel corpora. This paper shows that cross-lingual word representation in low-resource languages is notably under-aligned with that in high-resource languages in current models. To address this, we introduce a novel framework that explicitly aligns words between English and eight low-resource languages, utilizing off-the-shelf word alignment models. This framework incorporates three primary training objectives: aligned word prediction and word translation ranking, along with the widely used translation ranking. We evaluate our approach through experiments on the bitext retrieval task, which demonstrate substantial improvements on sentence embeddings in low-resource languages. In addition, the competitive performance of the proposed model across a broader range of tasks in high-resource languages underscores its practicality.
Leveraging Multi-lingual Positive Instances in Contrastive Learning to Improve Sentence Embedding
Sep 16, 2023Learning multi-lingual sentence embeddings is a fundamental and significant task in natural language processing. Recent trends of learning both mono-lingual and multi-lingual sentence embeddings are mainly based on contrastive learning (CL) with an anchor, one positive, and multiple negative instances. In this work, we argue that leveraging multiple positives should be considered for multi-lingual sentence embeddings because (1) positives in a diverse set of languages can benefit cross-lingual learning, and (2) transitive similarity across multiple positives can provide reliable structural information to learn. In order to investigate the impact of CL with multiple positives, we propose a novel approach MPCL to effectively utilize multiple positive instances to improve learning multi-lingual sentence embeddings. Our experimental results on various backbone models and downstream tasks support that compared with conventional CL, MPCL leads to better retrieval, semantic similarity, and classification performances. We also observe that on unseen languages, sentence embedding models trained on multiple positives have better cross-lingual transferring performance than models trained on a single positive instance.