 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconnaissance and Planning algorithm for constrained MDP
Paper and Code
Sep 20, 2019
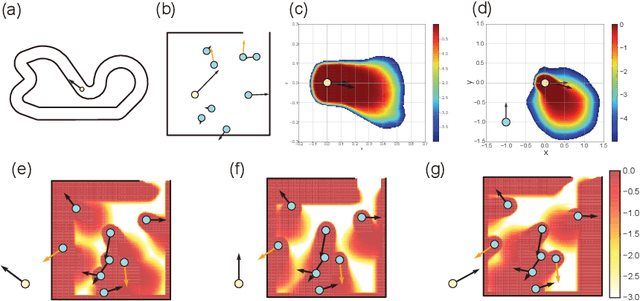

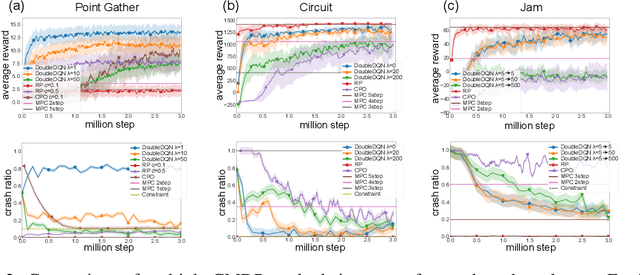
Practical reinforcement learning problems are often formulated as constrained Markov decision process (CMDP) problems, in which the agent has to maximize the expected return while satisfying a set of prescribed safety constraints. In this study, we propose a novel simulator-based method to approximately solve a CMDP problem without making any compromise on the safety constraints. We achieve this by decomposing the CMDP into a pair of MDPs; reconnaissance MDP and planning MDP. The purpose of reconnaissance MDP is to evaluate the set of actions that are safe, and the purpose of planning MDP is to maximize the return while using the actions authorized by reconnaissance MDP. RMDP can define a set of safe policies for any given set of safety constraint, and this set of safe policies can be used to solve another CMDP problem with different reward. Our method is not only computationally less demanding than the previous simulator-based approaches to CMDP, but also capable of finding a competitive reward-seeking policy in a high dimensional environment, including those involving multiple moving obstacles.