 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Policy Transfer by Representation Alignment via Multi-Domain Behavioral Cloning
Jul 24, 2024



Transferring learned skills across diverse situations remains a fundamental challenge for autonomous agents, particularly when agents are not allowed to interact with an exact target setup. While prior approaches have predominantly focused on learning domain translation, they often struggle with handling significant domain gaps or out-of-distribution tasks. In this paper, we present a simple approach for cross-domain policy transfer that learns a shared latent representation across domains and a common abstract policy on top of it. Our approach leverages multi-domain behavioral cloning on unaligned trajectories of proxy tasks and employs maximum mean discrepancy (MMD) as a regularization term to encourage cross-domain alignment. The MMD regularization better preserves structures of latent state distributions than commonly used domain-discriminative distribution matching, leading to higher transfer performance. Moreover, our approach involves training only one multi-domain policy, which makes extension easier than existing methods. Empirical evaluations demonstrate the efficacy of our method across various domain shifts, especially in scenarios where exact domain translation is challenging, such as cross-morphology or cross-viewpoint settings. Our ablation studies further reveal that multi-domain behavioral cloning implicitly contributes to representation alignment alongside domain-adversarial regularization.
Reconnaissance and Planning algorithm for constrained MDP
Sep 20, 2019
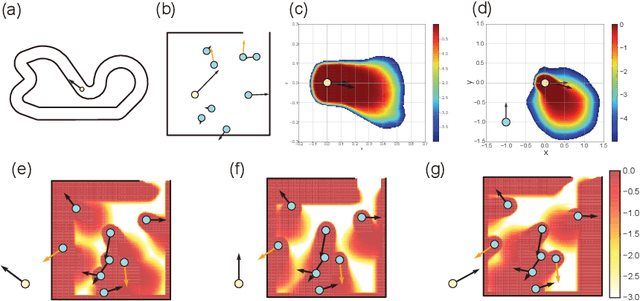

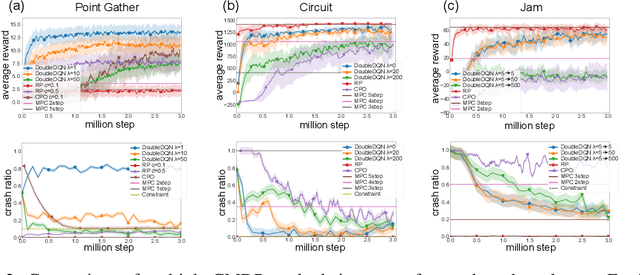
Practical reinforcement learning problems are often formulated as constrained Markov decision process (CMDP) problems, in which the agent has to maximize the expected return while satisfying a set of prescribed safety constraints. In this study, we propose a novel simulator-based method to approximately solve a CMDP problem without making any compromise on the safety constraints. We achieve this by decomposing the CMDP into a pair of MDPs; reconnaissance MDP and planning MDP. The purpose of reconnaissance MDP is to evaluate the set of actions that are safe, and the purpose of planning MDP is to maximize the return while using the actions authorized by reconnaissance MDP. RMDP can define a set of safe policies for any given set of safety constraint, and this set of safe policies can be used to solve another CMDP problem with different reward. Our method is not only computationally less demanding than the previous simulator-based approaches to CMDP, but also capable of finding a competitive reward-seeking policy in a high dimensional environment, including those involving multiple moving obstacles.