 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Discovery of Continuous Skills on a Sphere
May 25, 2023Recently, methods for learning diverse skills to generate various behaviors without external rewards have been actively studied as a form of unsupervised reinforcement learning. However, most of the existing methods learn a finite number of discrete skills, and thus the variety of behaviors that can be exhibited with the learned skills is limited. In this paper, we propose a novel method for learning potentially an infinite number of different skills, which is named discovery of continuous skills on a sphere (DISCS). In DISCS, skills are learned by maximizing mutual information between skills and states, and each skill corresponds to a continuous value on a sphere. Because the representations of skills in DISCS are continuous, infinitely diverse skills could be learned. We examine existing methods and DISCS in the MuJoCo Ant robot control environments and show that DISCS can learn much more diverse skills than the other methods.
Dropout Q-Functions for Doubly Efficient Reinforcement Learning
Oct 05, 2021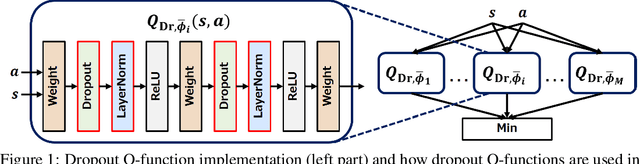
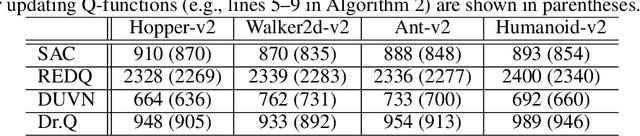
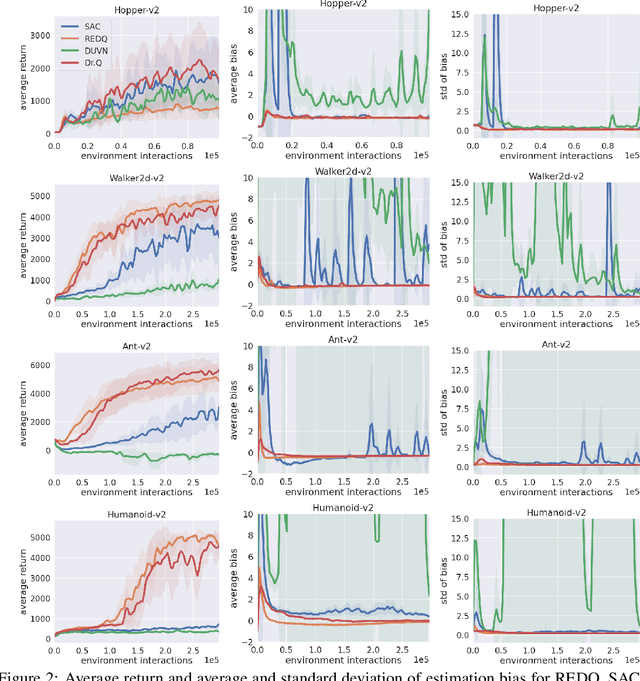
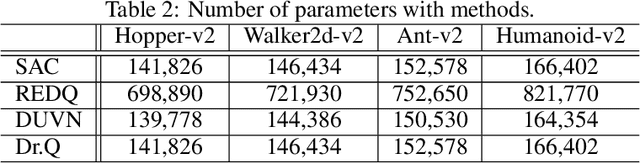
Randomized ensemble double Q-learning (REDQ) has recently achieved state-of-the-art sample efficiency on continuous-action reinforcement learning benchmarks. This superior sample efficiency is possible by using a large Q-function ensemble. However, REDQ is much less computationally efficient than non-ensemble counterparts such as Soft Actor-Critic (SAC). To make REDQ more computationally efficient, we propose a method of improving computational efficiency called Dr.Q, which is a variant of REDQ that uses a small ensemble of dropout Q-functions. Our dropout Q-functions are simple Q-functions equipped with dropout connection and layer normalization. Despite its simplicity of implementation, our experimental results indicate that Dr.Q is doubly (sample and computationally) efficient. It achieved comparable sample efficiency with REDQ and much better computational efficiency than REDQ and comparable computational efficiency with that of SAC.
Off-Policy Meta-Reinforcement Learning Based on Feature Embedding Spaces
Jan 06, 2021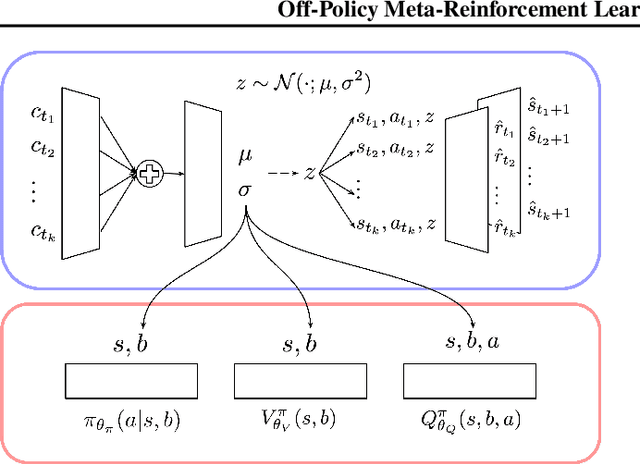
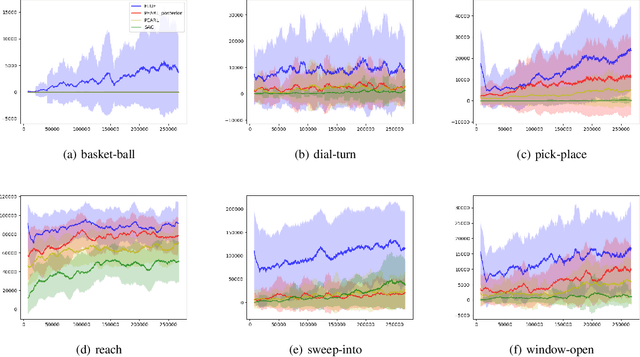
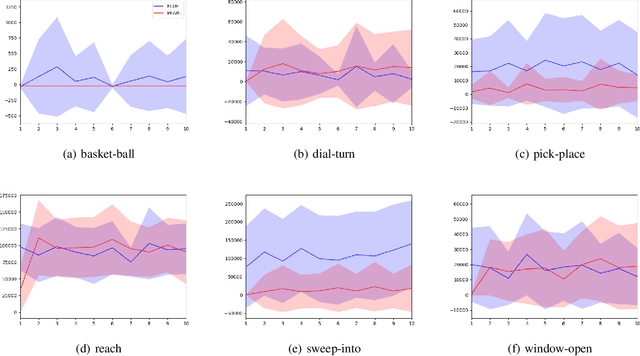
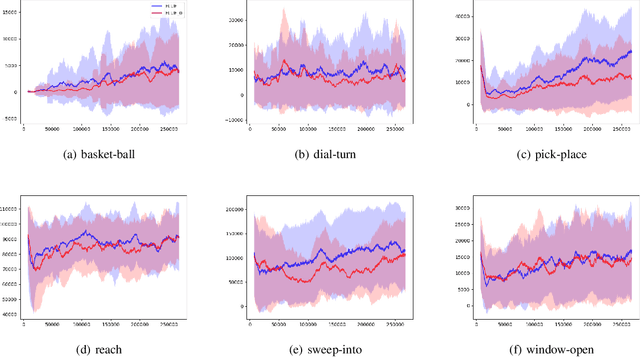
Meta-reinforcement learning (RL) addresses the problem of sample inefficiency in deep RL by using experience obtained in past tasks for a new task to be solved. However, most meta-RL methods require partially or fully on-policy data, i.e., they cannot reuse the data collected by past policies, which hinders the improvement of sample efficiency. To alleviate this problem, we propose a novel off-policy meta-RL method, embedding learning and evaluation of uncertainty (ELUE). An ELUE agent is characterized by the learning of a feature embedding space shared among tasks. It learns a belief model over the embedding space and a belief-conditional policy and Q-function. Then, for a new task, it collects data by the pretrained policy, and updates its belief based on the belief model. Thanks to the belief update, the performance can be improved with a small amount of data. In addition, it updates the parameters of the neural networks to adjust the pretrained relationships when there are enough data. We demonstrate that ELUE outperforms state-of-the-art meta RL methods through experiments on meta-RL benchmarks.
Meta-Model-Based Meta-Policy Optimization
Jun 05, 2020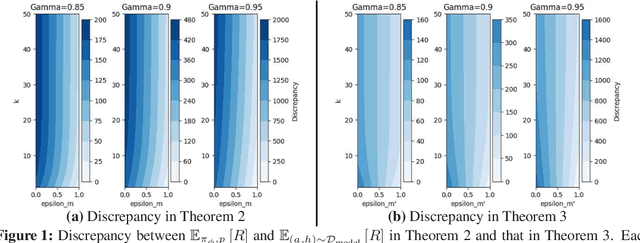
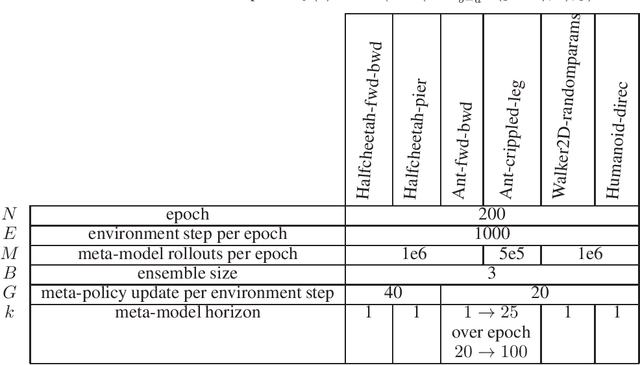
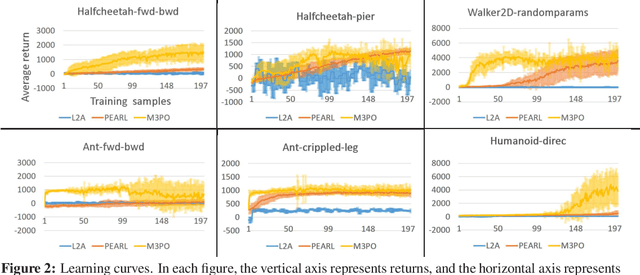
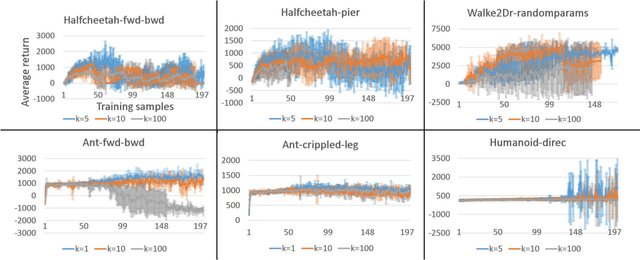
Model-based reinforcement learning (MBRL) has been applied to meta-learning settings and demonstrated its high sample efficiency. However, in previous MBRL for meta-learning settings, policies are optimized via rollouts that fully rely on a predictive model for an environment, and thus its performance in a real environment tends to degrade when the predictive model is inaccurate. In this paper, we prove that the performance degradation can be suppressed by using branched meta-rollouts. Based on this theoretical analysis, we propose meta-model-based meta-policy optimization (M3PO), in which the branched meta-rollouts are used for policy optimization. We demonstrate that M3PO outperforms existing meta reinforcement learning methods in continuous-control benchmarks.
Optimistic Proximal Policy Optimization
Jun 25, 2019
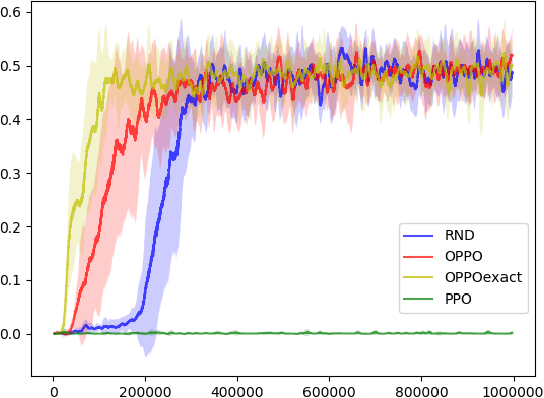
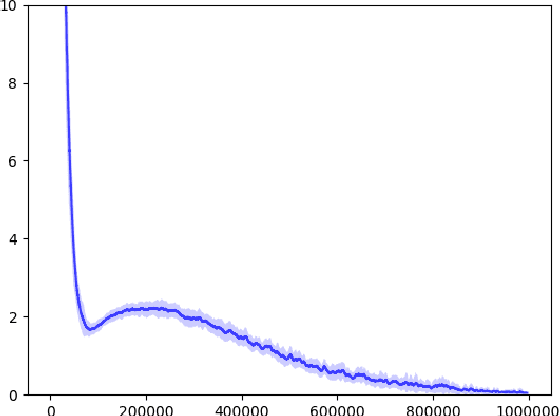
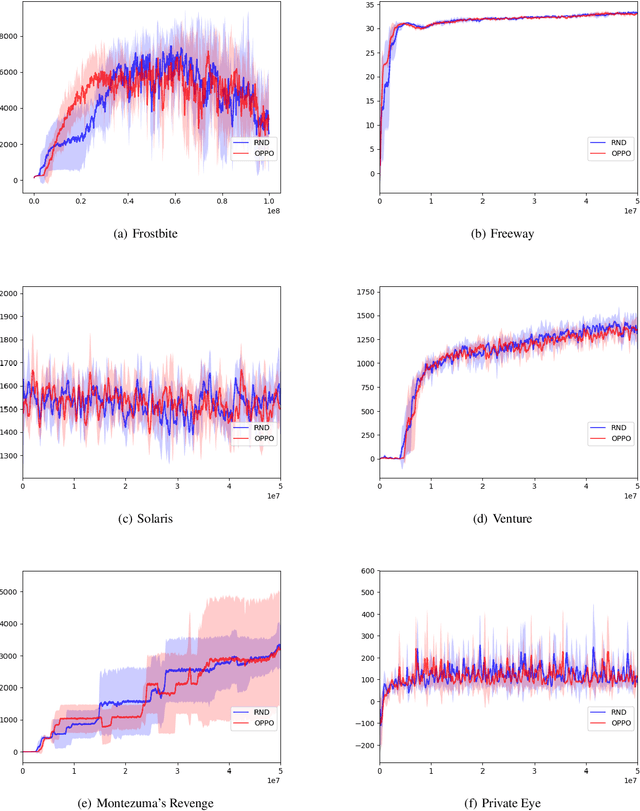
Reinforcement Learning, a machine learning framework for training an autonomous agent based on rewards, has shown outstanding results in various domains. However, it is known that learning a good policy is difficult in a domain where rewards are rare. We propose a method, optimistic proximal policy optimization (OPPO) to alleviate this difficulty. OPPO considers the uncertainty of the estimated total return and optimistically evaluates the policy based on that amount. We show that OPPO outperforms the existing methods in a tabular task.
Learning Robust Options by Conditional Value at Risk Optimization
Jun 11, 2019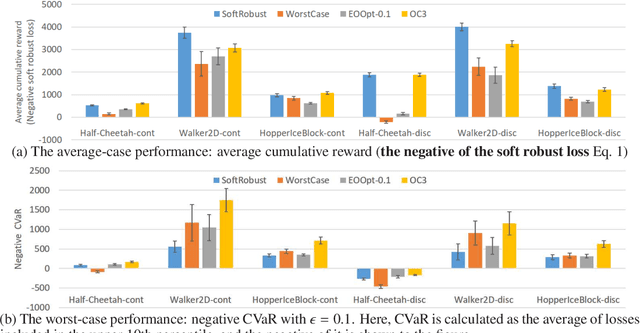
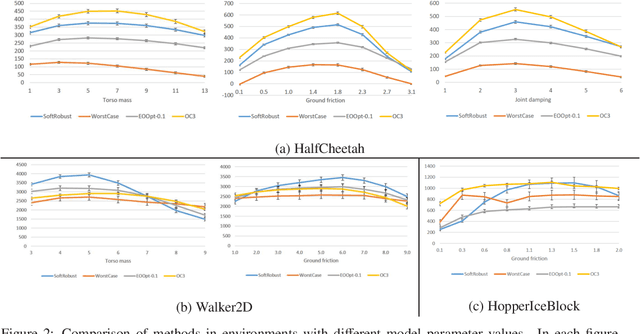
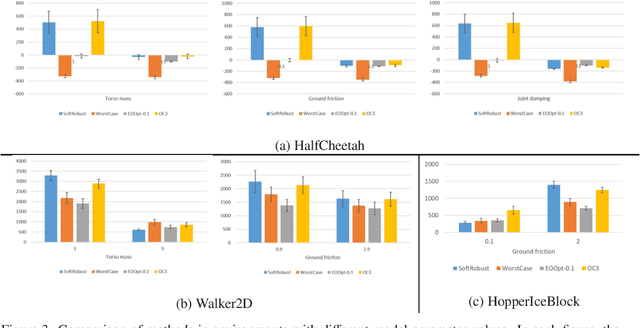
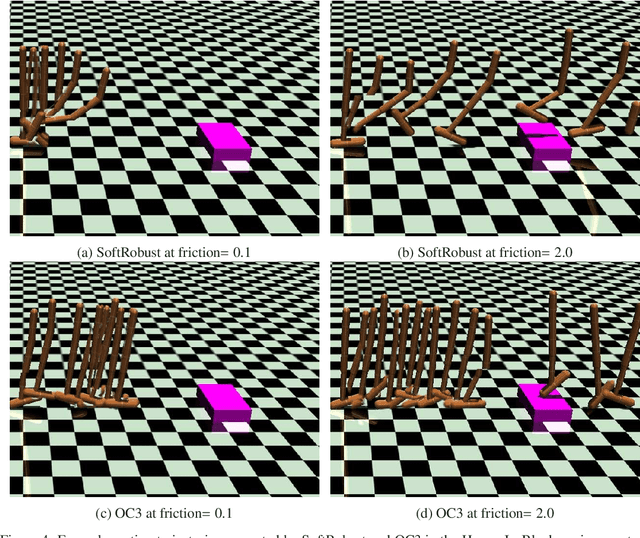
Options are generally learned by using an inaccurate environment model (or simulator), which contains uncertain model parameters. While there are several methods to learn options that are robust against the uncertainty of model parameters, these methods only consider either the worst case or the average (ordinary) case for learning options. This limited consideration of the cases often produces options that do not work well in the unconsidered case. In this paper, we propose a conditional value at risk (CVaR)-based method to learn options that work well in both the average and worst cases. We extend the CVaR-based policy gradient method proposed by Chow and Ghavamzadeh (2014) to deal with robust Markov decision processes and then apply the extended method to learning robust options. We conduct experiments to evaluate our method in multi-joint robot control tasks (HopperIceBlock, Half-Cheetah, and Walker2D). Experimental results show that our method produces options that 1) give better worst-case performance than the options learned only to minimize the average-case loss, and 2) give better average-case performance than the options learned only to minimize the worst-case loss.
Refining Manually-Designed Symbol Grounding and High-Level Planning by Policy Gradients
Sep 29, 2018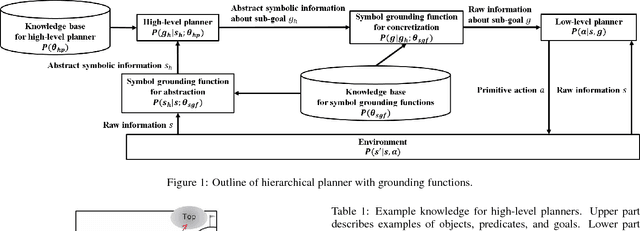
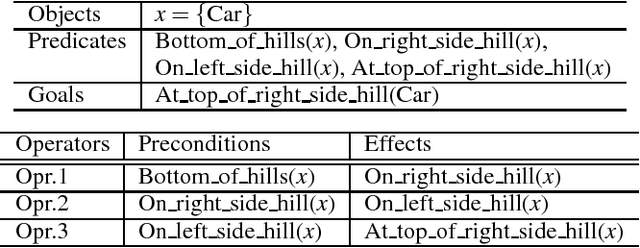

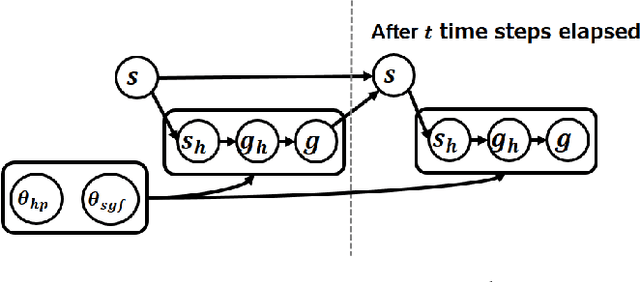
Hierarchical planners that produce interpretable and appropriate plans are desired, especially in its application to supporting human decision making. In the typical development of the hierarchical planners, higher-level planners and symbol grounding functions are manually created, and this manual creation requires much human effort. In this paper, we propose a framework that can automatically refine symbol grounding functions and a high-level planner to reduce human effort for designing these modules. In our framework, symbol grounding and high-level planning, which are based on manually-designed knowledge bases, are modeled with semi-Markov decision processes. A policy gradient method is then applied to refine the modules, in which two terms for updating the modules are considered. The first term, called a reinforcement term, contributes to updating the modules to improve the overall performance of a hierarchical planner to produce appropriate plans. The second term, called a penalty term, contributes to keeping refined modules consistent with the manually-designed original modules. Namely, it keeps the planner, which uses the refined modules, producing interpretable plans. We perform preliminary experiments to solve the Mountain car problem, and its results show that a manually-designed high-level planner and symbol grounding function were successfully refined by our framework.